
Caching in System Design: The Rules Interviewers Expect You to Know

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
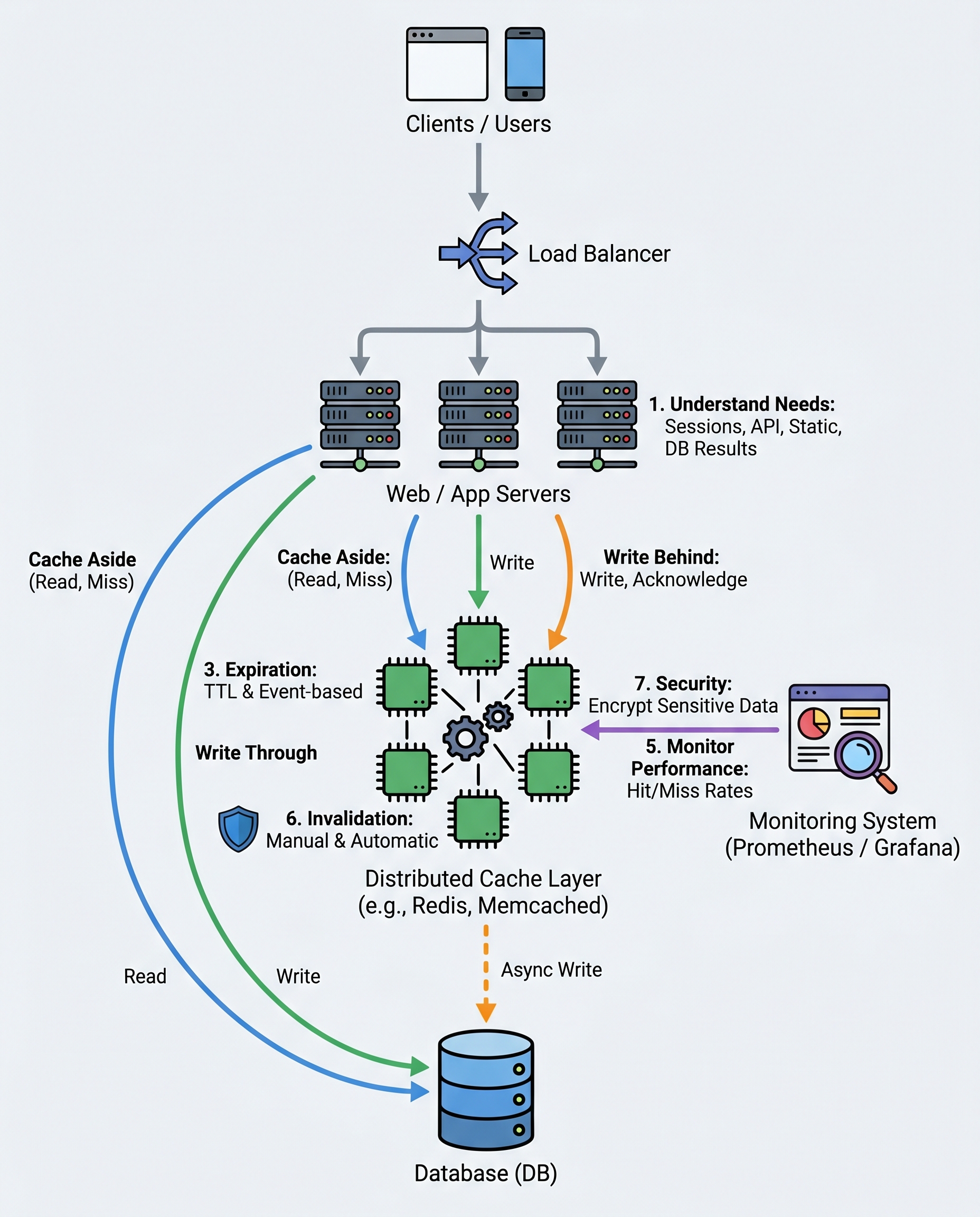
Caching is not "add Redis and pray." In interviews you should be able to explain what to cache, which strategy to pick, how to invalidate, and how to operate a distributed cache safely.
