
Caching in System Design: The Rules Interviewers Expect You to Know

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
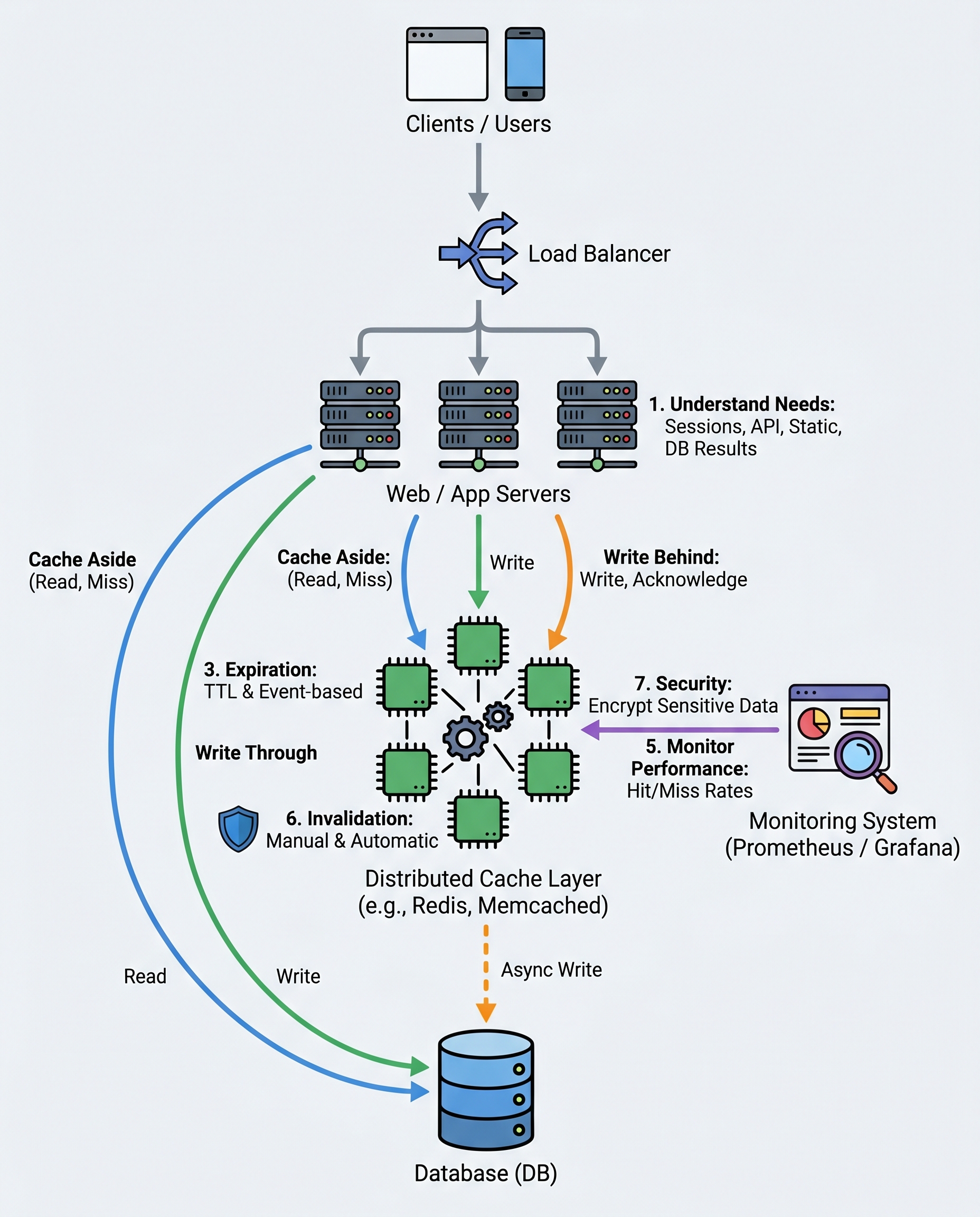
Quick primer interviewers expect: caching is a design decision, not a "add Redis and pray" tactic. Know what to cache, which strategy to use, how to expire and invalidate, and how to monitor.
What to cache (start here)
- Sessions and authentication tokens (if safe to cache).
- API responses for idempotent or read-heavy endpoints.
- Static assets (images, JS, CSS) and CDN-cached content.
- "Hot" query results and aggregated counters (e.g., leaderboards, dashboards).
Pick the smallest surface area that gives measurable latency or load reduction.
Popular caching strategies (and when to name-drop them in interviews)
Cache-Aside (Lazy Loading)
- Flow: application checks cache -> if miss, load from DB -> write to cache -> return.
- Pros: simple, widely used, flexible invalidation.
- Cons: cache warm-up on misses; potential stale reads between DB write and cache update.
Write-Through
- Flow: writes go to cache, cache synchronously writes to DB.
- Pros: strong read-after-write consistency for cached keys.
- Cons: higher write latency because every write persists synchronously.
Write-Behind (Write-Back)
- Flow: write acknowledged when written to cache; cache asynchronously flushes to DB.
- Pros: very low write latency.
- Cons: risk of data loss if cache node dies before flush; complexity in retry/ordering.
When discussing, mention trade-offs: consistency vs latency vs complexity.
TTL and invalidation — do not rely on TTL alone
- Always set a sensible TTL (time-to-live) to bound staleness and memory usage.
- Use event-based invalidation when the origin of truth changes (e.g., after a write, invalidate related keys).
- Consider patterns to avoid race conditions and stampedes:
- Cache stampede mitigation: request coalescing, mutexes, or pre-warming.
- Stale-while-revalidate: serve slightly stale data while refreshing in background.
- Use versioned keys (key:v2) to make invalidation atomic.
Distributed cache for multi-instance apps
- Use Redis or Memcached (or cloud-managed equivalents) when you have multiple application instances.
- Choose Redis for advanced features (persistence, replication, data structures, Lua scripting).
- Be mindful of network latency, sharding, and capacity planning.
Monitor and tune
Track these metrics and tune accordingly:
- Hit rate and miss rate (target higher hit rate for the most important keys).
- Eviction rate (indicates insufficient memory or poor key sizing).
- Cache latency (network + serialization costs).
- Thundering herd occurrences and stampede events.
Use dashboards and alerts to detect regressions after deployments.
What not to cache / pitfalls
- Never cache sensitive data (full credit card numbers, secrets, PII) unless encrypted and justified.
- Avoid caching large unbounded collections; prefer paginated or summarized views.
- Watch serialization cost: expensive (de)serialization can negate latency gains.
- Remember cache consistency semantics — eventual consistency may be fine for read-mostly data, but not for critical transactional flows.
Interview checklist — succinct talking points
- Name what you'd cache and why (sessions, hot queries, static assets).
- Choose a strategy and justify trade-offs (cache-aside for simplicity, write-through for strong consistency, write-behind for throughput).
- Explain TTL + event-based invalidation and how you'd prevent stampedes.
- Mention distributed cache choices (Redis vs Memcached) and monitoring metrics.
- Call out security: don’t cache sensitive data.
Short example: cache-aside pseudocode
# read flow
value = cache.get(key)
if not value:
value = db.read(key)
cache.set(key, value, ttl=60)
return value
# write flow (simple invalidation)
db.write(key, new_value)
cache.delete(key) # or update cache atomically
Keep answers concrete in interviews: quantify expected reductions (e.g., reduce DB read load by X%, drop p95 latency from Y->Z ms) and mention monitoring you’d add to validate the change.
#SystemDesign #SoftwareEngineering #Backend

