
Stop Guessing in ML Interviews: A 5-Step Model Choice Framework

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Stop Guessing in ML Interviews: A 5-Step Model Choice Framework
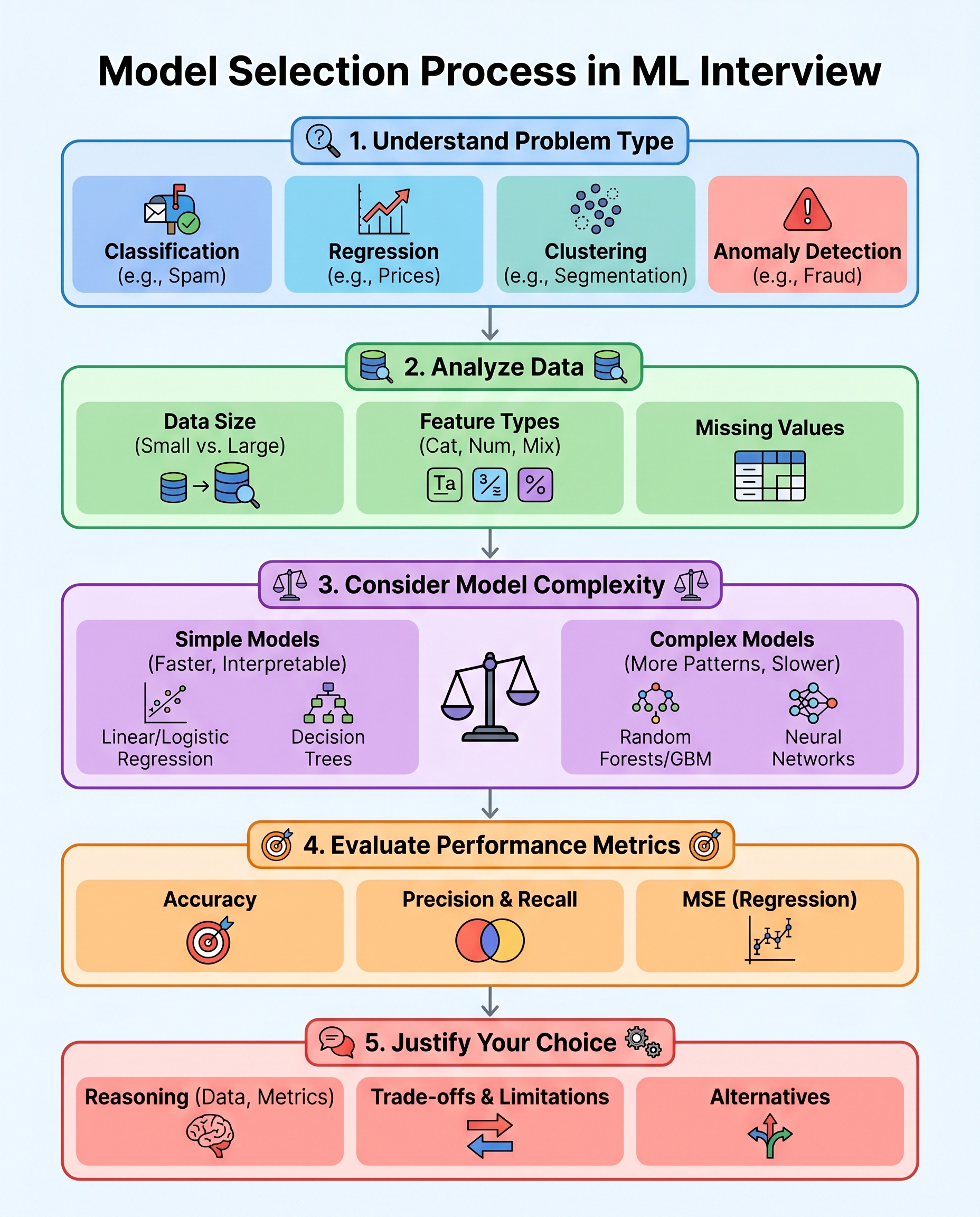
Model selection in interviews isn't about intuition or luck — it's about a clear, repeatable reasoning process. Use this 5-step framework to structure your answer, show that you think like an engineer, and justify your choices.
1) Define the task
Start by naming the problem type and edge cases.
- Classification (binary, multiclass, multilabel) — e.g., spam vs not-spam.
- Regression — predict continuous values like price or temperature.
- Clustering — unsupervised grouping when labels aren't available.
- Anomaly detection — rare-event detection or outlier scoring.
- Other: ranking, forecasting, survival analysis, or multi-task problems.
Quick interview tip: restate the objective and any constraints (latency, interpretability, cost) before proposing models.
2) Read the data
Describe what's in the dataset and what matters for modeling.
- Size: number of samples (small vs large) guides model complexity.
- Feature types: numerical, categorical, text, images, time series.
- Missing values, duplicates, label quality, and leakage risks.
- Class imbalance and how skewed the target is.
Actionable note: if the dataset is small or labels are noisy, favor simpler models and focus on feature engineering and cross-validation.
3) Match complexity to the problem
Choose model families based on data richness and constraints.
- Start with baselines: logistic/linear regression, decision trees, k-NN.
- If patterns are non-linear and data is moderate: tree ensembles (Random Forest, XGBoost/LightGBM).
- For very large labeled datasets or unstructured data: neural networks (CNNs for images, transformers for text).
- Consider interpretability, training time, memory, and deployment complexity.
Rule of thumb: try a simple interpretable model first — if it fails, ramp up complexity with clear reasons.
4) Pick the right metric
Tie the evaluation metric to business goals and class properties.
- Classification: accuracy (only if balanced), precision/recall, F1, AUROC, AUPRC (preferred for imbalanced data).
- Regression: MAE, MSE/RMSE, R² — choose based on sensitivity to outliers.
- Other metrics: calibration, ranking metrics (NDCG), or business KPIs (conversion, revenue).
Interview tip: explain consequences of optimizing the wrong metric (e.g., high accuracy but poor recall on rare positive cases).
5) Justify trade-offs and propose alternatives
Explain why your choice balances performance, cost, and risk.
- Interpretability vs performance: when stakeholders need explanations, prefer simpler or explainable models.
- Latency and footprint: for real-time systems, prefer lightweight models or distilled networks.
- Data and labeling costs: semi-supervised learning, transfer learning, or active learning when labels are expensive.
- Deployment and maintenance: consider model updates, monitoring, and data drift.
Always propose a short experimental plan: baseline → tuned model → ablation tests → monitoring.
Quick interview checklist (what to say)
- "This is a [task type]."
- "The data looks like X (size, types, issues)."
- "Baseline: [simple model]. If needed, escalate to [ensemble/NN] because..."
- "I'll evaluate with [metric] because..."
- "Trade-offs: [list], and next steps would be..."
If you can clearly explain "why this model" and how you would validate it, you’re interview-ready.
—
Tags: #MachineLearning #DataScience #TechInterviews

