
Google System Design Interview — Designing a File Storage Service Like Dropbox or Google Drive
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Designing a Dropbox- or Google Drive-like file storage system requires more than just using scalable technologies. It requires understanding and architecting the underlying mechanics that make such a service robust, consistent, and high-performing at scale.
1. Scalability and Availability
Handling Concurrent Requests from a Large User Base
A file storage system may need to handle millions of simultaneous file uploads, downloads, and metadata lookups. This means the system must be horizontally scalable and fault-tolerant.
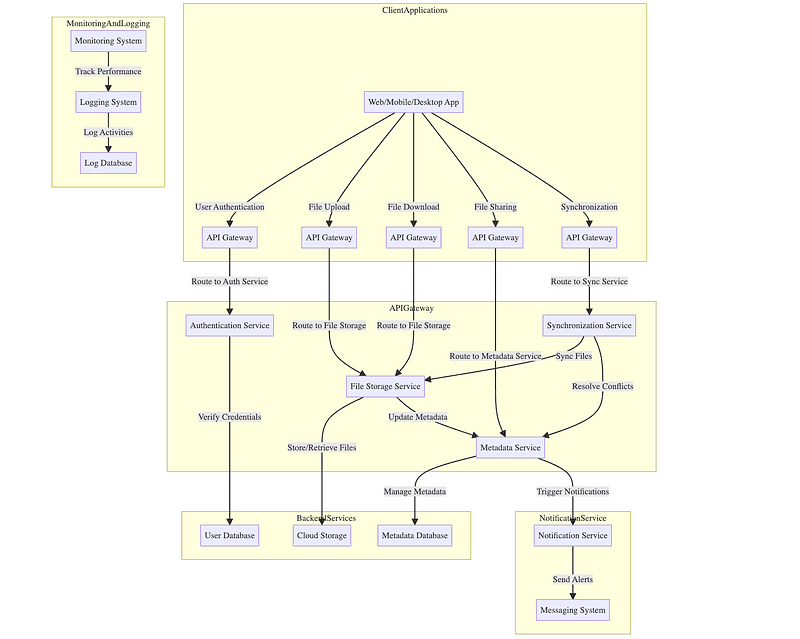
Horizontal Scaling Architecture
At the core of the design is microservices separation, where responsibilities are split across independent stateless services:
- Authentication Service — Issues tokens for client access.
- Upload Service — Accepts and manages file chunk uploads.
- Metadata Service — Maintains file tree, access control, and versioning.
- Storage Service — Handles file chunk reads and writes.
- Sync Service — Keeps client devices in sync with server state.
Each service runs on a stateless compute node and stores persistent data externally (databases or blob stores). This allows services to be cloned and distributed across nodes, and scaled independently depending on traffic (e.g., storage nodes for uploads/downloads, metadata nodes for browsing).
Each node maintains health-check endpoints so orchestrators (like Kubernetes or ECS) can replace or redistribute loads in the event of failure.
Load Balancing
Incoming traffic is directed by front-facing load balancers. These balance requests using algorithms like:
- Round-robin — Rotates evenly across instances.
- Least connections — Useful for longer-lived sessions.
- IP hash — Sticky sessions for caching or consistency.
For upload/download endpoints, use application-layer load balancing based on file chunk ID or user ID to distribute the load to storage nodes holding relevant data. This avoids cross-node communication and reduces latency.
Ensuring Data Availability and Durability
File data and metadata must be reliably stored even if hardware fails or data centers go down.
Data Replication
Files are typically broken into chunks (e.g., 8MB per chunk) and stored on a distributed object store. There are two common durability strategies:
- Replication: Each chunk is replicated to 3+ storage nodes. Writes require quorum acknowledgement (e.g., 2 out of 3 nodes must succeed). Reads can be served from any replica.
- Erasure Coding: More storage-efficient. For example, a file chunk is split into 6 data blocks and 3 parity blocks (Reed-Solomon encoding). Any 6 of 9 blocks can reconstruct the file. This provides durability with lower redundancy cost but at the cost of higher read/write complexity.
Storage nodes run background health checks to detect corrupt or missing chunks and use peer replication to restore consistency (using Merkle trees to detect divergences efficiently).
