
Batch vs Real-Time Predictions: The Interview Answer Most Candidates Miss

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
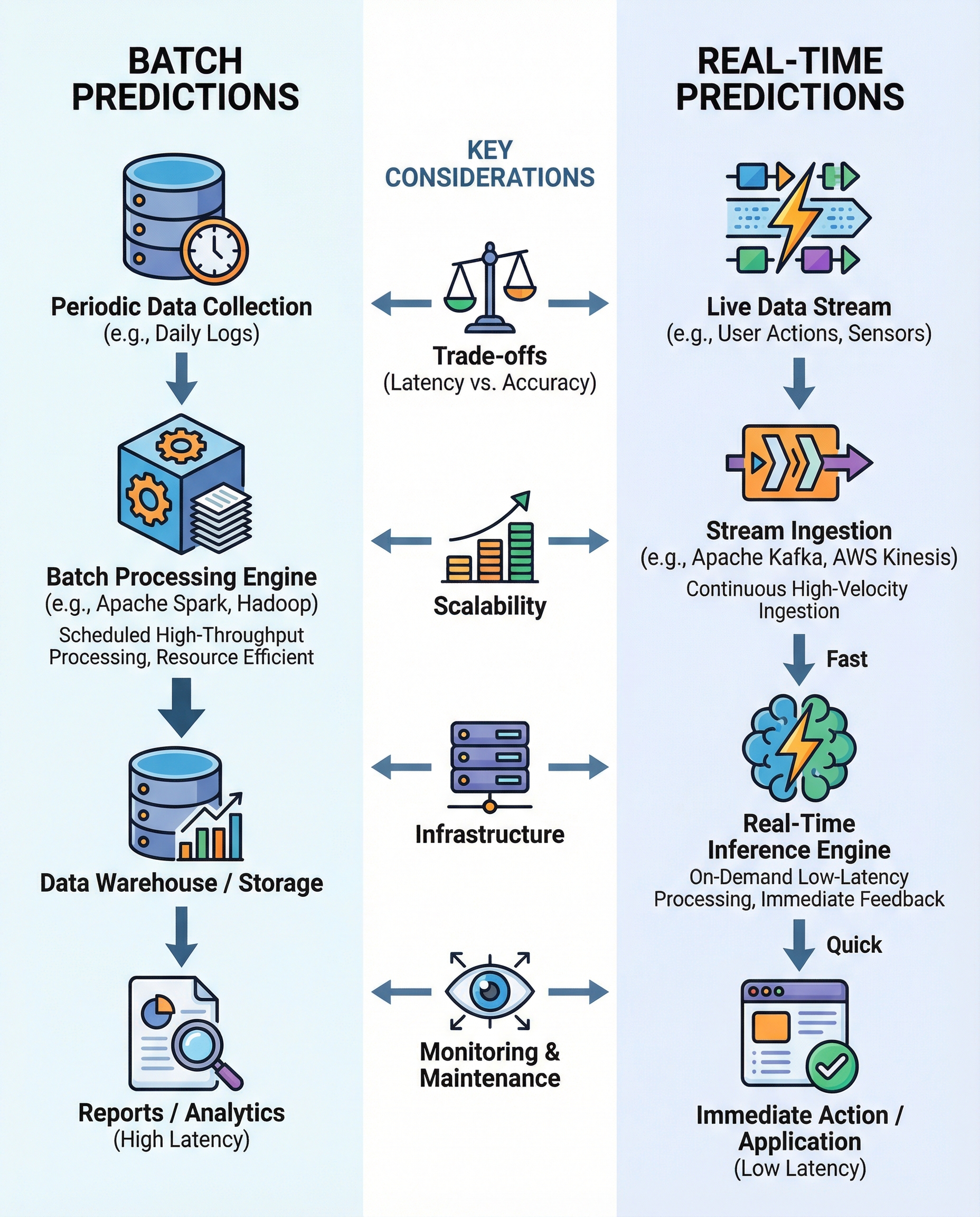
Quick summary: Batch predictions process accumulated data on a schedule (hours/days) and are cost-efficient at scale. Real-time predictions score events as they arrive (ms–s) and are essential when instant decisions matter.
