
News Feed Recommender in Interviews: The 5 Parts You Must Explain Clearly

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
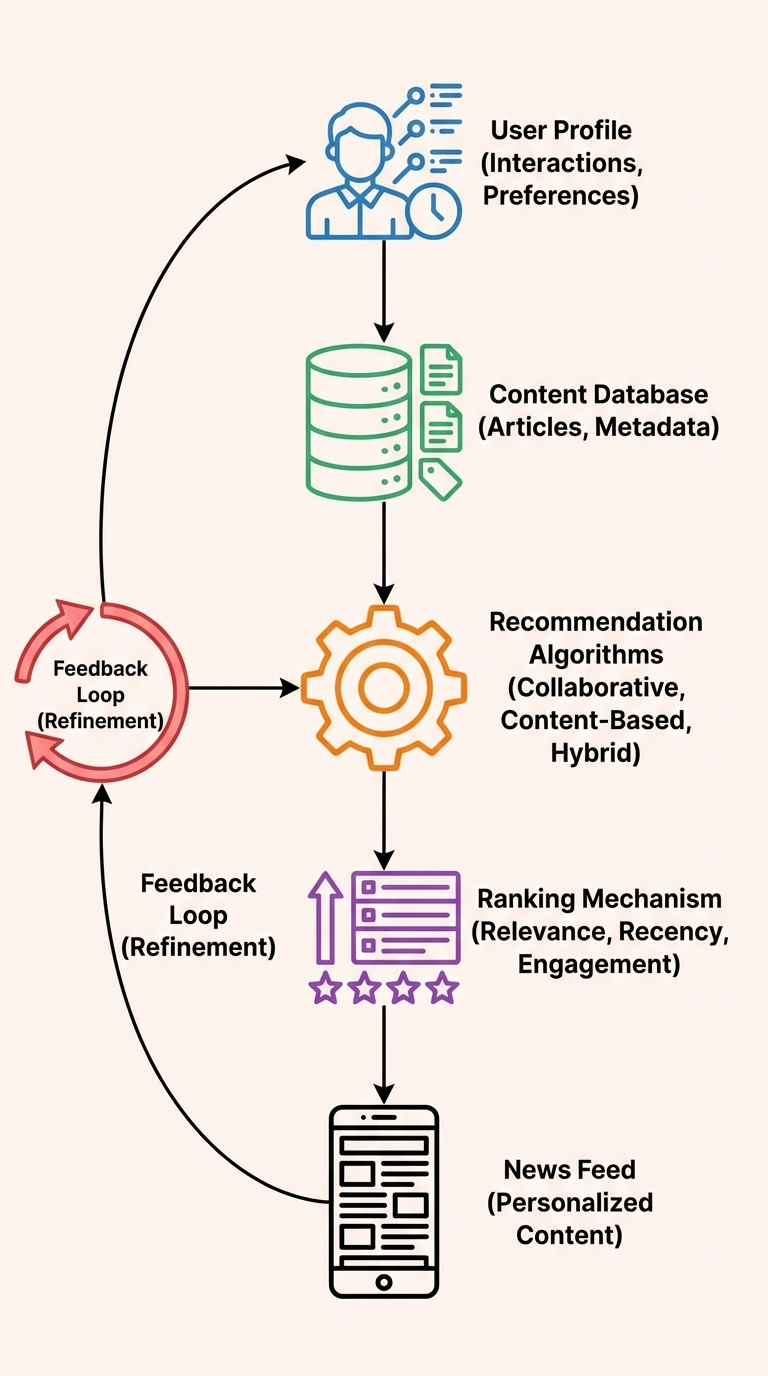
News Feed Recommender in Interviews: The 5 Parts You Must Explain Clearly
A news feed recommender's goal is simple to state but rich in detail: personalize the feed so each user sees the most relevant, fresh content. In interviews, hiring managers expect a clear, structured answer. Use the five-part breakdown below — it maps to product, data, models, infrastructure, and ops — and add privacy, training, integration, and monitoring to show production-readiness.
Start with a 20–30 second elevator pitch, then walk through each part clearly.
1) User profile — what drives personalization
Explain what you store and why it matters:
- Signals: explicit likes, follows, shares; implicit signals such as clicks, dwell time, scroll depth, and time-of-day.
- Representation: short-term session features (recent interactions) and long-term user embedding (interests, demographics, subscribed topics).
- Freshness: recent actions often weigh more (recency window for session features).
- Interview talking points: mention sparsity handling, cold-start (new users), and privacy-aware feature selection.
