
Master Real-Time Analytics: Kafka & Spark Pipeline Explained

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Master Real-Time Analytics: Kafka & Spark Pipeline Explained
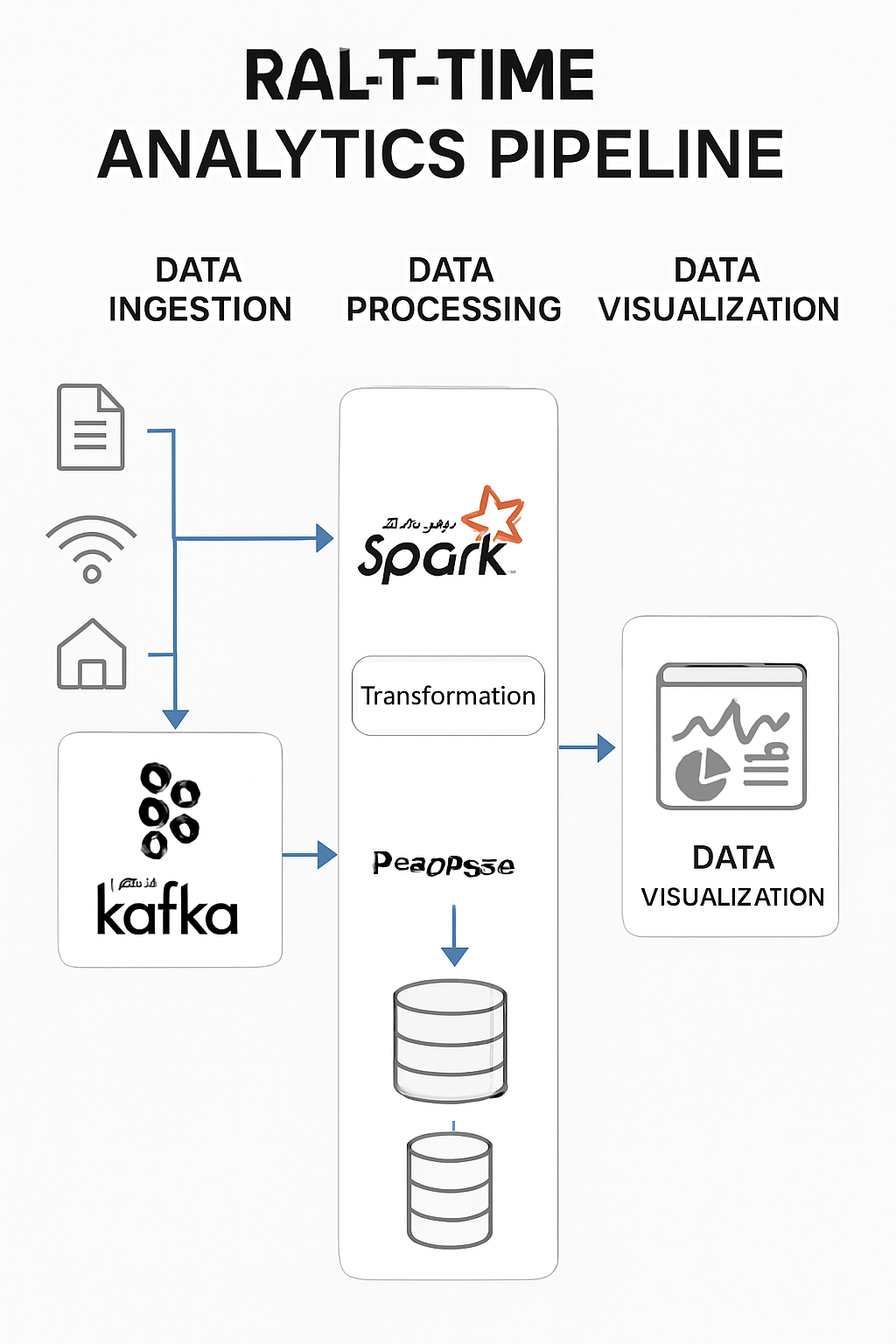
Real-time analytics powers timely decision-making across modern businesses. A reliable pipeline must ingest high volumes of streaming data, process it with low latency, and store or visualize results for downstream use. Combining Apache Kafka for streaming ingestion and Apache Spark for scalable processing is a proven architecture that delivers throughput, fault tolerance, and flexibility.
High-level architecture
- Producers push events (logs, metrics, transactions, IoT telemetry) into Kafka topics.
- Kafka acts as the durable, distributed ingestion layer, providing partitioning, retention, and high-throughput delivery.
- Spark Streaming (preferably Structured Streaming) consumes from Kafka, performing transformations, aggregations, enrichments, and windowed analytics.
- Processed results are written to durable stores: data lakes, OLAP warehouses, NoSQL databases, or search indexes.
- Dashboards and BI tools visualize results for monitoring and business insights.
Data flow (step-by-step)
- Producers publish messages to Kafka topics with meaningful keys and well-defined schemas (Avro/Protobuf + Schema Registry recommended).
- Kafka persists messages across brokers and serves them to consumers at high throughput.
- Spark Structured Streaming reads from Kafka (using Kafka integration), applies transformations and stateful operations, and maintains exactly-once guarantees when configured correctly.
- Spark writes results to sinks (e.g., Parquet on S3, Cassandra, PostgreSQL, Elastic) and can also stream metrics to monitoring systems.
- Visualization layers consume processed data for alerts, dashboards, and ad-hoc queries.
Example: Spark Structured Streaming (Python pseudocode)
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("realtime-analytics").getOrCreate()
# Read from Kafka
raw = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "kafka:9092")
.option("subscribe", "events-topic")
.load())
# Parse and transform
events = (raw.selectExpr("CAST(value AS STRING) as json")
.select(from_json(col("json"), schema).alias("data"))
.select("data.*"))
# Write to a sink (e.g., Parquet on S3)
(query = events.writeStream
.format("parquet")
.option("path", "s3://my-bucket/processed/")
.option("checkpointLocation", "/checkpoints/events/")
.outputMode("append")
.start())
Best practices and considerations
- Schema management: Use Avro/Protobuf + Schema Registry to evolve schemas safely.
- Exactly-once semantics: Enable idempotent producers in Kafka and configure Spark checkpoints and transactional sinks where possible.
- Partitioning and keys: Choose partition keys that balance throughput and preserve affinity for aggregations.
- State management: Keep state stores compact and set appropriate retention for windowed operations.
- Fault tolerance: Use Kafka replication, Spark checkpointing, and automate recovery procedures.
- Monitoring: Track end-to-end latency, consumer lag, throughput, and errors with Prometheus/Grafana or APM tools.
- Cost vs latency: Tune micro-batch size / trigger intervals (or use continuous processing) to meet latency requirements while controlling resource costs.
When to use this stack
- High-throughput event ingestion with durable retention (Kafka).
- Complex, scalable stream processing with stateful logic and micro-batching (Spark Structured Streaming).
- Scenarios requiring integration with data lakes and batch analytics (Spark’s unified batch/stream model).
Conclusion
A Kafka + Spark pipeline provides a robust foundation for real-time analytics: Kafka ensures reliable, scalable ingestion while Spark offers powerful, fault-tolerant processing. Mastering this architecture—schema design, partitioning, state handling, and monitoring—unlocks scalable, reliable analytics for modern applications.
If you want, I can provide a full Spark Structured Streaming example (with schema and deployment tips) or a checklist for production readiness.

