
Kafka for System Design Interviews: The Real-Time Pipeline You Must Be Able to Explain

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
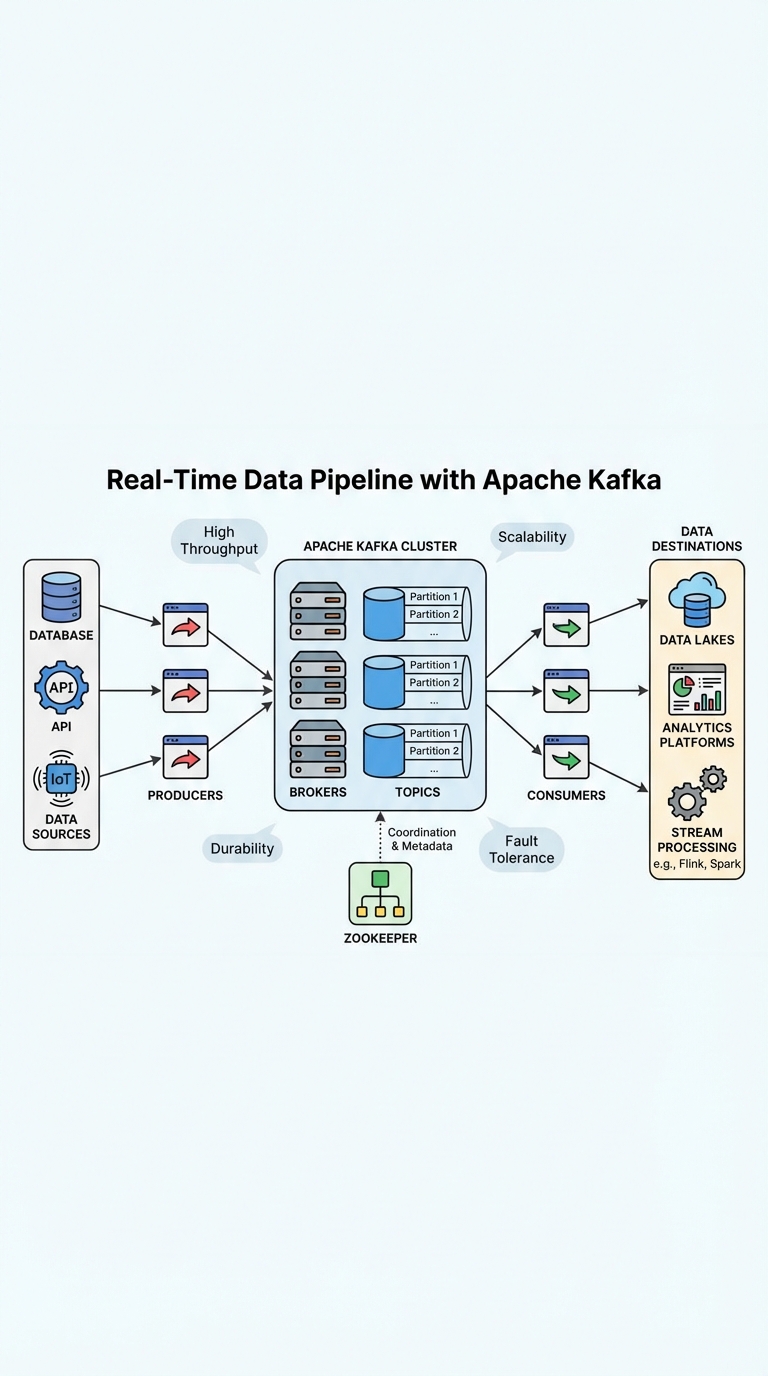
Kafka for System Design Interviews: The Real-Time Pipeline You Must Be Able to Explain
Apache Kafka powers many real-time pipelines because it combines high throughput, low latency, and strong durability. In system design interviews you'll be expected to not only name Kafka's components but also justify design choices and trade-offs. This guide gives a compact, interview-ready explanation you can memorize and adapt.
Core concepts to state clearly
- Producers: write messages to topics.
- Topics: logical streams of data; split into partitions for parallelism and ordering guarantees per partition.
- Partitions: the unit of parallelism. More partitions = more consumer parallelism but higher coordination overhead.
