
Tag Search That Scales: Why You Must Store BOTH item→tags and tag→items

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Tag Search That Scales: Why You Must Store BOTH item→tags and tag→items
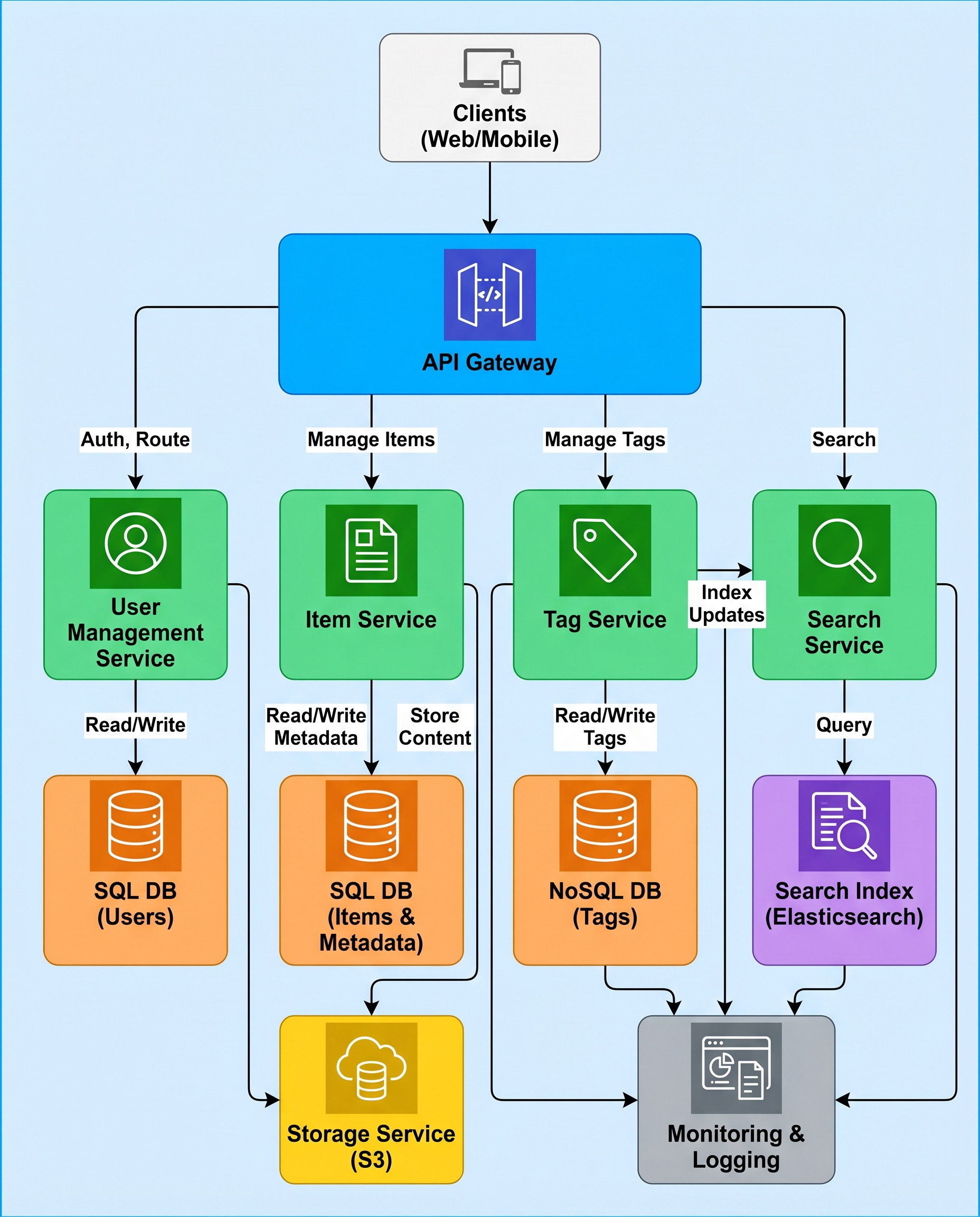
In a tagging-service interview (or design review), don’t hand-wave "search by tag." At scale, a naive approach won't meet latency or cost requirements. The key is a reverse index: you must store both the forward mapping (item → tags) and the reverse mapping (tag → items).