Quick summary
Caching improves read performance, reduces backend load, and lowers latency — but it adds complexity (consistency, invalidation, memory management). In interviews, show you understand trade-offs and operational concerns, not just the buzzwords.
What to cache (start here)
- Sessions and authentication tokens (careful with sensitive data)
- API responses for idempotent or read-heavy endpoints
- Static assets and CDN-cachable content (images, JS, CSS)
- Hot query results or aggregated data (expensive DB queries)
- Configuration and feature flags for fast lookup
Aim for data that is read frequently and either immutable or tolerates short staleness.
Common caching patterns (when to use each)
Cache-Aside (lazy loading)
- Flow: application checks cache → on miss load from DB → populate cache
- Pros: simple, common, works well when writes are infrequent
- Cons: cold-start misses, possible short-lived inconsistency immediately after writes
Write-Through
- Flow: application writes to cache and backing store synchronously
- Pros: stronger read consistency, simpler invalidation
- Cons: write latency increases (slower writes)
Write-Behind (Asynchronous write-back)
- Flow: write returns after updating cache; updates to persistent store happen asynchronously
- Pros: very fast writes from client perspective
- Cons: risk of data loss if cache node fails before write-back; more complex error handling
Choose based on your consistency needs, latency requirements, and failure tolerance.
Expiration and invalidation
- Always set TTLs (time-to-live). TTL prevents stale data accumulation and controls memory usage.
- Combine TTL with event-based invalidation for stronger correctness when data changes.
- Avoid relying on TTL alone for frequently-updated data.
- Invalidation strategies:
- Explicit delete on update (application issues cache.delete(key))
- Versioned keys (include object version or timestamp in the key)
- Publish/Subscribe for cache invalidation across instances (e.g., Redis Pub/Sub)
Avoiding cache stampedes
When a popular key expires, many requests may hit the DB at once. Mitigations:
- Locking / request coalescing (only one request refreshes the cache)
- Probabilistic early refresh (refresh slightly before TTL expires)
- Stale-while-revalidate: serve stale value while asynchronously refreshing
- Jittered TTLs to avoid synchronized expirations
Distributed cache considerations
- Use Redis or Memcached for multi-instance apps. Redis offers richer data types, persistence, and pub/sub; Memcached is simple and fast for plain key/value.
- Partitioning and sharding: split keys across nodes to scale memory and throughput.
- Replication and persistence: choose based on durability requirements (Redis AOF/RDB vs. ephemeral cache)
- Eviction policy: LRU (Least Recently Used) is common — monitor evictions to tune memory or TTLs
- Network latency: keep cache close to application (same region/zone) to avoid adding network overhead
Monitoring and operational metrics
Track and act on these metrics:
- Hit rate and miss rate (percent of reads served from cache)
- Latency for cache operations
- Evictions per second and memory usage
- Key count and key sizes
- Error rates and network retries
Tune based on observed metrics (increase memory, change TTLs, change eviction policy, or shard more).
Safety and security
- Never cache sensitive data (plain-text PII, secrets) unless encrypted and approved by security requirements.
- Be careful with authorization: do not cache responses that vary per-user unless the cache key includes user identity and invalidation is handled.
- Limit object sizes and total cached data to avoid memory blowups.
Practical interview checklist
When asked about caching in a system-design interview, mention:
- What you’ll cache and why (read-heavy, expensive, or static)
- The caching pattern you’ll use and trade-offs
- TTL and invalidation strategy (TTL + event-based invalidation)
- How to handle cache stampedes and stale data
- Choice of cache technology (Redis vs Memcached) and sharding/replication plan
- Monitoring metrics and how you’ll tune the cache
- Security considerations (don’t cache secrets)
Short example (pseudo flow)
- Client requests user profile → app checks cache (key: user:123)
- If cache hit → return cached profile
- If miss → query DB, populate cache with TTL, return result
- On profile update → write to DB; then invalidate or update cache (or use versioned key)
Final notes
Caching yields big performance wins, but interviewers want to hear about correctness and operation as much as latency numbers. Explain your pattern choice, how you’ll invalidate and monitor the cache, and how you’ll recover from failures.
Good talking points: cache keys, TTL strategy, stampede mitigation, distributed deployment, and metrics — those show you understand both design and operations.

