
Designing a Distributed ID Generator: A Detailed Guide
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Design Distributed ID Generator is kind of an entry level system design question, used to be asked a lot in the past, also served as a foundation of many other system designs.
A distributed ID generator is fundamental for many scalable systems. It provides unique identifiers across distributed components without relying on a single point of control.
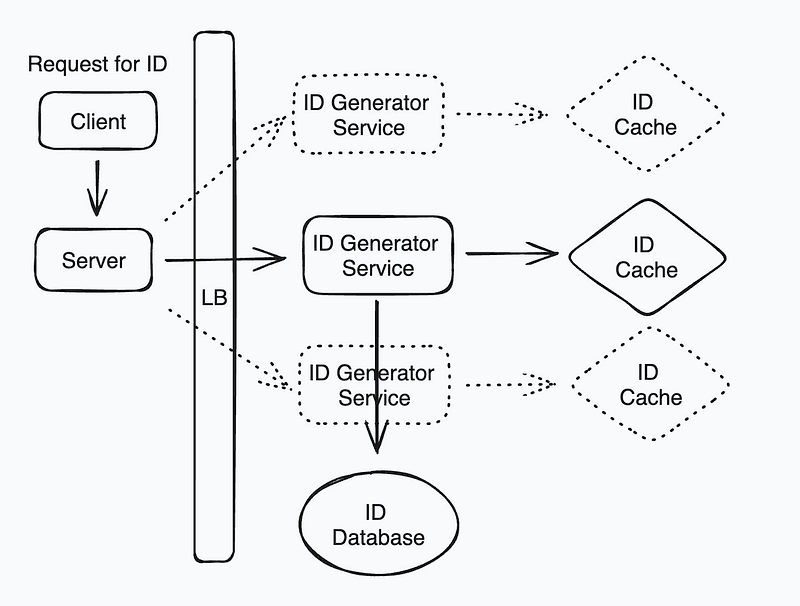
System Design Diagram — Design a Distributed ID Generator
1. Scalability & High Availability
Scalability
Problem: How to ensure the system generates IDs efficiently under high concurrency?
DataBase Storage:
- Use databases like Cassandra, DynamoDB, or CockroachDB to store sequence counters and metadata.
- Employ partitioning to distribute the load across multiple nodes.
Sharding Mechanism:
- Concept: Divide the ID space into disjoint segments, with each node responsible for generating IDs from its segment.
- Implementation Details:
- a) Assign a unique shard ID (e.g., 4 bits in a 64-bit ID) to each node.
- b) Define ID ranges per shard to avoid overlaps (e.g., Node 1 generates IDs in range
[0-10^6), Node 2 generates IDs in range[10^6-2*10^6)). - c) Use consistent hashing for dynamic sharding to minimize reallocation when nodes join or leave.
In-Memory Storage with Periodic Persistence:
- Maintain active counters in in-memory stores like Redis for low-latency access.
- Periodically persist state to a durable database to ensure recovery after crashes.
Load Balancing:
- Use techniques like consistent hashing or a central registry to distribute traffic.
- Implement dynamic rebalancing to adapt to uneven workloads (e.g., migrating shards or reassigning responsibilities).
Note: Consistent hashing minimizes data movement when nodes are added or removed, maintaining balanced load distribution while ensuring the continuity of unique ID generation.
High Availability
Problem: How to handle failures without interrupting ID generation?
Replication:
- Use a primary-backup model where each node has replicas of its shard.
- Periodically synchronize sequence counters between primary and backup nodes to avoid ID overlaps during failovers.
Failover and Recovery:
- Implement heartbeat mechanisms to detect node failures.
- Elect a new primary for failed nodes using consensus protocols (e.g., Paxos or Raft).
Multi-Data Center Deployment:
- Replicate ID generation logic across geographically distributed data centers.
- Use local ID ranges to minimize inter-data-center coordination while maintaining global uniqueness.
Note: By replicating shard responsibilities and using consensus protocols, the system ensures uninterrupted availability during failures.
2. Consistency & Uniqueness
Consistency
Problem: How to ensure global uniqueness without bottlenecks?
Centralized Coordinator:
- Assign ID ranges to nodes dynamically.
- Nodes request new ranges when nearing depletion.
- Bottleneck risk: The coordinator must scale with traffic.
Distributed Coordination:
- Use distributed coordination tools (e.g., Zookeeper or Raft) for managing locks or leader elections.
- Implement a lease-based model, where nodes temporarily own an ID range.
Note: A lease-based approach avoids global contention, enabling efficient distributed coordination while maintaining consistency.
Uniqueness
Problem: How to avoid ID duplication in a distributed system?
ID Structure:
- Timestamp: Include high-resolution time as a component to ensure time-based uniqueness.
- Machine ID: Uniquely identify each node generating the ID.
- Sequence Number: Use per-node sequence numbers to differentiate IDs generated within the same timestamp.
- Example:
- A 64-bit ID:
- 41 bits for timestamp: Sufficient for ~69 years.
- 10 bits for machine ID: Allows up to 1024 nodes.
- 12 bits for sequence number: Allows 4096 IDs per millisecond per node.
Fallback on Collision:
- Implement backoff and retry logic if sequence numbers exhaust in a given millisecond.
- Use atomic counters for sequence generation.
Note: The structured approach minimizes coordination between nodes while ensuring global uniqueness and high throughput.
3. Performance & Latency
Performance
How to meet the high throughput demands of ID generation?
Batch Processing:
- Pre-allocate a range of IDs per node (e.g.,
Node 1: 1-10^6,Node 2: 10^6-2*10^6). - Reduce network calls by serving IDs from memory until the range is depleted.
Caching:
- Maintain pre-generated IDs in memory for immediate access.
- Use ring buffers or queues to handle high-frequency requests.
Note: Pre-allocating and caching ID ranges significantly reduce contention and improve performance.
Latency
How to minimize latency in ID generation?
Asynchronous Generation:
- Decouple ID generation from user requests by employing background workers.
- Use message queues (e.g., Kafka-like systems) for demand buffering.
Optimized Algorithms:
- Use low-complexity operations for ID construction (e.g., bitwise shifts for encoding timestamps, machine IDs, and sequence numbers).
Note: Pre-emptive generation with asynchronous handling ensures low-latency responses, even under peak loads.
4. Fault Tolerance
How to maintain reliability during node or network failures?
Redundancy:
- Replicate critical state (e.g., sequence counters) across multiple nodes or regions.
Partition Tolerance:
- Handle network splits using conflict resolution strategies:
- Assign disjoint ranges to avoid overlaps.
- Reconcile conflicting states upon recovery.
Note: A CAP-aware design balances consistency, availability, and partition tolerance, enabling robust fault tolerance.

System Design Answer — Design a Distributed ID Generator
Full Answer: https://bugfree.ai/practice/system-design/distributed-id-generator/solutions/n-GEIKn_HzsPYt9N

