
ETL vs ELT: The Interview Question That Exposes Real Data Engineering Skill

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
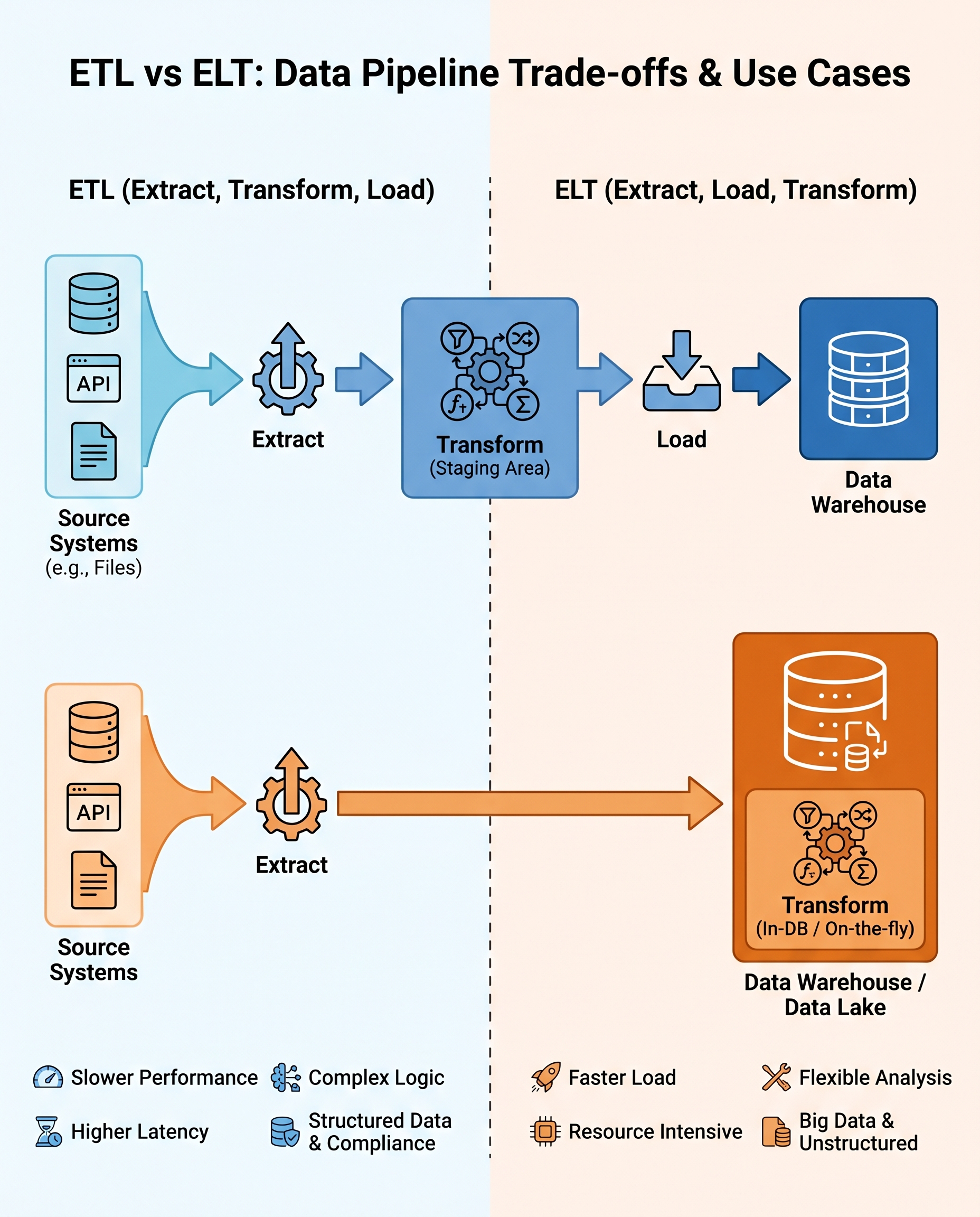
ETL vs ELT: The Interview Question That Exposes Real Data Engineering Skill
ETL (Extract → Transform → Load) and ELT (Extract → Load → Transform) are two fundamental patterns in data engineering. Interviews often use this question to probe whether you can reason about trade-offs — not just recite definitions.
