
Meta Senior Eng System Design Interview: Designing Facebook’s Search System
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
This interview is from an Engineer who joined Meta during the Facebook period. And the system design question is Design the Facvebook Search System.
Here are some of the key points for discussion
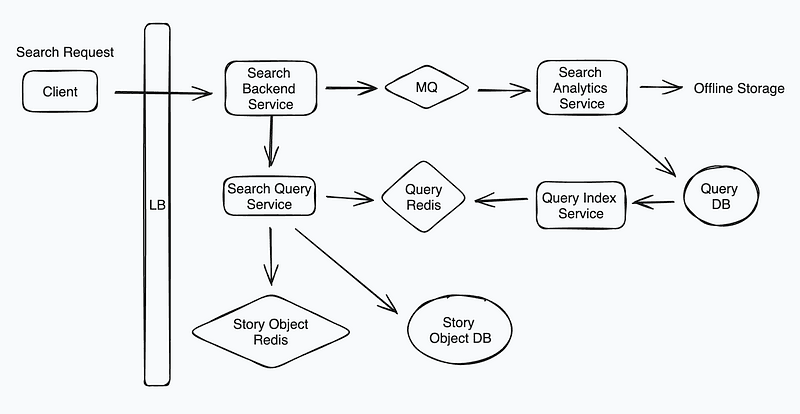
System Design Diagram — Design Facebook Search
Data Collection & Indexing
Data Sources
How do we gather data from diverse sources like user-generated content, pages, groups, and events?
Designing a search system for Facebook necessitates a comprehensive approach to data collection. The platform hosts a plethora of content types, each requiring a unique method of data extraction:
1. User-Generated Content: This includes posts, comments, and media shared by users. Efficient APIs are needed to capture this data in real-time while ensuring minimal latency and system overhead. Handling multimedia content, privacy settings, and structured/unstructured text.
- Solution: Event-driven architectures utilizing message queues (e.g., Kafka) to process new content as it is created.
2. Pages and Groups: These are community-driven spaces with their own content dynamics. A separate indexing strategy might be required to handle their unique data structures. Pages and groups often generate high-volume discussions that need different prioritization techniques.
- Solution: Hierarchical indexing based on entity type and relevance.
3. Events: Time-sensitive data that must be indexed with priority to ensure users can access relevant information promptly. Event lifecycle management (e.g., upcoming vs. past events).
- Solution: Time-window-based indexing where upcoming events are prioritized.
Handling Real-Time and Historical Data
Integrating real-time data streams with historical data is crucial for maintaining a comprehensive search index. Techniques such as stream processing and batch processing can be employed:
- Stream Processing: Tools like Apache Kafka and Flink can be utilized to handle real-time data ingestion, ensuring that new content is indexed promptly without waiting for batch cycles.
- Batch Processing: Historical data can be processed in batches using frameworks like Apache Hadoop or Spark, allowing for efficient data management and storage. This ensures that older content remains searchable without overloading real-time systems.
Indexing Strategy
How do we design an efficient indexing mechanism to support rapid searches?
An effective indexing strategy is pivotal for a high-performance search system. Considerations include:
- Inverted Indexing: Maintains a mapping from keywords to content locations, allowing for quick retrieval. This is a standard technique used in full-text search engines like Elasticsearch.
Data Structures:
- B-trees: Useful for range-based queries and efficiently balancing reads/writes.
- Tries: Helpful for auto-complete and prefix matching.
- Bloom Filters: Used to check for data existence quickly before performing expensive lookups.
Ensuring Data Freshness
Maintaining the freshness of indexed data is essential for providing users with up-to-date search results. Techniques such as incremental updates can be implemented:
- Incremental Updates: Instead of re-indexing the entire dataset, only the changed data is updated, reducing processing time and resource usage.
- Real-Time Merging: Hybrid approaches where updates are continuously merged into existing indexes while larger re-indexing jobs run in the background.
Search Relevance & Ranking
Relevance Algorithm
How do we design a search algorithm to ensure result relevance?
Relevance is the cornerstone of a successful search system. Algorithms should consider:
User Behavior Data: Incorporating user interactions like clicks, likes, and shares can personalize search results.
Natural Language Processing (NLP):
- Query Understanding: Tokenization, stemming, and entity recognition.
- Semantic Search: Using word embeddings (e.g., Word2Vec, BERT) to improve result matching.
Ranking Factors
What factors influence the ranking of search results?
Balancing various factors is crucial for effective ranking:
- Content Freshness: Newer content might be more relevant in certain contexts.
- User Relationship Strength: Content from closer connections might be prioritized.
- Content Quality: Engagement metrics such as shares, comments, and reactions can serve as a proxy for quality.
Machine Learning for Search Optimization
Should machine learning models be introduced to optimize search relevance and ranking?
Machine learning can significantly enhance search relevance:
- Predictive Models: Using collaborative filtering and reinforcement learning to anticipate user intent.
- Continuous Learning: Implementing an A/B testing framework to fine-tune ranking algorithms based on user interactions.
Scalability & Performance
High Availability
How do we design the system to ensure high availability?
Distributed Systems:
- Sharding: Horizontal partitioning of the index to distribute the load and improve query performance.
- Replication: Creating multiple copies of data across geographically distributed servers to ensure redundancy and resilience against failures.
- Redundancy: Having failover mechanisms where secondary servers can take over if primary nodes fail. Leader-follower models can help maintain consistency during failovers.
- Consensus Mechanisms: Using protocols like Raft or Paxos to maintain consistency across distributed nodes and prevent data loss.
Latency Optimization
How do we optimize the response time of search requests?
Reducing latency is key to a smooth user experience:
Caching Mechanisms:
- Edge Caching: Storing popular queries at CDN edges for ultra-fast retrieval, reducing round-trip time.
- Memory Caching: Using Redis or Memcached to store frequently queried data and reduce database hits.
Load Balancing:
- Round-Robin: Distributes requests evenly across servers, ensuring no single node is overloaded.
- Least Connections: Sends requests to the server with the fewest active connections, optimizing for resource utilization.
- Geolocation-Based Routing: Directs users to the nearest data center, reducing latency caused by long-distance data transmission.
Index Optimization:
- Partitioning Strategies: Efficient partitioning of search indexes based on geographic, content category, or user segmentation for reduced search scope.
- Parallel Query Execution: Running queries across multiple partitions simultaneously to enhance performance.
Scaling Strategies
- Horizontal Scaling: Adding more servers to distribute the load instead of upgrading individual servers.
- Autoscaling: Dynamically adding or removing resources based on real-time demand fluctuations to optimize cost and performance.
- Asynchronous Processing: Deferring non-critical computations (e.g., logging, analytics) to background jobs to improve response times for search queries.
- Prefetching Techniques: Anticipating popular search queries and precomputing results for quick retrieval.
Failure Scenarios Analysis
Index Corruption: Implementing a backup and versioning mechanism to quickly recover corrupted indexes without significant downtime.
Data Inconsistency: Using eventual consistency mechanisms to synchronize across distributed nodes while ensuring user-facing queries retrieve the latest available results.
Surge Traffic Handling:
- Rate Limiting: Protecting the system from traffic spikes by throttling excessive requests.
- Queue-Based Processing: Using message queues (e.g., Kafka) to handle bursts of search queries efficiently without overwhelming the backend.
- CDN Failover: Redirecting traffic to different edge nodes when one experiences high latency or failures.
Full Answer: https://bugfree.ai/practice/system-design/facebook-search/solutions/Ksq_nqNv15bWsUHb


System Design Answer — Design Facebook Search