- Brokers: Kafka servers that store and serve partitions; they replicate partition data across brokers for durability.
- Replication & ISR: each partition has one leader and multiple followers in the In-Sync Replica set (ISR). Leader serves reads/writes.
- Consumers & Consumer Groups: consumers in a group share partitions; each partition is consumed by only one consumer in the group for scalability.
- Offsets: the position a consumer has read to; enables replay and exactly-once semantics with the right configuration.
- Coordination: historically ZooKeeper managed cluster metadata and leader election. Newer Kafka versions use KRaft (Kafka Raft) to remove ZooKeeper.
Design choices interviewers expect you to discuss
- Partitioning strategy
- Choose a key to evenly distribute load while preserving ordering guarantees where required.
- Consider number of consumers and expected throughput; aim for more partitions than consumers (e.g., 2× consumers) to allow scaling.
- Replication factor
- Commonly 3 in production (balance of durability and storage cost).
- Explain trade-offs: higher factor = more durability but more storage and network.
- Retention and compaction
- Time-based retention for logs, compacted topics for changelogs (stateful stream processing).
- Schema registry
- Use Avro/Protobuf/JSON Schema with a Schema Registry to ensure backward/forward compatibility.
- Delivery semantics & retries
- At-least-once by default; explain idempotent producers and transactions for exactly-once across producers/consumers or sinks.
- Plan for retry policies, exponential backoff, and Dead Letter Queues (DLQs).
- Monitoring & observability
- Track throughput, consumer lag, ISR size, broker disk usage, GC, and request latency.
End-to-end pipeline blueprint (succinct)
- Sources (API servers, sensors, DB change streams like Debezium) →
- Kafka topics (partitioned, replicated, schemas enforced) →
- Consumers / Stream processing (Kafka Streams, Flink, Spark Streaming) for enrichment, aggregation, or filtering →
- Sinks (databases, data warehouse, search index, downstream services) and archival storage
Describe each hop: expected QPS, retention window, desired latency, and failure modes.
Operational & reliability considerations
- Rebalancing: explain how consumer group rebalances affect processing and how to minimize disruption (sticky assignment, shorter rebalance times).
- Backpressure: handle bursts with buffering, rate limiting, or autoscaling consumers.
- Data loss protection: acknowledge strategies (replication factor, min.insync.replicas, ack=all) and costs.
- Upgrades & rolling restarts: keep ISR healthy; monitor controller leadership and partition leaders.
- Testing and chaos: simulate broker failure, partition loss, and network flaps in staging.
How to structure your interview answer (quick template)
- Clarify requirements: throughput, latency, ordering, retention, single-region vs multi-region, cost constraints.
- Sketch the pipeline: sources → Kafka → processors → sinks.
- List Kafka configs & numbers: partitions (estimate), replication factor (3), retention (e.g., 7 days), min.insync.replicas (2), acks=all for producers.
- Discuss schema & compatibility strategy (Schema Registry + Avro/Protobuf).
- Cover error handling: retries, idempotence, transactions, DLQs.
- Finish with monitoring & scaling plan.
Example concise answer snippet you can memorize:
"I'd place Kafka between producers and consumers to decouple systems. Use topic partitioning by user_id (or a composite key) to balance load while keeping per-user ordering. Start with 100 partitions per high-volume topic so we can scale consumers; set replication factor to 3 and min.insync.replicas to 2, producers use acks=all. Enforce schemas with a Schema Registry, implement idempotent producers and DLQs for poison messages, and monitor consumer lag, throughput, and ISR sizes to detect problems."
Common pitfalls to call out
- Too few partitions limiting parallelism.
- Over-partitioning causing controller and replica management overhead.
- Ignoring consumer lag and rebalancing impacts.
- Missing schema governance leading to downstream breakages.
- Assuming exactly-once by default without enabling idempotence/transactions.
Quick checklist to memorize for interviews
- State core components: producers, topics, partitions, brokers, consumers, replication.
- Give numbers: partitions estimate, replication factor, retention policy.
- Mention schema registry and compatibility strategy.
- Explain retries, idempotence, DLQ, and monitoring metrics.
- End with scaling and failure recovery plans.
With this structure you can confidently explain a Kafka-backed real-time pipeline, discuss trade-offs, and answer follow-up questions that probe for depth.