The problem: scanning is infeasible
If you only store item_id → [tags], searching for items with tag "cat" requires scanning every item and checking its tags. With millions or billions of items that becomes impossible to return results in a few hundred milliseconds (or even seconds).
Correct design: keep two views
Maintain two complementary data views:
- item_tags: item_id → [tags]
- Fast reads for a specific item (fetch its tags).
- tag_items: tag → [item_ids]
- Fast search by tag (fetch items that have that tag).
Example (conceptual):
item_tags:
item:123 -> ["cat", "cute"]
item:456 -> ["dog", "cute"]
tag_items:
"cat" -> [item:123, item:789, ...]
"cute" -> [item:123, item:456, ...]
This is essentially an inverted index for tags.
Writes: unavoidable duplication and write amplification
Yes — every add/remove of a tag must update both tables. That increases write amplification and storage, but it's necessary for fast reads. The real question interviewers want you to address is: how do you keep them consistent?
Consistency strategies
Pick based on the guarantees and tooling available to you.
1) Strong consistency (preferred when supported)
- Perform both updates in a single atomic transaction (ACID) if your datastore supports multi-row or multi-partition transactions.
- Example: two-row transaction in a relational DB or a transactional key-value store.
- Pros: simple correctness model, reads always consistent.
- Cons: may limit throughput or complicate distributed transactions.
2) Asynchronous eventual consistency (when transactions are impractical)
- Emit a change event to an ordered durable log (e.g., Kafka) on tag add/remove.
- A background worker consumes events and updates the tag_items view.
- Make the update idempotent and include a monotonic operation ID or version.
- Use retries with exponential backoff and dead-lettering for failures.
- Pros: higher write throughput, decouples read/write paths.
- Cons: small window of inconsistency between views.
3) Hybrid approaches
- Synchronous update of the primary view (item_tags) + fast best-effort update of tag_items, plus background reconciliation.
- Use compare-and-swap or version numbers to avoid lost updates when reconciling.
4) Reconciliation and repair
- Periodic full or incremental reconciliation jobs: scan item_tags and rebuild or check tag_items for drift.
- Maintain a change-log or vector clocks to reduce reconciliation scope.
- Track metrics (lag, failure rate) and alerts for anomalies.
Practical reliability techniques
- Make tag_items updates idempotent (set-add, set-remove semantics), so retries are safe.
- Include operation metadata (timestamp, op-id) to skip duplicates or out-of-order events.
- Use tombstones for deletes to avoid resurrection during eventual consistency windows.
- For high-cardinality tags, paginate and shard tag_items (shard by tag or by tag+bucket).
- Cache hot tags in memory (Redis) and backfill asynchronously.
Operational considerations
- Storage overhead: you store tag references twice (or more) — plan capacity accordingly.
- Latency: reading tag → items becomes O(1) (or O(shard)), so queries are fast.
- Hot tags: some tags will be very popular — shard, cache, or rate-limit queries for them.
- Sorting and paging: store timestamps or scores with item_ids (e.g., for recent-first or ranked results).
Quick interview checklist (what to say)
- Describe both views: item_tags and tag_items.
- Explain the write amplification trade-off and why it's necessary.
- Explain consistency options: atomic transactions vs async + retries + reconciliation.
- Mention idempotency, ordering, tombstones, and reconciliation jobs.
- Mention sharding, caching, and how you'd handle hot tags and pagination.
TL;DR
Do not design tag search by scanning items. Store both item→tags and tag→items. Handle the resulting write amplification explicitly: use transactions when possible or an async, idempotent event-driven pipeline with reconciliation and monitoring.
Hashtags: #SystemDesign #DataEngineering #InterviewPrep

