
System Design Key Points: Log Collection and Analytic System
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
This is a high-frequency system design problem, often encountered in interviews and practical scenarios. The design revolves around data processing and follows classic patterns that can be applied across various use cases.
As you can see, this solution divided the system into different phrases:
- Data Ingestion
- Data Validation
- Data Storage
- Data Serving
Key point as following:
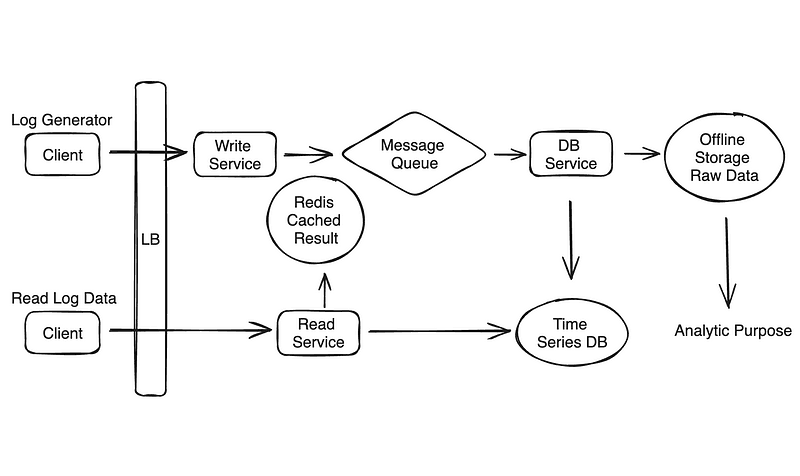
Simple System Design Diagram — Design a Log Collection and Analysis System
Data Ingestion
Efficient ingestion ensures all logs are captured and processed promptly without loss or bottlenecks.
Real-time vs. Batch Processing
Real-time Processing:
- Use message brokers (e.g., Kafka, Pulsar) as a durable, high-throughput buffer between log producers and consumers.
- Stream Processors: Tools like Flink, Storm, or Spark Streaming should support:
- Windowing:
- - Tumbling Windows: Fixed intervals (e.g., 5 seconds) for aggregation.
- - Sliding Windows: Overlapping intervals for finer-grained insights.
- - Session Windows: Dynamically bounded intervals based on activity gaps.
- Stateful Processing: Manage intermediate state in memory for event counts or aggregations.
- Event Deduplication: Use unique IDs or timestamps to discard duplicate events during processing.
Batch Processing:
- Use Spark or Hadoop for high-throughput log aggregation over larger intervals.
- Store raw logs in optimized formats for:
- - Schema evolution.
- - Compression.
- - Fast sequential reads during processing.
- Implement idempotency by appending processed logs with markers to prevent double-processing.
Hybrid Approach:
- Split pipelines:
- Real-time streaming for high-priority metrics (e.g., error rates, latencies).
- Batch pipelines for historical analysis, trend modeling, and cost-optimized data processing.
Data Validation
Validating incoming data maintains system integrity and reliability.
Data Cleaning:
- Implement hash-based deduplication:
- - Generate and compare hash signatures (e.g., SHA256) of log entries.
- - Store recently processed hashes in memory with time-based eviction.
Outlier Detection:
- - Use statistical models (e.g., z-score, IQR) or machine learning for identifying anomalous log entries in real-time pipelines.
- - Flag incomplete or unusually structured logs.
Schema Validation:
- Use JSON Schema libraries or Protobuf for:
- Verifying log attributes.
- Ensuring compatibility with downstream processing requirements.
- Log invalid entries in a separate stream or storage for debugging.
Monitoring:
- Employ adaptive sampling to periodically validate logs against expected patterns.
- Configure data volume anomaly detection using thresholds or machine learning models to detect sudden spikes or drops.
Scalability and Performance
A scalable system ensures seamless handling of increasing data volumes, while performance tuning minimizes latency.
Horizontal Scaling
- Sharding: Distribute logs based on hash keys (e.g., tenant ID, region) to maintain even load distribution.
- Replication: Use strategies like quorum-based replication to enhance fault tolerance without overloading storage.
Microservices Architecture:
- Separate services for ingestion, validation, storage, querying, and analysis.
- Use event-based communication (e.g., Kafka, gRPC) to maintain loose coupling.
Load Balancing:
- Use consistent hashing to ensure stable log distribution across nodes.
- Apply weighted round-robin for heterogeneous servers with different processing capacities.
Throughput and Latency
Caching:
- Implement write-through caching for frequent writes (e.g., Redis or Memcached).
- Use read-through caching to optimize repeated queries during analytics.
Asynchronous Processing:
- Design ingestion pipelines with backpressure mechanisms to slow producers during high load (e.g., Kafka’s consumer lag monitoring).
Data Storage
Efficient data storage ensures logs are durable, accessible, and cost-optimized.
Storage Solutions:
- Relational Databases:
- - Use partitioning and indexing for query optimization.
- - Store metadata (e.g., log origins, timestamps) alongside log data for efficient querying.
- NoSQL Databases:
- - Design wide-column models for logs, with row keys as concatenated identifiers (e.g.,
serviceID-timestamp). - - Implement TTL policies to automatically expire old logs.
- Time-Series Databases:
- - Optimize for time-stamped log data with downsampling (e.g., average hourly metrics) to manage storage growth.
- Cold Storage:
- - Archive older, rarely accessed logs in compressed formats (e.g., ORC, Snappy) or object storage systems (e.g., Amazon S3).
Data Retention Policies:
- Categorize logs based on criticality:
- High-priority logs: Retain for extended periods.
- Non-critical logs: Move to archive or delete after predefined intervals.
Data Query and Analysis
Efficient querying and analysis are key to deriving actionable insights from logs.
Server Processes Data for Analysis
Pre-aggregation:
- Perform real-time aggregation (e.g., counts, averages) in memory during ingestion for frequently queried metrics.
- Maintain aggregated rollups (e.g., hourly/daily metrics) in a separate table for performance.
Data Partitioning and Indexing:
- Partition logs based on time intervals and relevant keys (e.g., service ID).
- Implement secondary indexes for frequently queried fields (e.g., error codes).
Query Execution:
- Design a query layer with:
- - Push-down filters: Execute filters at the storage layer to minimize data transfer.
- - Parallel query execution: Leverage distributed storage engines for concurrent processing.
- Optimize query plans using query optimizers (e.g., Apache Calcite).
Serving Queries:
- Indexing Strategies:
- - Use inverted indexes for full-text searches in Elasticsearch.
- - Optimize time-based queries with time-bucketed indexes.
- Query Caching:
- - Cache frequent query results in memory to reduce storage reads.
- - Use cache invalidation policies to update stale results.
- API Gateways:
- - Employ API gateways to serve user requests with:
- - Rate limiting to prevent abuse.
- - Query pagination for large datasets.

System Design Score — Design a Log Collection and Analysis System