Backup and Recovery
While replication protects against hardware failure, snapshot-based backups protect against logical failures (e.g., accidental deletion).
- Metadata snapshots (e.g., every 5 minutes) are written to a consistent backup log.
- File data backups can be incremental: track and store only changed blocks since the last backup (copy-on-write mechanism).
- Backups are stored in isolated, write-once volumes to prevent tampering.
Disaster recovery is modeled with Recovery Point Objective (RPO) and Recovery Time Objective (RTO) metrics. Backups are periodically tested via mock restores to validate integrity.
2. Data Consistency and Synchronization
Ensuring Consistent File Synchronization Across Devices
Synchronizing a file system across devices in real time is complex due to:
- Latency
- Concurrent modifications
- Disconnected states
Version Control and Optimistic Locking
Each file is associated with:
- File ID
- Version Hash (e.g., SHA-256 hash of content + metadata)
- Last Modified Timestamp
- Client Write Session ID
Clients use optimistic locking by attaching the last-known file version to each update request. The server compares it to the current version:
- If unchanged, the update is accepted and a new version is generated.
- If changed, the update is rejected or results in a conflict file.
Changes are tracked in version chains to allow history traversal and rollback. Each version includes a delta log or full snapshot, depending on file size and system policy.
Real-Time Synchronization
To minimize sync delays:
- Devices maintain a WebSocket or long-polling connection to the sync service.
- When a change occurs, the server pushes a delta event (e.g., “file A updated to version X”) to all connected devices.
- Devices respond by fetching the diff or downloading the new version.
Clients track file trees with a sync clock vector (per-directory timestamped index), which is compared to the server’s vector to determine what changed.
To optimize, sync can be debounced to aggregate multiple rapid changes into one.
Handling Offline File Modifications
Offline clients queue local file system operations. Each change is recorded with:
- Operation type (create, edit, delete, move)
- File path
- File content hash or delta
- Local timestamp
Upon reconnection:
- The client sends a list of pending operations.
- The server compares with its current state.
- If server versions match, changes are applied.
- If mismatches exist, a merge algorithm (e.g., last-writer-wins, user conflict prompt, or domain-specific merging) is invoked.
This design requires a change-log-based metadata layer to allow consistent replays and rollbacks of conflicting states.
3. Security and Privacy
Data Encryption
All data must be encrypted both in transit and at rest.
At-Rest Encryption
Files are encrypted per chunk using AES-256-GCM. Each file has:
- A unique encryption key (DEK — Data Encryption Key)
- DEKs are encrypted using a master key from a Key Management System (KMS)
Chunk metadata stores the encrypted DEK and IV (initialization vector). The KMS never stores raw DEKs, only key references and access policies.
In-Transit Encryption
All communications between clients, servers, and storage use TLS 1.3 with strong cipher suites. Certificate pinning can prevent MITM attacks in client apps.
Authentication and Authorization
Authentication
- Use OAuth 2.0 for third-party login.
- Use JWTs with embedded scopes and expiration to secure session flows.
- Tokens are validated on each request via signature verification, not server-side lookup, allowing stateless access control.
Authorization
Access is enforced through ACLs stored in the metadata layer:
- Each file/folder has an ACL object mapping
user/group -> [permissions] - Permissions may include: read, write, share, delete
To speed up access decisions, cache ACLs in a distributed in-memory store (e.g., Redis) with invalidation hooks on updates.
4. User Experience and Interface Design
Designing a User-Friendly Interface
From a backend perspective, the UI interacts with:
- Metadata APIs for browsing and searching files.
- File APIs for upload/download and preview.
- Notification APIs (WebSockets) for real-time sync updates.
Search and Navigation
Files and metadata are indexed in a search engine (e.g., using an inverted index structure), with support for:
- Full-text search (if files are text-based or OCR-processed)
- Filtering by type/date/owner
- Autocomplete based on popular queries
Handling Large File Uploads and Downloads
Chunked Uploads
Large files are split client-side into fixed-size chunks (e.g., 8MB). Each chunk is:
- Assigned a chunk ID (
file_id:chunk_index) - Has a hash for integrity check
- Uploaded via parallel HTTP requests
The server uses a state machine per upload:
INIT– Register upload session and expected chunks.RECEIVING– Accept chunk uploads.ASSEMBLING– Verify chunk hashes, assemble the file.COMMIT– Finalize metadata entry and publish file version.
