
Batch vs Real-Time Predictions: The Interview Answer Most Candidates Miss

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
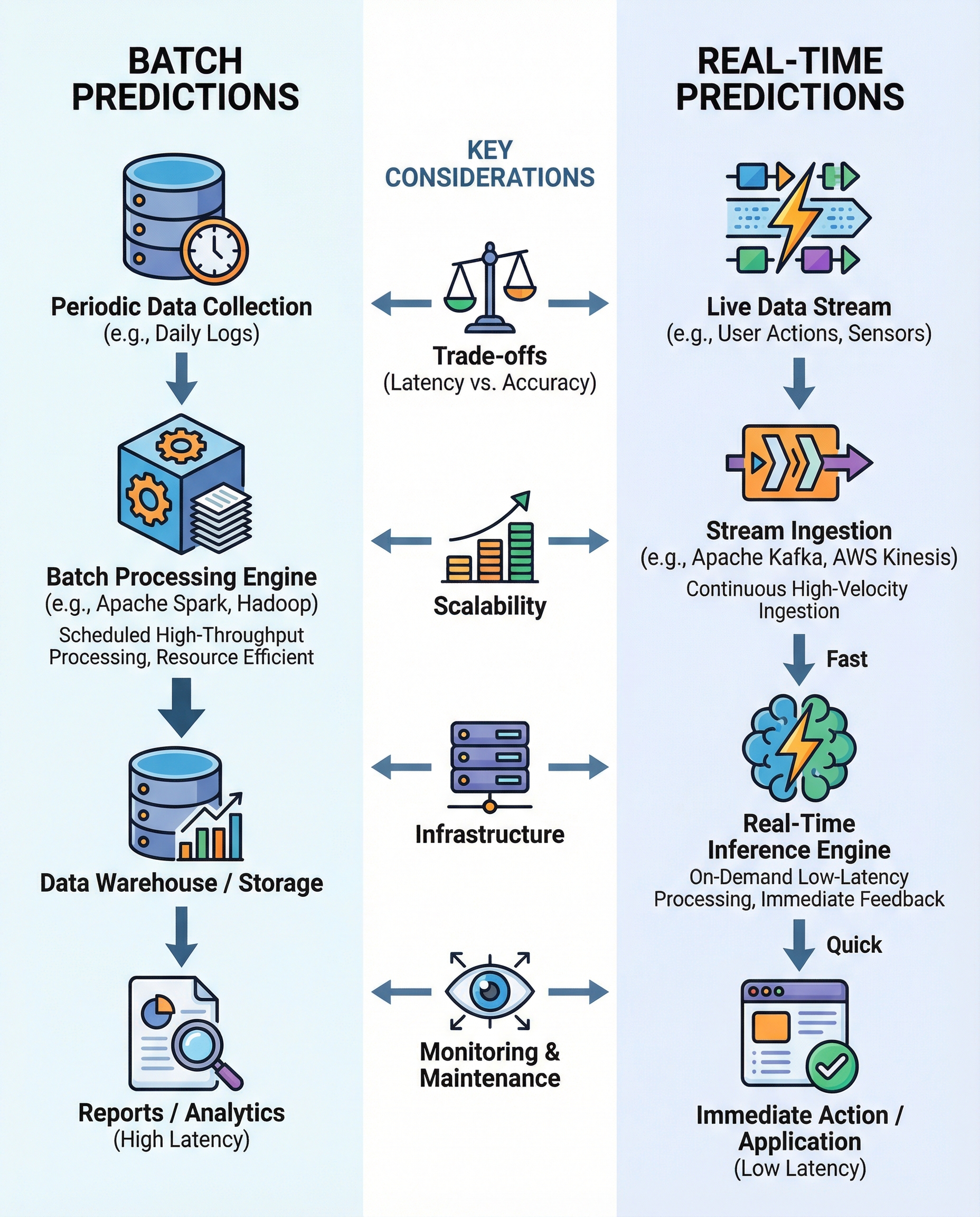
Batch vs Real-Time Predictions — short, clear definitions
Batch predictions process accumulated data in bulk (minutes, hours, or days). They’re appropriate when latency is not critical and you want to optimize throughput and cost — e.g., nightly scoring for end-of-day analytics or periodic model retraining.
Real-time predictions (online/inference-as-event) score each event as it arrives (milliseconds to seconds). Use them when immediate decisions matter: fraud detection, personalized recommendations, or autonomous control.
When to choose which
Choose batch when:
- Decisions can wait (non-urgent business reports, periodic alerts).
- You want to process large volumes efficiently and reduce cost (amortize compute across many examples).
- You can tolerate stale features or infrequent updates.
Choose real-time when:
- Low latency is critical for user experience or safety (click recommendations, fraud blocking).
- You must incorporate the freshest features or context.
- The cost and complexity of operating streaming infrastructure are justified.
Key trade-offs to call out in interviews
Latency vs. Freshness
- Batch: higher latency, potentially richer historical context.
- Real-time: low latency, requires fast feature retrieval and possibly simpler models to meet time budgets.
Throughput & Cost
- Batch: can be cheaper per prediction at high volumes (use distributed compute like Spark/Hadoop jobs).
- Real-time: typically higher cost per prediction due to always-on serving and autoscaling.
Scalability & Infrastructure
- Batch: scales with batch-processing frameworks (Spark, Hadoop, Airflow for orchestration).
- Real-time: relies on streaming/event platforms (Kafka, Kinesis, Pulsar) and low-latency feature stores or caches.
Model Complexity vs. Latency
- Real-time systems often favor smaller or optimized models (quantization, distillation) to meet SLOs.
- Batch can run heavier models or ensembles because time constraints are relaxed.
Monitoring & Drift Detection
- Batch: periodic evaluation and drift checks (daily/weekly model performance reports).
- Real-time: continuous monitoring required (live error, latency, concept drift alerts).
Consistency & State
- Real-time systems must manage state and order (sessionization, deduplication) in a streaming context.
- Batch systems operate on well-defined snapshots, simplifying reproducibility.
Helpful examples to mention
- Batch: end-of-day churn predictions, nightly recommender refresh, scheduled model re-scoring for marketing lists.
- Real-time: credit-card fraud blocking, in-session product recommendations, online ad bidding, autonomous vehicle control.
Short interview answer you can use
"Batch predictions process accumulated data on a schedule and are cost- and throughput‑efficient when latency isn’t critical. Real‑time predictions score events as they arrive and are necessary when decisions must be immediate. The trade‑offs are latency vs freshness, cost per prediction, infrastructure complexity (Spark/Hadoop for batch vs Kafka/Kinesis and low‑latency feature stores for streaming), model complexity constraints, and monitoring cadence — periodic for batch, continuous for real‑time. I’d choose based on business need for immediacy, cost constraints, and operational complexity."
Quick memory checklist (one-liners)
- Latency: batch = high, real-time = low.
- Cost: batch often cheaper per item; real-time costs more for always-on serving.
- Tools: batch = Spark/Hadoop/Airflow; real-time = Kafka/Kinesis/Pulsar + feature store.
- Monitoring: batch = periodic; real-time = continuous.
Final tip
In interviews, frame your answer around a specific business requirement (e.g., "fraud needs sub-second decisions, so real-time"), then justify with trade-offs and tooling. That shows both practical judgment and technical awareness.
#MachineLearning #MLOps #DataEngineering

