
Designing an Ad Click Aggregation System: Meta Senior Engineer System Design Interview Guide
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Designing Ad Click Aggregation System is a frequent system design question for top tech companies which rely heavily on advertising, such as Meta, Amazon, Google …
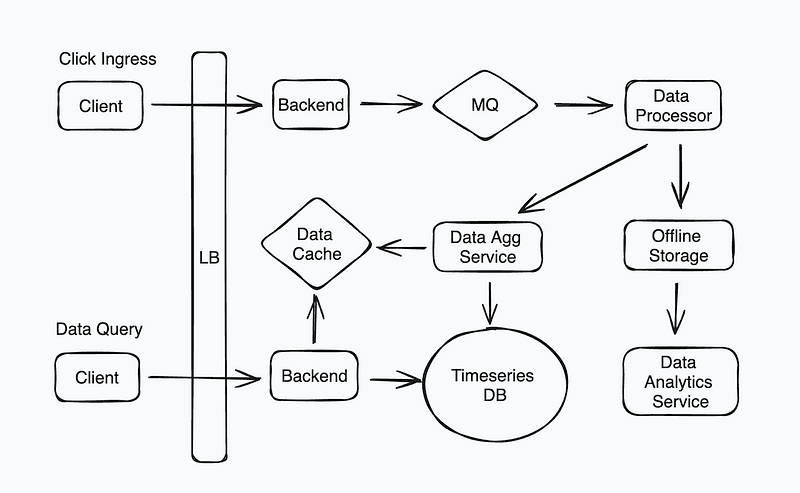
System Design Diagram — Design an Ad Click Aggregation System
Data Ingestion & Real-time Processing
Ensuring Real-time Data Processing
Real-time data processing is essential to maintaining the relevance and accuracy of ad click data. Key considerations include:
Stream Processing Architecture
Instead of batch processing, the system should use a real-time data pipeline based on stream processing frameworks. Core components include:
- Data Producers: Web applications, mobile apps, and ad servers generate clickstream events. These events must be captured as soon as they occur to ensure timely analysis and prevent data loss. The choice of protocol (e.g., HTTP, gRPC, WebSockets) impacts latency and reliability.
- Message Broker (Kafka, Pulsar): Acts as a buffer and decouples producers from consumers, ensuring fault tolerance and durability. Kafka partitions data across brokers, enabling parallel processing and scalability. Choosing the right replication factor ensures reliability without excessive storage overhead.
- Stream Processing Engines (Flink, Spark Streaming): These frameworks process data with low latency, applying transformations, windowing, and aggregations. They ensure exactly-once or at-least-once semantics, preventing data loss or duplication, which is critical in financial reporting and fraud detection.
Buffering and Backpressure Management
A buffering mechanism prevents system overloads during high-traffic periods. Techniques include:
- Adaptive Rate Limiting: Dynamically adjusts the message ingestion rate based on system load, ensuring that spikes in traffic do not overwhelm the processing pipeline.
- Queue-based Buffering (Kafka, RabbitMQ): Provides a temporary holding area for events, smoothing out ingestion rates and allowing the system to absorb bursts in user activity.
- Load Shedding: Drops lower-priority messages if the system nears capacity, ensuring that high-value transactions (such as paid ad clicks) are prioritized over less critical data.
Ensuring Data Accuracy and Completeness
To prevent discrepancies and maintain data integrity:
Idempotency and Deduplication
Duplicate events can arise from retries or network issues. Solutions include:
- Unique Click Identifiers: Each click event should be assigned a UUID at the source, preventing duplicate processing.
- Event Deduplication Stores: Use Redis or Bloom filters to store recently processed event hashes, allowing quick duplicate detection without excessive memory consumption.
Validation and Anomaly Detection
A robust validation pipeline should:
- Filter malformed data: Enforce schemas using Apache Avro or Protobuf to reject incorrect messages at ingestion, reducing downstream failures.
- Outlier Detection: Apply statistical models such as Z-score or machine learning-based anomaly detection (Isolation Forest, LSTMs) to detect fraudulent or erroneous clicks.
Scalability & Performance
Handling Large-scale Data Processing
As traffic scales, the system must handle increased click volume efficiently:
Horizontal Scaling with Sharding
- Partitioning Strategy: Distribute events based on advertiser ID, campaign ID, or user geography to balance load across multiple nodes.
- Distributed Processing: Utilize Kubernetes or containerized microservices to dynamically allocate resources, ensuring high availability and auto-scaling based on demand.
Efficient Storage for Click Logs
- Columnar Databases (Apache Parquet, Apache ORC): Optimized for analytical queries due to efficient compression and vectorized execution.