Resume Support
The server tracks uploaded chunks via a bitmap or list. On reconnect, the client queries the current upload state and resumes from the missing chunks.
Bandwidth Management
- Bandwidth throttling is enforced client-side via upload policies.
- Server prioritizes metadata and control messages over large file traffic to maintain responsiveness.
- Admins may set limits per user to prevent abuse.
5. Conflict Resolution: Handling Concurrent Edits on Shared Files
When multiple users or devices attempt to modify the same file — especially a shared document — at the same time, the system must reconcile these changes in a way that preserves data integrity, minimizes user disruption, and maintains a coherent file history.
This section dives into the detection, resolution strategies, and underlying data structures used for resolving conflicts in a distributed file storage system.
Conflict Detection
A conflict is detected during synchronization when a device or user attempts to commit a change to a file version that has already been updated by someone else.
Each file version is tracked using:
- A version ID (e.g., content hash or monotonic timestamp)
- A last modified timestamp
- A client write session ID (optional)
- A vector clock or CRDT timestamp (for advanced cases)
Basic conflict detection algorithm:
- User A downloads file at version
v1. - User B modifies and uploads file → version becomes
v2. - User A goes offline and modifies the file based on
v1. - Upon reconnect, User A attempts to upload changes.
- Server compares
v1(expected base) with current versionv2. - Since
v1 ≠ v2, a conflict is raised.
Resolution Strategies
There are multiple ways to handle this, depending on file type and user expectations:
1. Manual Merge (Most Common for Binary Files)
This is the simplest strategy for general-purpose file types (e.g., PDFs, images, Word docs).
- The system creates two parallel versions:
- One with the server’s changes (current head,
v2) - One with the client’s upload (conflicting version,
v3) - The client upload is preserved as a separate file, renamed with a suffix like:
"report.docx" → "report (conflict - userA).docx"
This is non-destructive, user-visible, and requires human resolution, but ensures no data is lost.
2. Last-Write-Wins (LWW)
Used for less critical content, or when conflict tolerance is acceptable.
- The server overwrites previous changes with the latest one based on timestamp or client priority.
- This method is fast and simple, but can lead to silent data loss if users aren’t notified.
Variants:
- LWW per-field (for structured files like JSON) retains unaffected fields while resolving overlapping ones based on timestamps.
3. Three-Way Merge (for Structured Textual Files)
This is common in collaborative editing systems or plain-text-based file types (e.g., Markdown, source code):
- Base version: common ancestor (e.g.,
v1) - Server version: latest committed version (e.g.,
v2) - Client version: user-modified version (e.g.,
v3)
A diff tool performs a three-way merge by:
- Comparing base to server → delta A
- Comparing base to client → delta B
- Applying both changes to base, line-by-line or token-by-token
- If deltas overlap, mark as a conflict (e.g., Git-style conflict markers)
This can be performed:
- Server-side (then pushed to all clients)
- Client-side (with user interaction for conflict resolution UI)
4. CRDTs (Conflict-Free Replicated Data Types)
Best used for real-time collaborative editing (Google Docs-style).
- The file content is modeled as a sequence of operations (e.g., insert, delete, replace).
- Each operation has:
- A globally unique timestamp or ID
- A causal order (via Lamport clocks or vector clocks)
CRDTs allow non-blocking merges because:
- All operations are commutative and associative
- There is a deterministic resolution rule for concurrent ops
Example: Two users insert a character at the same index.
- The system orders the inserts based on Lamport timestamps and applies both.
This enables eventual consistency without conflicts, but comes with complexity in storage format and operational cost.
Building a Dropbox- or Google Drive-like system is about more than uploading files — it’s about creating a resilient, distributed ecosystem where consistency, performance, durability, and security coexist.

Full Answer: https://bugfree.ai/practice/system-design/file-storage-service/solutions/zyZ_MVTbjZBM3r-6