Below is a concise, interview-ready explanation plus practical guidance you can use to justify a design choice.
Quick definitions
- ETL: extract data from sources, transform it (clean, validate, enforce schema/governance), then load the cleaned data into the target (data warehouse or marts). Best when governance, data quality, or compliance must be enforced before storage.
- ELT: extract and load raw data into the warehouse first, then perform transformations inside the warehouse (or query engine). Best when you want fast access to raw data and flexible analytics.
Pros and cons (at a glance)
ETL
- Pros: Enforces data quality and governance before data reaches consumers; predictable schema in the warehouse; keeps compute costs off the warehouse.
- Cons: Adds latency before data is available; pipeline logic can be complex; harder to reprocess when source schema changes.
ELT
- Pros: Faster time-to-access for analysts; flexible exploratory transformations; leverages scalable warehouse compute for transformations; easier to re-run or create multiple derived datasets.
- Cons: Can raise compute costs inside the warehouse; risk of inconsistent raw data if governance isn't enforced; increased need for access controls and cost monitoring.
Decision criteria you should cite in interviews
When asked which you'd choose, justify your decision using these concrete factors:
- Data volume and growth
- Very large, continuous streams or extremely high daily volume may favor designs that minimize warehouse compute (consider ETL with pre-aggregation or streaming transformations). For manageable or bursty volumes, ELT can be efficient.
- SLA / latency requirements
- If data must be available within seconds or minutes (real-time analytics), consider streaming transformations or ELT with incremental loads; if strict validation is required before use, ETL might be needed despite added latency.
- Transformation complexity and reusability
- Complex, multi-step canonicalization and business rules that must be enforced consistently across products favor ETL. If analysts need flexible, ad-hoc derivations, ELT provides better agility.
- Cost model and tooling
- Consider where compute is cheaper or easier to scale (your ETL cluster vs warehouse compute). Also consider licensing, operational overhead, and team expertise.
- Governance, compliance, and security
- Sensitive PII or regulatory requirements often mandate early masking, validation, or lineage tracking — strong reasons to prefer ETL or a hybrid pattern with pre-load enforcement.
- Schema stability and evolution
- If sources change often, having raw data (ELT) can help with replay and debugging; if you require strict schema guarantees, ETL can normalize before storage.
A short, interview-friendly answer (pick and adapt)
If asked to choose on the spot, use this template and adapt specifics:
- "I'd choose [ETL/ELT] because of X, Y, and Z. Specifically: (1) Our data volume is [low/medium/high], (2) our SLA requires [low/medium/high] latency, and (3) transformations are [simple/ad-hoc/complex and business-critical]. Given that, [ETL/ELT] minimizes risk and meets our performance/cost/governance goals. I'd also implement [a hybrid pattern/strong monitoring/cost controls] to handle edge cases."
Example: ETL answer
- "I'd use ETL for this product because we must enforce PII masking and strict validation before any consumer can access data. Latency requirements are moderate, and the transformation rules are non-trivial and shared across teams. To reduce operational friction I'd implement reproducible pipelines, schema validation, and automated tests."
Example: ELT answer
- "I'd use ELT here since analysts need quick access to raw events and transformation requirements are exploratory and changing. We'll store raw data with clear lineage, use warehouse-native transformation jobs (dbt or similar), and add cost controls and governance policies to avoid runaway compute."
Practical patterns & best practices
- Hybrid approach: enforce critical validations (PII redaction, schema checks) during ingestion, then load raw (or semi-raw) data and perform business transformations in the warehouse.
- Keep raw/landing zones immutable so you can always replay or reprocess data.
- Use declarative transformation tooling (dbt, Spark SQL, etc.) for reproducibility and testing.
- Monitor warehouse compute and set alerts/cost budgets to avoid unexpected bills with ELT.
- Implement data contracts, automated tests, and lineage to reduce ambiguity and accelerate troubleshooting.
- For real-time use cases, consider streaming ETL or change-data-capture with incremental transformations.
Closing tip for interviews
Don't present ETL vs ELT as a binary, ideological choice. Show that you can evaluate requirements, reason about trade-offs (latency, cost, governance, flexibility), and design a pragmatic solution — often a hybrid — that fits the product constraints.
#DataEngineering #ETL #ELT