Overview
When building ML-powered systems you'll typically choose between two serving patterns:
- Batch predictions: run inference on accumulated datasets periodically (e.g., nightly, hourly). Good for analytics, periodic reports, and bulk scoring for model retraining.
- Real-time predictions: score individual events as they arrive, with latency measured in milliseconds to seconds. Use when decisions must be immediate (fraud detection, recommendations, control loops in autonomous systems).
Knowing when to use each — and how to explain that decision concisely — is what many interviewers are testing.
When to choose each
Batch predictions
- Use when latency isn’t critical (end-of-day reports, backfills, periodic feature computation).
- Optimizes throughput and cost (can amortize compute over large jobs).
- Easier to debug and repeatable.
Real-time predictions
- Use when decisions must be made immediately (real-time personalization, fraud detection, safety-critical controls).
- Requires low-latency serving and often stateful or streaming feature stores.
- More operationally complex and typically more expensive per request.
Key trade-offs to mention in an interview
- Latency vs. freshness: batch sacrifices instant freshness for efficiency; real-time gives freshness at the cost of latency guarantees and higher expense.
- Cost: batch often cheaper per prediction because of bulk processing; real-time can be costlier due to always-on infrastructure and complex scaling.
- Scalability & tooling: batch → Spark/Hadoop/Dataproc/Airflow; real-time → Kafka/Kinesis, Flink, Spark Streaming, serverless functions, low-latency model servers (TorchServe, TensorFlow Serving, Triton).
- Complexity & ops: real-time requires robust monitoring, autoscaling, and low-latency feature access; batch systems are simpler to test and easier to reproduce.
- Accuracy vs availability: sometimes real-time models use simpler features or approximations to meet latency SLAs, which can impact accuracy.
Infrastructure examples
- Batch stack: Hadoop, Spark, Airflow, Beam (batch mode), scheduled ETL jobs, batch model scoring on clusters.
- Real-time stack: Kafka/Kinesis for event streams, Flink or Spark Structured Streaming for processing, feature stores with low-latency reads, model servers, API gateways or edge inference.
Monitoring, drift detection & retraining cadence
- Batch: periodic evaluation (daily/weekly), scheduled drift checks, retraining pipelines triggered by drift thresholds or time windows.
- Real-time: continuous monitoring of input distributions, prediction distributions, latency, error rates, and online drift detectors. Alerts and automated rollback procedures are critical.
How to answer this in an interview (concise + expanded)
One-line answer (30–60s):
"Use batch predictions when low latency isn’t required and you need cost-efficient, high-throughput scoring (e.g., nightly analytics). Use real-time predictions when decisions must be made immediately (fraud, recommendations), accepting higher operational complexity and cost."
Expanded answer (90–120s):
"I’d choose batch if the use case tolerates hours of latency and benefits from bulk processing — it’s cheaper per prediction and simpler to operate. I’d pick real-time if the system needs sub-second responses or fresher features; this requires streaming infrastructure, low-latency feature access, and continuous monitoring. In practice I’d ask about SLA, throughput, cost constraints, and model freshness requirements before deciding."
Include a short follow-up question for the interviewer: "What is the acceptable latency and expected traffic pattern?" — that shows you focus on constraints.
Interview checklist (quick)
- Required latency (ms/s/min/hr)
- Expected throughput / QPS
- Cost constraints and budget model
- Model freshness and retraining cadence
- Stateful features or windowed aggregations
- Regulatory / reproducibility requirements
- Failure-handling and rollback expectations
Final takeaway
Interviewers want to hear a balanced decision that ties technical trade-offs to business constraints. State the differences clearly, mention the infrastructure and monitoring implications, and finish by asking about SLAs and traffic patterns.
#MachineLearning #MLOps #DataEngineering