- Time-series Databases (InfluxDB, TimescaleDB): Designed for high-ingest workloads and fast retrieval of time-based queries, making them ideal for clickstream analysis.
Optimizing Query Performance
Fast query response times are critical for analytics:
Indexing and Data Partitioning
- Composite Indexing: Multi-key indexes optimize searches across frequently queried fields such as campaign ID and timestamp.
- Partition Pruning: Queries automatically exclude irrelevant partitions, significantly improving efficiency by scanning only necessary data.
Caching Mechanisms
- In-memory Caching (Redis, Memcached): Reduces query latency by storing frequently accessed data.
- Materialized Views: Precompute and store results for common queries, reducing computation overhead and improving response times.
Data Storage & Consistency
Choosing the Right Storage Solution
Selecting appropriate storage depends on use cases:
- Relational Databases (PostgreSQL, MySQL): Ensure strong consistency for transactional data but may not scale well for high-ingest workloads.
- NoSQL Databases (Cassandra, DynamoDB): Offer high availability and scalability but require careful schema design for query efficiency.
Ensuring Data Consistency
Maintaining consistency across distributed nodes requires:
- Eventual Consistency (BASE Model): Allows for high availability in distributed systems where immediate consistency is not required.
- Strong Consistency (ACID Transactions): Ensures correctness but may introduce performance overhead.
- Consensus Protocols (Paxos, Raft): Used in distributed databases to synchronize state across replicas, ensuring consistent reads and writes.
Analytics & Reporting
Data Analysis and Report Generation
Transforming raw data into insights requires a well-structured pipeline:
Real-time vs. Batch Analytics
- Lambda Architecture: Combines real-time processing (low-latency insights) with batch processing (historical trends), ensuring both speed and completeness.
- Kappa Architecture: Uses a single real-time data pipeline, simplifying maintenance while leveraging replayable event logs for historical analysis.
Data Visualization and Reporting
- Pre-aggregated Data Views: Reduces query load by storing summary tables, allowing real-time dashboards to refresh efficiently.
- BI Tools (Tableau, Grafana): Enable stakeholders to explore data interactively with customizable visualizations and alerts.
Failure Scenarios and Mitigation Strategies
Common Failure Scenarios and Their Impact
- Network Failures: Network partitions can lead to incomplete or delayed message delivery. Implementing exponential backoff retries and quorum-based consistency checks ensures data integrity.
- Data Loss: Data loss can occur due to hardware failures or software bugs. Regular backups, replication strategies, and write-ahead logging minimize the risk of permanent loss.
- System Overload: If traffic spikes beyond system capacity, latency increases and data may be dropped. Using auto-scaling, rate limiting, and caching mechanisms distributes the load more efficiently.
- Inconsistent Data Replication: If replicas are not synchronized properly, stale or conflicting data may be read. Conflict resolution techniques such as vector clocks, CRDTs, or last-write-wins policies ensure eventual consistency.
- Processing Failures: If processing nodes crash, unprocessed messages may be lost. Implementing dead-letter queues (DLQs) ensures failed messages are retained and retried.
Mitigation Strategies and Their Benefits
- Automated Failover Mechanisms: Leader election algorithms (e.g., Raft, Paxos) ensure minimal downtime by rapidly switching to a standby node.
- Monitoring & Alerting: Tools like Prometheus and Grafana proactively detect issues, reducing time to recovery.
- Chaos Engineering: Running controlled failure scenarios (e.g., shutting down random services) identifies weaknesses before actual failures occur.
- Backpressure Handling: Adaptive throttling prevents system overload by dynamically adjusting the data processing rate based on system health.
Handling Anomaly Detection and Alerts
Identifying fraudulent clicks or performance issues requires:
- Anomaly Detection Models: Uses statistical tests (Z-score, IQR) or ML models (LSTMs, Isolation Forests) to detect click fraud or abnormal behavior.
- Real-time Alerts (Prometheus, PagerDuty): Triggers notifications upon detecting abnormal patterns, enabling quick remediation.
Conclusion
Building a robust ad click aggregation system requires careful architectural choices. From real-time ingestion to scalable storage and optimized analytics, ensuring efficiency, accuracy, and fault tolerance is key to success. By implementing the mechanisms outlined in this guide, you can design a system that meets the demands of large-scale digital advertising operations.
Full Answer: https://bugfree.ai/practice/system-design/ad-click-aggregation/solutions/9hvK4hHooZGGkc03


System Design Solution — Design an Ad Click Aggregation System

