
Meta Mock System Design Interview: Top-K Request Analysis System
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
This time, the mock interview is with a friend from Meta who is a senior engineer. Since it’s the end of the year and PSC season, it’s time to start preparing just in case. 😂
The topic this time is Top K, a classic data processing problem. The Engineer has covered a lot of topics across different domains, and while in real interviews, it is recommended to focus 3–4 and do a deepdive.
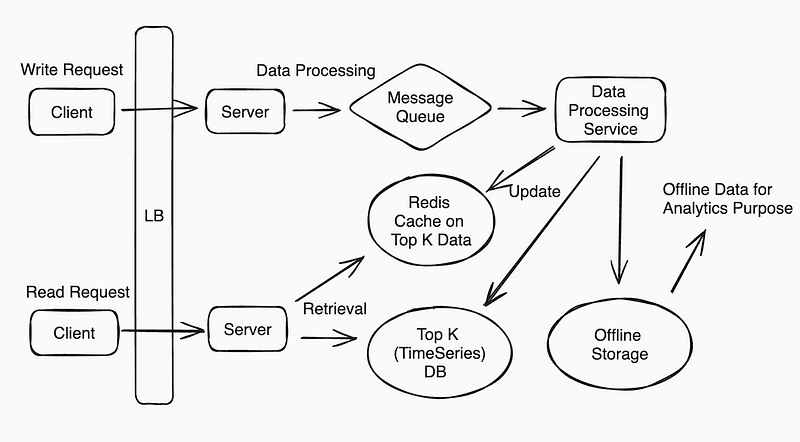
System Design Diagram — Design a Top-K Request Analysis System
Data Collection & Aggregation
Efficient Data Collection
To efficiently collect data from multiple sources in real-time, the system must focus on:
- Ingestion Pipelines: Establishing a distributed data ingestion mechanism ensures the system can handle high data volumes. This involves:
- Message Queuing: Data is captured via producers and queued for consumption. Using partitioning strategies (e.g., hashing based on request type or origin) ensures even load distribution.
- Schema Validation: A schema definition enforced at the producer and consumer ends ensures consistency. Implement schema evolution strategies to accommodate changes without breaking downstream systems.
Data Validation and Deduplication:
- Validate incoming data to filter out malformed or irrelevant records early.
- Deduplication mechanisms based on unique keys (e.g., timestamp and request ID combination) prevent redundant processing.
Fault Tolerance:
- Employ a distributed storage buffer to handle system failures, ensuring that data is not lost during processing or ingestion bottlenecks.
Data Aggregation Strategies
Identifying Top-K requests in real-time requires efficient aggregation:
Sliding Window Aggregation
- The sliding window technique processes data in fixed-size intervals while allowing partial overlap. For example, a 5-minute window sliding every minute ensures recent data visibility.
- To optimize processing, pre-aggregate partial results in smaller windows, combining these results at higher intervals to form complete aggregations.
Data Structures for Top-K Computation:
- Heap-based Approach: A min-heap of size K maintains the Top-K elements. For every new data point, compare and replace elements in the heap if the new value qualifies.
- Count-Min Sketch: For approximate results, this probabilistic data structure provides low memory overhead and fast updates by hashing requests into a frequency table.
Distributed Aggregation:
- Shard data by key (e.g., request type) across nodes. Each shard performs local aggregation, and a centralized reducer combines these results to compute the global Top-K.
System Scalability
The system must dynamically adapt to changing workloads. Key design strategies include:
Partitioning and Sharding
- Partition data based on request characteristics (e.g., user ID, geolocation) to evenly distribute the load across nodes.
- Employ consistent hashing to minimize rebalancing when nodes are added or removed.
Dynamic Scaling:
- Monitor system metrics (e.g., CPU, memory usage, request rate) to trigger scaling actions.
- Use techniques like auto-splitting of partitions or horizontal scaling by adding more processing nodes.
Load Balancing:
- Route incoming data intelligently to prevent bottlenecks. Adaptive load balancing, guided by real-time monitoring, can redirect traffic to underutilized nodes.
Performance Optimization
In-Memory Processing:
- Use in-memory data structures for frequently accessed data to reduce latency. Priority queues, hash maps, and prefix trees (trie) are efficient options for real-time lookups.
Batch vs. Stream Processing:
- Combine real-time stream processing for immediate insights with periodic batch jobs for larger-scale aggregations and accuracy.
Optimized Query Execution:
- Use indexed data storage to speed up query lookups.
- Shard and partition data across multiple nodes to distribute query load and reduce latency for large datasets.
Data Storage Model
Column Databases for Analytics:
- Store data in a column-oriented format for efficient aggregation and filtering during queries.
- Partition by time (e.g., hourly, daily) for quicker range scans in historical analysis.
Indexing Strategies:
- Use composite indexes for multi-dimensional queries (e.g., by time and request type).
- Employ bitmap indexes for categorical data to speed up aggregations.
Replication and Consistency:
- Replicate data across nodes for fault tolerance, and choose consistency levels (e.g., eventual vs. strong consistency) based on real-time requirements.
Data Cleanup and Retention
Implement lifecycle policies to manage storage efficiently:
Retention Policies:
- Define rules to archive or delete older data (e.g., retain only the past 30 days for real-time analysis).
- Use compaction to merge small files into larger blocks for storage optimization.
Archival Storage:
- Move infrequently accessed data to low-cost archival storage, ensuring it remains accessible for historical analysis.
Real-Time Analysis
Stream Processing Framework:
- Employ a distributed stream processing mechanism that ingests, aggregates, and emits results in near real-time.
- Utilize parallel execution to process multiple streams concurrently, reducing latency.
Efficient Top-K Updates:
- Incrementally update Top-K results as new data arrives, avoiding re-computation of the entire dataset.
- Use windowed joins to correlate real-time streams with historical reference data for context-aware analysis.
Reporting and Visualization
Aggregation Layers:
- Separate raw data processing from aggregation layers. Store pre-aggregated results for quick retrieval and rendering in dashboards.
User-Friendly Dashboards:
- Use intuitive visualization techniques such as bar charts, heatmaps, and real-time leaderboards.
- Enable user-defined filters and drill-down capabilities to explore data interactively.
Alerting Mechanisms:
- Implement threshold-based alerts (e.g., if a request type exceeds a certain frequency) to notify users of anomalies or trends in real-time.


System Design Solution — Design a Top-K Request Analysis System
Full Answer: https://bugfree.ai/practice/system-design/top-k-analysis/solutions/KuOkqlrh2jmPQl_n

