
System Design Interview with a Meta Staff Engineer: Designing a Task Scheduler
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Recently, I had the opportunity to participate in a mock system design interview with an E6 Staff Engineer from Meta. The topic was designing a Task Scheduler — a relatively simple problem meant to ease him back into the rhythm of technical interviews after years of not participating in the job-hopping scene.
Despite this, his strong fundamentals and sharp thought process were clearly evident, as he covered most of the key aspects of the problem.
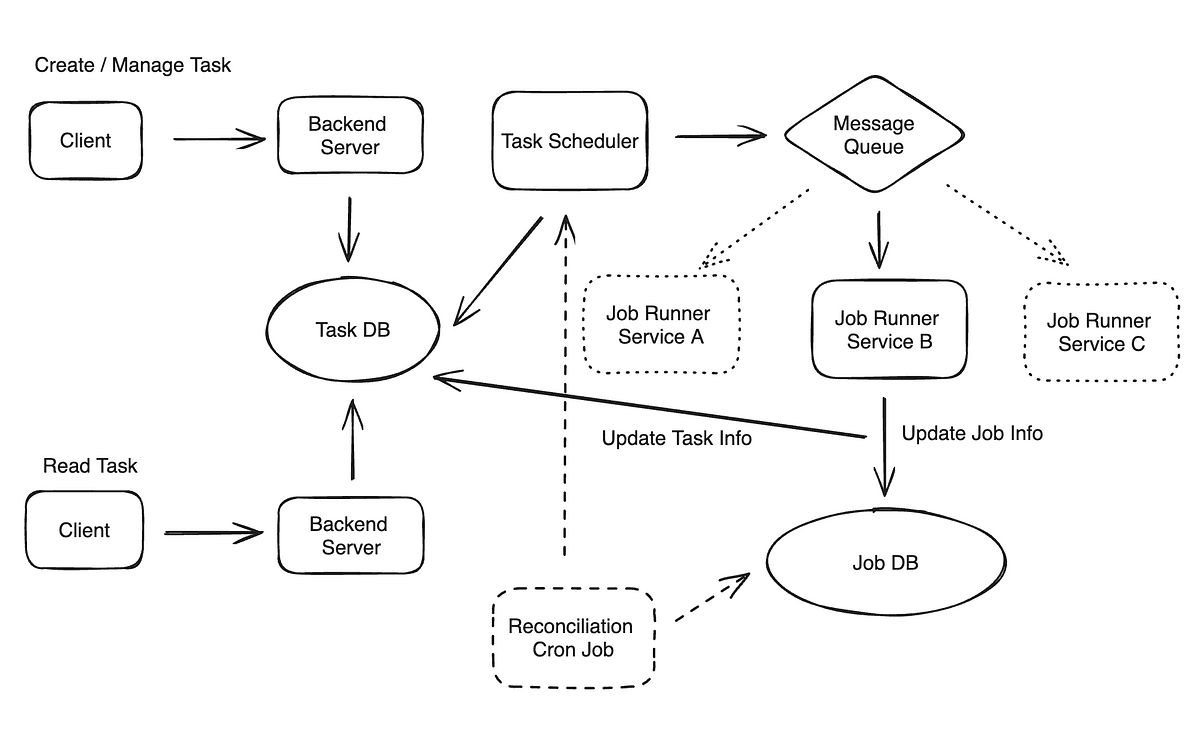
Design Task Scheduler — Systme Design Diagram
Key Points as followings:
1. Requirements Discussion
The first step in system design is to thoroughly understand the requirements. We started by discussing what types of tasks the scheduler needed to support. Key questions included:
- Task Type: Will the system handle periodic tasks (e.g., recurring jobs) or ad-hoc tasks (e.g., one-off executions)?
- Resource Constraints: What resources are required to execute a task? This includes runtime duration, network bandwidth, CPU consumption, etc.
- Optimization Targets: Which part of the system needs optimization? Should we focus on minimizing latency, maximizing throughput, or ensuring resource fairness across tasks?
This discussion laid the foundation for designing a system that could adapt to both simple and complex task requirements.
2. Scalability
Scalability is a crucial aspect of any modern system design, especially for something like a task scheduler that must handle a potentially massive and unpredictable workload.
Parallel Task Processing with Message Queues:
One of the first ideas we discussed was using a message queue (e.g., Kafka, RabbitMQ, or AWS SQS) to decouple task production from task execution. By enqueueing tasks, the scheduler can distribute them across multiple worker nodes, enabling parallel processing and preventing bottlenecks.
Handling Complex Tasks:
Another challenge arises when tasks vary in complexity. If a single task consumes disproportionate resources or takes too long to execute, it could block other tasks from running.
To address this, we explored solutions like:
- Using priority queues to prioritize smaller, faster tasks.
- Sharding tasks by type or resource requirements to ensure that complex tasks are isolated from simpler ones.
- Implementing dynamic worker scaling so that more workers can be spun up when a burst of heavy tasks is detected.
3. Failure Tolerance
No system is perfect, so designing for failure tolerance is critical to ensure reliability. We discussed several strategies to handle task failures effectively:
Failure Detection and User Notification:
When a task fails, the system should log the failure and notify the user promptly. This could be achieved through a combination of monitoring tools (e.g., Prometheus) and alerting systems (e.g., PagerDuty, Slack notifications).
Task Retry Mechanism:
For transient failures (e.g., network issues or temporary resource unavailability), the scheduler should retry the task a configurable number of times. To avoid overloading the system, retries should follow an exponential backoff strategy.
Handling Persistent Failures:
If a task continues to fail after multiple retries, the system needs a way to escalate or quarantine it. Potential solutions include:
- Providing detailed failure logs to help users diagnose the issue.
- Allowing users to reschedule or cancel failed tasks manually.

Answer of Designing Task Scheduler

