
API Pagination & Filtering: The Interview-Ready Design Choices

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
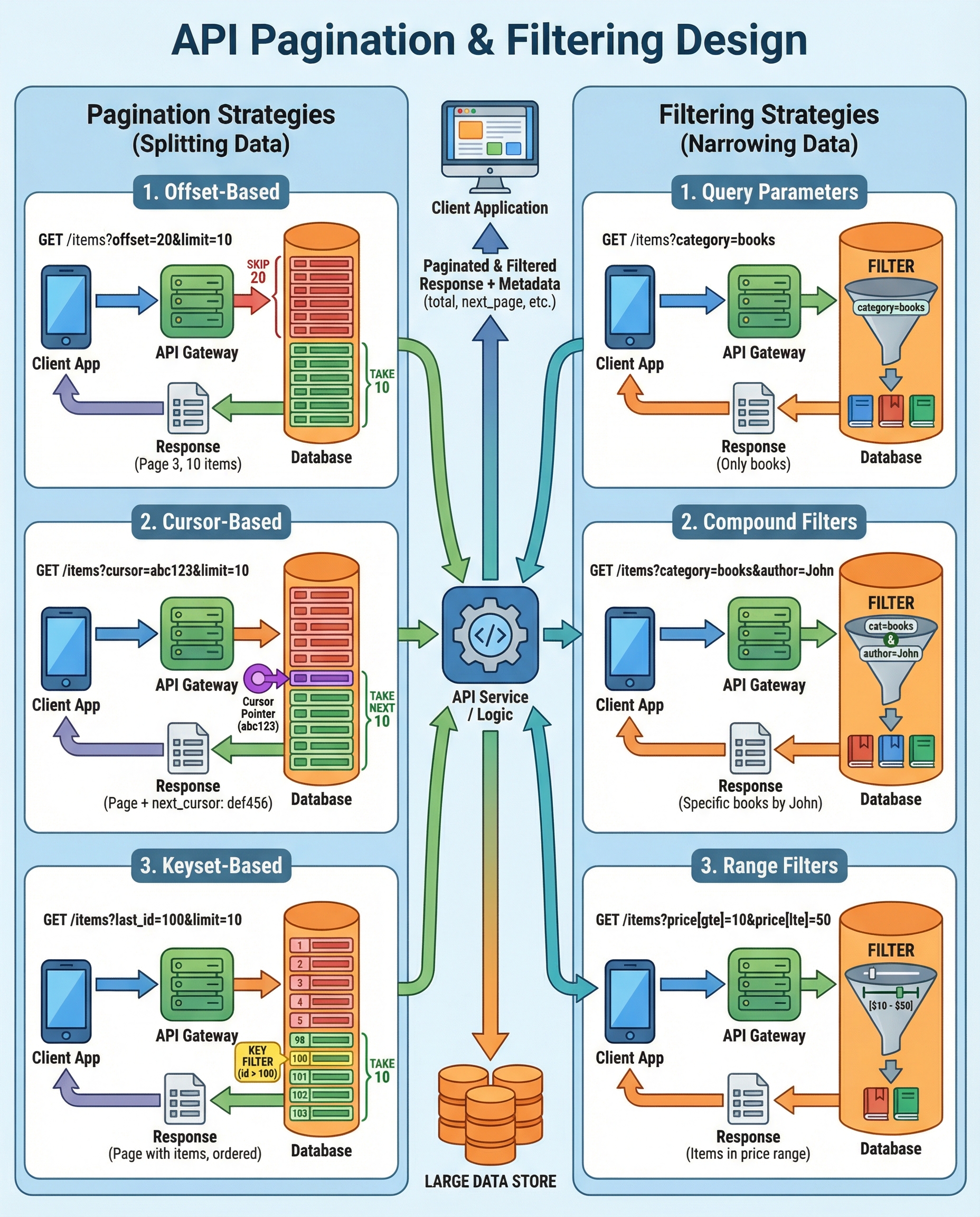
API Pagination & Filtering: The Interview-Ready Design Choices
If your API serves large datasets, pagination and filtering are not optional UI conveniences — they are essential performance controls. This guide explains the trade-offs, patterns, and implementation details you should know for interviews and real projects.
Why pagination and filtering matter
- Protects servers and databases from large, expensive queries.
- Reduces payload size and latency for clients.
- Enables predictable UX for browsing long lists.
- With the right design, they scale as your dataset grows.
Pagination strategies
Two common pagination patterns: offset/limit and cursor (keyset).
