
E-commerce System Design: What Interviewers Expect You to Nail

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
E-commerce System Design: What Interviewers Expect You to Nail
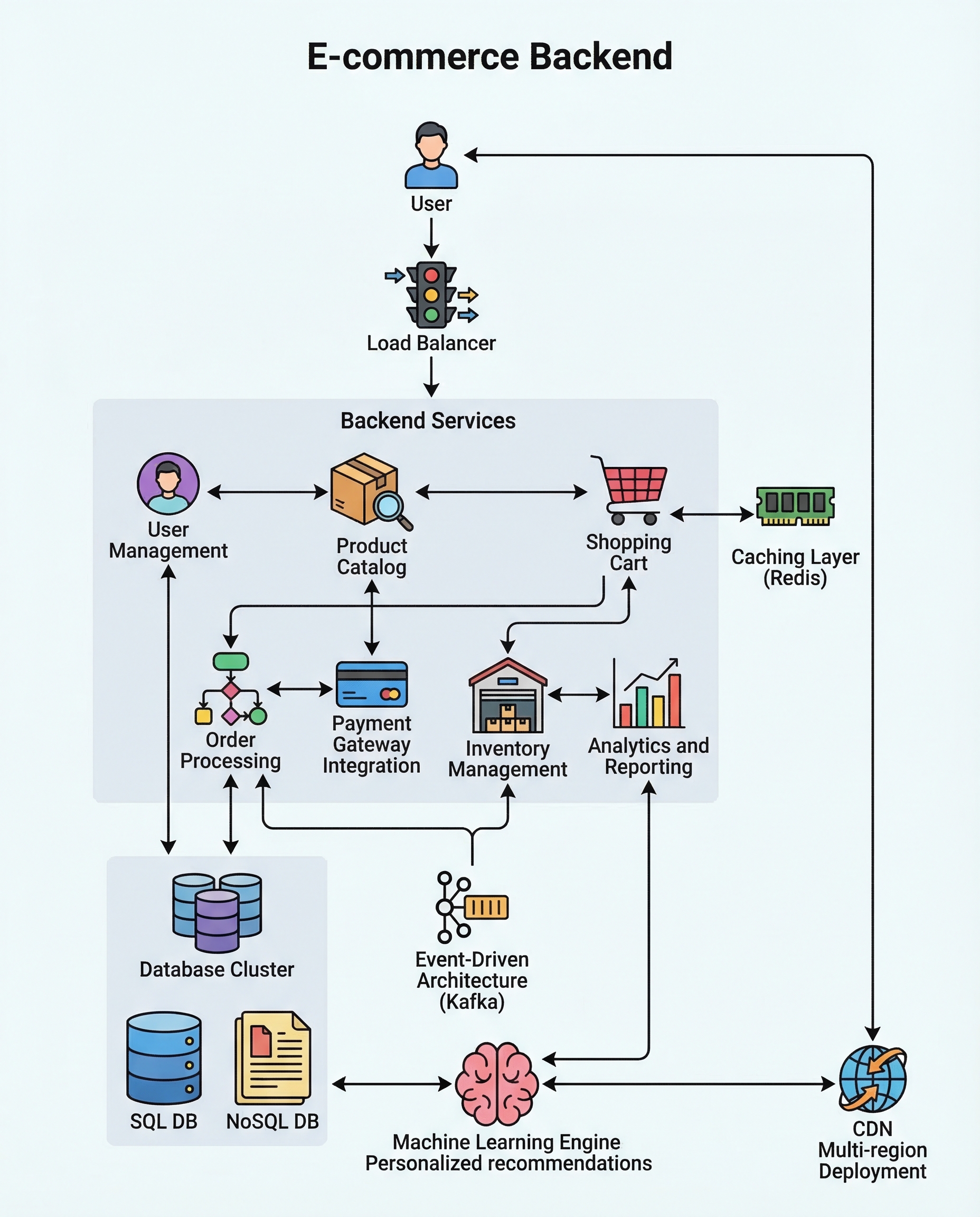
In e-commerce backend interviews you’re expected to cover the core building blocks and then defend your choices against real-world scenarios. Explain components, data flow, and tradeoffs clearly — interviewers want to see that you can design a reliable, scalable system and reason about consistency, latency, and cost.
Below is a concise, interview-ready checklist and guidance you can use when designing an e-commerce backend.
Core building blocks (what to mention and why)
User authentication & authorization
- Options: JWT (stateless, scalable) vs OAuth2 (delegation, third-party logins) vs session cookies (stateful).
- Discuss token expiry, refresh tokens, revocation strategies, secure cookie flags, and storing sessions for logout or admin revocation.
- Tradeoffs: JWT removes server-side session storage but revocation is harder; sessions allow immediate invalidation but need state management.
Product catalog & search indexing
- Primary store: relational DB (rich product relations) or document store (MongoDB, DynamoDB) for flexible schemas.
