
Design Distributed Counter: Interview with a Meta E4 Engineer
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Recently, I had the chance to conduct a mock interview with a peer who joined Meta just a year ago and had already reached the E4 level — a testament to the rapid growth opportunities at Meta. Despite having limited firsthand experience with system design interviews, this engineer clearly put in a lot of preparation, showcasing solid foundational skills.
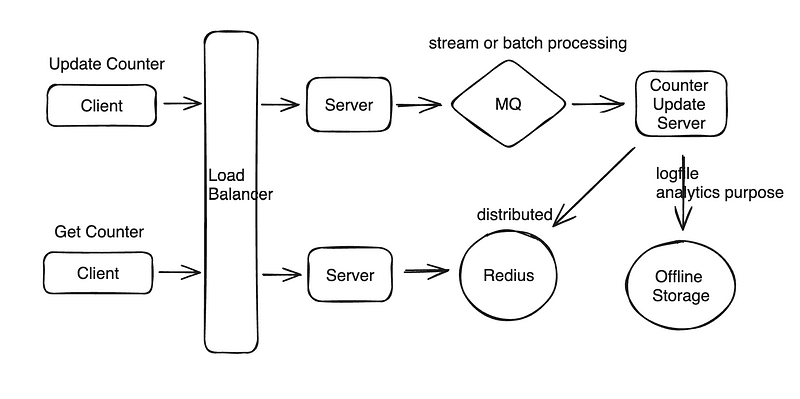
The question we tackled revolved around designing a Distributed Counter System, and it covered some fundamental yet crucial aspects of system design.
Below are the key discussion points and takeaways:
1. Storage Design
The first challenge in designing a distributed counter system is determining the storage architecture. Some of the critical questions to address include:
- Redis Schema: What should the schema of the Redis cache look like? For example, should counters be stored as simple key-value pairs, or would a more complex structure work better for scalability and performance?
- Additional Storage Layers: Beyond Redis as an in-memory cache, do we need another persistent storage layer, such as a relational database, a NoSQL database, or a distributed file system, to ensure durability and fault tolerance?
- Distributed Storage for Redis: Does Redis itself need to be distributed? If so, should we implement clustering to handle large-scale data or high throughput, and how would that impact consistency and partition tolerance?
2. Data Processing Architecture
When handling a distributed counter system, the data processing architecture plays a pivotal role, particularly in balancing performance, scalability, and data consistency.
Streaming vs. Batch Processing:
- Streaming Data Processing: This approach is suitable for real-time updates, ensuring that the counter reflects the most current state. However, streaming can add complexity, especially in terms of ensuring exactly-once or at-least-once delivery guarantees.
- Batch Data Processing: In contrast, batch processing can simplify implementation and is often more cost-effective, but it introduces delays, making it less ideal for real-time use cases.
Frameworks: Different frameworks support these processing paradigms. For example:
- Streaming: Tools like Apache Kafka, Flink, or Spark Streaming could be utilized.
- Batch: Frameworks like Apache Hadoop or standard ETL pipelines would suffice.
3. Read Flow Optimization
Supporting high read traffic while simultaneously handling high write traffic is another critical challenge. The following points were discussed:
- Real-Time Data Consistency in Redis: If read operations rely on Redis, how can we ensure that the data remains up-to-date given the high frequency of writes? This is especially important in distributed systems where eventual consistency might introduce delays.
- Trade-Offs: Achieving real-time consistency may require mechanisms like pub/sub updates, frequent cache invalidations, or syncing Redis with a durable storage layer. However, these come at the cost of increased complexity, latency, or resource utilization.
Conclusion
This problem is considered an entry-level system design question, with relatively standard answers depending on the context and specific requirements. However, diving deeper into these discussions reveals the trade-offs engineers need to make in real-world scenarios.
For those interested in learning more, I’d recommend exploring open-source implementations of third-party counter APIs. There’s a lot to learn from how these APIs are architected to handle distributed counters effectively.
For full answer, checkout it in bugfree.ai