Example phrase: “We combine short-term session features and long-term user embeddings to capture both intent and stable preferences.”
2) Content store — what you recommend from
Clarify what an item is and what metadata you keep:
- Items: article, video, post, or ad; include canonical id, author, topic tags, timestamp, language, length/type.
- Metadata: topic taxonomy, popularity signals (views, likes), recency, and derived embeddings (e.g., text or image vectors).
- Filtering: content eligibility (policy, geo, language), freshness thresholds, and deduplication.
Interview tip: describe how you would keep the content store indexed for fast retrieval and how you would handle expired or stale items.
3) Algorithms — how you generate candidates
Outline candidate generation and the algorithm family choices:
- Candidate generation types:
- Collaborative filtering (user-item interactions matrix, nearest neighbors)
- Content-based (item features or embeddings; text/image similarity)
- Hybrid (combines both; often via late or early fusion)
- Retrieval methods: approximate nearest neighbors (ANN) on embeddings, popularity-based seeding, and graph-based recommendations.
- Trade-offs: CF captures collective patterns but needs interaction data; content-based works for cold start but may be less diverse.
Interview tip: briefly justify your choice for a news feed (usually hybrid for freshness and personalization).
4) Ranking — predict interaction and balance objectives
Explain how you score and order candidate items:
- Objective: maximize some expected user utility (CTR, dwell time, shares) while incorporating recency and business constraints.
- Models: pointwise (predict probability of click), pairwise (rank loss), or listwise approaches; modern systems often use neural models combining user and item embeddings plus contextual features.
- Business rules & trade-offs: inject recency boost, diversity/novelty penalties, business/promoted content quotas, and fairness constraints.
- Real-time features: session context, time-of-day, and freshness signals applied at rank-time.
Example phrase: “The ranker predicts engagement probability, then we re-rank with recency and business constraints to balance relevance and freshness.”
5) Feedback loop — learn from new behavior
Describe how the system improves over time:
- Signals: implicit feedback (clicks, dwell) and explicit feedback (likes, reports).
- Online learning vs. periodic retraining: online updates for fast personalization; batch retraining for stability and complex models.
- Exploration: epsilon-greedy, contextual bandits, or randomized exploration to collect unbiased data and avoid overfitting to historical biases.
- Instrumentation: log impressions, exposures, and downstream engagement for causal evaluation.
Interview tip: mention how you avoid feedback loop traps (popularity bias, echo chambers) via exploration and debiasing.
Production considerations: data, training, integration, and monitoring
Data collection & privacy:
- Collect minimal, purposeful signals and respect consent/GDPR (anonymize PII, enable opt-out).
- Explain how you store sensitive features (hashed IDs, differential privacy if required).
Training & validation:
- Offline metrics: AUC, NDCG, MRR for rankers; calibration for probability estimates.
- Validation approach: time-split validation to respect temporal leakage; simulate production by using recent data windows.
- A/B testing: measure online lift on CTR, dwell time, retention, or business KPIs.
Integration & latency:
- Architecture: candidate generation service (fast ANN + popularity seeds), ranking service (low-latency model inference), and feature store for precomputed features.
- Latency budget: rank-time should meet strict SLOs (e.g., 50–200 ms) — trade off model complexity vs. latency.
Monitoring & metrics:
- Core metrics: CTR, long-click rate, dwell time, session length, retention, and DAU/MAU.
- Quality & safety: content policy violations, filter precision, and user-reported issues.
- Model drift: input distribution drift, feature availability alerts, and shadow testing for new models.
Quick interview answer structure (30–60s + deep dive)
- One-line summary: “A news feed recommender personalizes and orders content to maximize user value while keeping content fresh and safe.”
- High-level architecture: user profile → candidate generator → ranker → serve → feedback loop.
- Deep dive: pick 2–3 parts (e.g., ranking and feedback loop) and explain features, model choice, and metrics.
- Cross-cutting concerns: privacy, validation, latency, and monitoring.
Example soundbite you can use
“In production I’d use a hybrid retrieval (ANN on item embeddings + popularity seeds), a neural ranking model predicting engagement, a recency/diversity re-ranker, and an online feedback loop with controlled exploration and rigorous A/B testing.”
Closing note: keep your explanation structured and pragmatic. Interviewers want to hear how you think about trade-offs (freshness vs. relevance, latency vs. model complexity, personalization vs. privacy) and how you'd validate changes in production.
Good luck — and prepare a concise 30–60s pitch plus a deeper 3–5 minute walkthrough that maps to the five parts above.

