
Stop Guessing in ML Interviews: A 5-Step Model Choice Framework

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Stop Guessing in ML Interviews: A 5-Step Model Choice Framework
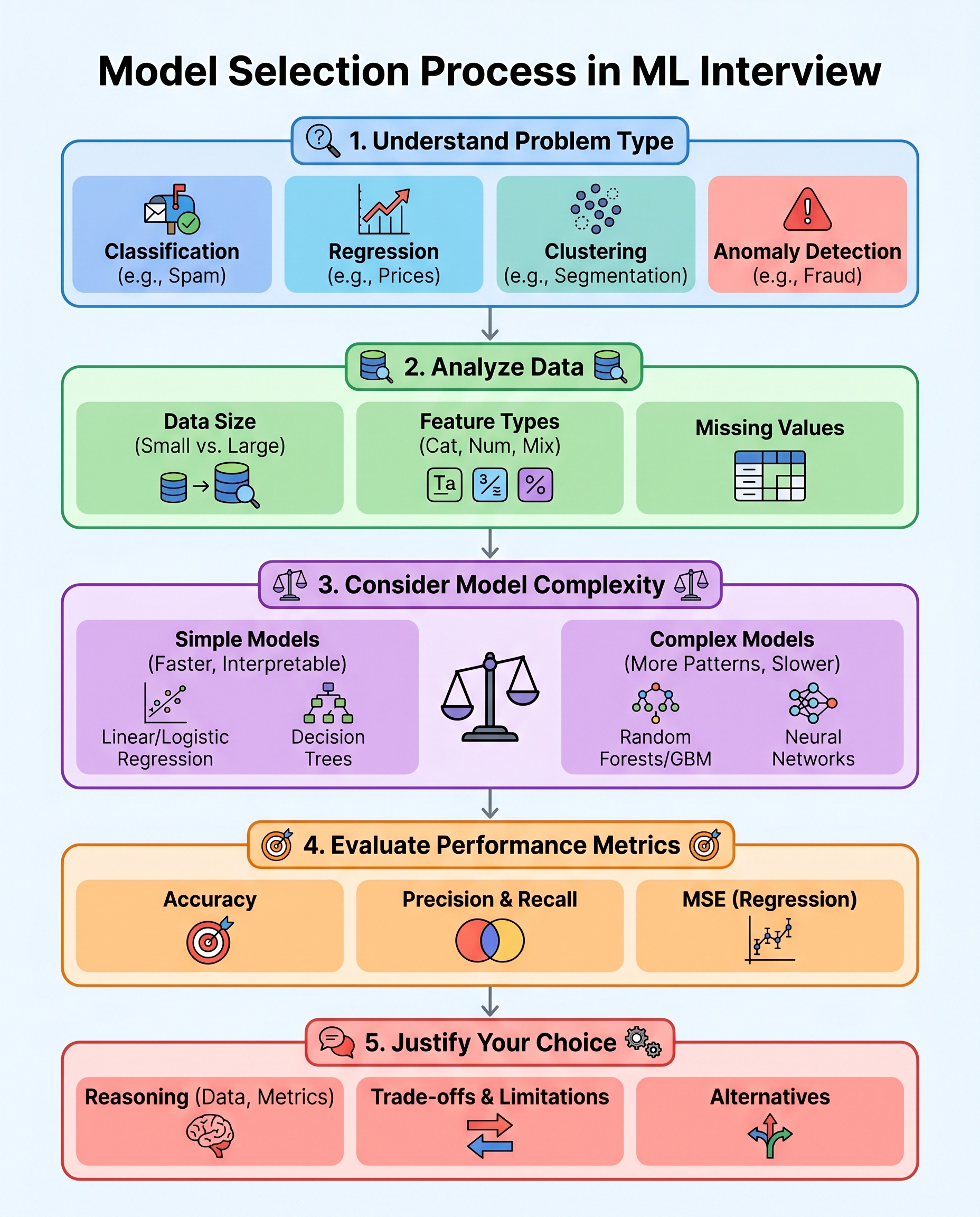
Model selection in interviews isn’t about lucky guesses — it’s about clear reasoning. Use this compact, repeatable 5-step framework to choose a model, justify it, and show interviewers you understand trade-offs.
1) Define the task
Start by naming the problem clearly. Common categories:
- Classification (binary / multiclass)
- Regression
- Clustering
- Anomaly detection
- Time-series forecasting
Why it matters: the task limits which algorithms and evaluation metrics make sense. In an interview, state the task up front: "This is a binary classification problem (fraud vs. not fraud)."
2) Read the data
Quickly summarize the dataset and call out red flags:
- Size: number of rows — tiny (<1k), moderate, large (100k+)
- Feature types: numeric, categorical, text, images
- Missing values and outliers
- Class balance for classification problems
- Label quality/noise
Interview tip: verbalize constraints: "We have ~5k samples, mostly tabular with some missingness — that suggests simpler models or careful regularization."
3) Match model complexity to the data
Choose models aligned with data quantity, noise, and problem complexity:
- Small / clean datasets: linear models, logistic regression, decision trees with pruning
- Moderate datasets with nonlinearity: tree ensembles (random forest, gradient boosting)
- Large datasets or complex feature types (images, text): deep learning
- High interpretability requirement: linear models, decision trees, or explainable boosting machines
Always mention compute/time constraints: "If we need a quick prototype or limited compute, I’d start with logistic regression or a light GBM."
4) Pick the right metric — and call out pitfalls
Choose a metric that aligns with business goals and the data:
- Accuracy: OK for balanced classes, but misleading with imbalance
- Precision / Recall / F1: use when false positives vs false negatives matter
- ROC-AUC: good general ranking metric; can be misleading on highly imbalanced datasets
- Precision@K or average precision: useful for top-k/budgeted actions
- MSE / RMSE / MAE: for regression (MAE is more robust to outliers)
In an interview, justify the metric: "We should prioritize recall because missing a positive has high cost."
5) Justify trade-offs and propose alternatives
Explain why you chose a model and what you’d try next:
- Accuracy vs interpretability: "I pick logistic regression for interpretability; if performance lags, I’d try XGBoost and use SHAP for explanations."
- Speed vs performance: "A light GBM is a good balance for production latency; if latency isn’t critical, I’d consider a larger neural net."
- Overfitting vs bias: "If we see high variance, I’ll add regularization or use an ensemble; if underfitting, increase model capacity or add features."
Also present fallback plans: cross-validation strategy, feature engineering ideas, and monitoring approach after deployment.
Quick interview-ready templates
Keep these short lines ready to say when asked "Why this model?":
- "Given the dataset is small and the business needs explainability, I’d start with logistic regression."
- "We have non-linear relationships and moderate data; a tree-based ensemble like XGBoost is a strong first choice."
- "For high-dimensional text data with lots of labeled examples, I’d consider a transformer-based model or an LSTM depending on sequence length."
Common pitfalls to call out
- Choosing a complex model without enough data
- Optimizing accuracy on imbalanced classes
- Ignoring label quality
- Forgetting latency/computation constraints for production
One-minute checklist to state in interviews
- Task: [classification/regression/...]
- Data: [size, types, missingness]
- Model choice: [model + one-sentence justification]
- Metric: [primary metric and why]
- Trade-offs: [what you accept and one alternative]
If you can succinctly explain "why this model," the interviewer knows you can reason beyond memorized names.
Happy practicing — explain your choices, not just the algorithm name.
#MachineLearning #DataScience #TechInterviews