- Search: dedicated full-text index (Elasticsearch/OpenSearch, Algolia) for faceting, relevance, typo tolerance, and autocomplete.
- Ingestion pipeline: change capture -> indexer -> search cluster. Keep indices eventually consistent with primary store.
Cart persistence
- Options: client-side ephemeral cart + server-side persistent cart, or server-side only.
- Implement carts in a fast store (Redis) for speed; persist periodically or on checkout to a durable database.
- Handle anonymous users with cookie IDs and merge logic when they sign in.
Checkout & order lifecycle
- Define order states (created -> paid -> confirmed -> fulfilled -> shipped -> delivered -> cancelled/returned).
- Ensure idempotency for payment and order creation APIs (idempotency keys) to avoid duplicates.
- Use a saga/orchestration pattern or event-driven state transitions to manage distributed steps (reserve inventory, charge payment, notify fulfillment).
Payment gateway integration
- Offload PCI requirements to third-party providers (Stripe, Adyen) using tokenization.
- Handle webhooks, payment retries, 3DS flows, refunds, and reconciliation.
- Implement robust webhook processing (idempotent, authenticated, retry with dead-letter queue).
Strict inventory control
- Key challenge: avoid overselling while maintaining performance.
- Approaches:
- Strong consistency: centralized DB transactions or distributed locks (pessimistic locking) — safest but can be a bottleneck.
- Reservation pattern: reserve stock for a short TTL when a user initiates checkout, then finalize on payment.
- Optimistic concurrency control: decrement with a version check or conditional updates (CAS) — high throughput but requires retry logic.
- Discuss edge cases (abandoned carts, TTL expirations, stale reservations) and cleanup strategies.
Defending your design for real scenarios
When interviewers push on how your design behaves under pressure, walk through concrete mitigations and tradeoffs.
Traffic spikes
- Horizontal scaling: stateless app servers behind a load balancer and autoscaling groups.
- Caching: CDN for static assets and edge-cached product pages; Redis or in-memory caches for hot reads.
- Partitioning & sharding: shard user data or product data to distribute load; use consistent hashing.
- Graceful degradation: rate limiting, prioritized APIs (checkout > browse), circuit breakers.
Scaling read-heavy workloads (search & catalog)
- Use search clusters that can scale independently from primary DB.
- Denormalize frequently-read aggregates into read-optimized stores (CDN, Redis, or NoSQL).
- Cache invalidation strategies: event-driven cache updates or short TTLs with background refresh.
Real-time stock & consistency
- Event-driven architecture: emit inventory events (Kafka, Pulsar) for downstream consumers (search indexer, recommendation system, analytics).
- Reservation + commit/rollback model using events ensures eventual consistency while minimizing oversell.
- Consider consistency guarantees: at-least-once processing requires idempotency; exactly-once is harder and often unnecessary.
Recommendations & personalization
- Model training offline (batch) and serve features/embeddings in a fast store (Redis, DynamoDB, Cassandra) for low-latency inference.
- Use feature stores and record user interactions (clicks, purchases) via events for near-real-time updates.
- Tradeoffs: complexity and cost of real-time pipelines vs improved conversion from timely recommendations.
Multi-region & latency
- Use CDN for static assets and edge caches for product pages.
- Geo-replicate read-only data for local reads; route writes to a regional leader or central write region depending on consistency needs.
- Cross-region replication, conflict resolution, and data sovereignty considerations increase complexity and cost.
Cross-cutting concerns (must mention)
- Observability & SLOs: metrics, distributed tracing, logs, and alerts. Define latency and error SLOs for critical flows (checkout, payment).
- Security: encryption at rest/in transit, rate-limiting, input validation, least privilege for microservices, secret management.
- Testing & resilience: chaos testing, load testing, and runbooks for incident response.
- Cost vs reliability: explain when you’d pick cheaper eventual consistency vs expensive strongly consistent solutions.
- API design: versioning, pagination, idempotency for write operations, and backward compatibility.
Quick interview checklist (call these out when presenting)
- Identify core components and their responsibilities (auth, catalog, search, cart, checkout, inventory, payments).
- Show data flow for a purchase: browse -> add to cart -> reserve stock -> checkout -> payment -> commit order.
- Explain how you prevent oversell (reservation, locking, or conditional updates) and cleanup abandoned reservations.
- Discuss scaling for spikes (LB + autoscale + caches + sharding) and caching strategies.
- Cover reliability: idempotency keys, retries with backoff, circuit breakers, dead-letter queues.
- Address cross-region latency and data replication strategies.
- Talk about monitoring, alerting, and SLOs.
If you walk an interviewer through these components, the data flow, failure modes, and the tradeoffs behind your choices, you’ll demonstrate both system knowledge and practical engineering judgment.
Good luck — and be ready to sketch a simple architecture diagram and justify each decision with one sentence about tradeoffs.