1) Offset / Limit
- Example request:
/products?limit=20&offset=100 - Pros: simple to implement and reason about.
- Cons: performance degrades as offset grows — the database often scans or counts many rows. Can return duplicate/skipped items if underlying data changes while paginating.
When to use: small datasets, admin UIs, or endpoints where deep paging is rare.
2) Cursor / Keyset (recommended at scale)
- Uses a stable sort key (typically an indexed column like
idorcreated_at) and a cursor token rather than offset. - Example request:
/events?limit=50&cursor=eyJpZCI6IjEyMzQifQ== - Backend pattern (SQL):
-- assume ordering by created_at DESC, id DESC
SELECT *
FROM events
WHERE (created_at, id) < (:last_created_at, :last_id)
ORDER BY created_at DESC, id DESC
LIMIT 50;
- Pros: stable and fast at scale because it leverages indexes and avoids large offsets.
- Cons: slightly more complex (requires opaque cursor encoding and careful ordering). Not suitable for arbitrary jumps ("go to page 10") unless you maintain mapping.
When to use: user feeds, long timelines, any high-volume list where deep paging occurs.
Filtering: query param design
Design clear, consistent query parameters that make filtering intuitive and indexable.
Examples:
- Simple equality filters:
/products?category=shoes&brand=nike - Numeric ranges:
/products?price_min=50&price_max=200 - ISO date ranges or bracketed style:
/orders?created_at[gte]=2023-01-01&created_at[lte]=2023-01-31 - Boolean flags:
/users?is_active=true - Multi-value params:
/articles?tag=react&tag=javascript(OR semantics) ortags=react,javascript(client/server agreement needed)
Best practices:
- Use predictable param names: category, price_min/price_max or created_at[gte]/[lte].
- Prefer ISO 8601 for dates.
- Support compound filters (combine multiple params) but ensure indexes support the common access patterns.
- Avoid deep, ad-hoc filtering that can't be indexed — that will degrade performance.
Indexing tip: create indexes on frequently filtered columns and consider composite indexes (e.g., (user_id, created_at)) when filters and ordering are commonly used together.
Response metadata you must return
Always include pagination metadata so clients can navigate and handle edge cases.
Minimal recommended fields for cursor pagination:
{
"data": [ /* items */ ],
"next_cursor": "eyJpZCI6IjEyMzQifQ==",
"has_more": true
}
For offset pagination, include page info:
{
"data": [ /* items */ ],
"page": 5,
"per_page": 20,
"total": 1234,
"total_pages": 62
}
Notes:
- For cursor APIs, avoid returning
totalwhen it's expensive to compute.has_moreor presence/absence ofnext_cursorsuffices. - Provide consistent cursor encoding (opaque tokens) so clients don’t depend on internal DB fields.
Rules & hard limits (opinions you should defend in interviews)
- Cap the maximum
limit(e.g., 100) to avoid huge payloads. - Validate and sanitize filter params to prevent injection.
- Enforce stable ordering for cursor pagination (e.g., created_at DESC, id DESC) so results are deterministic.
- Document example queries and responses clearly in your API docs.
- Return useful HTTP cache headers where appropriate (ETag, Cache-Control).
Implementation tips
- Encoding cursors: pack the last row's ordering values into a small JSON object and base64-encode it (opaque to clients).
- When filtering by range + ordering, make sure the index supports the WHERE and ORDER BY pattern to avoid full table scans.
- Consider background counting or approximate counts if total is required but expensive.
- For realtime feeds, use server-generated tokens to handle deletions/insertions gracefully.
Example: cursor flow
- Client requests first page:
/messages?limit=50 - Server returns 50 items and
next_cursor. - Client requests next page:
/messages?limit=50&cursor={next_cursor} - Server decodes cursor and uses it in the WHERE clause to fetch the next slice.
Sample response:
{
"data": [{ "id": 501, "text": "..." }, { "id": 500, "text": "..." }],
"next_cursor": "eyJhIjo1MDB9",
"has_more": true
}
Quick checklist for interviews
- Explain the trade-offs between offset and cursor pagination.
- Show an example query and a sample JSON response with metadata.
- Describe how you’d encode and decode a cursor safely.
- Mention indexing decisions for common filters and sorts.
- State limits (max page size) and why you’d avoid exposing raw DB offsets for deep pages.
Pagination and filtering are foundational API design choices. With the right patterns — cursor pagination for scale, clear filter conventions, index-aware queries, capped limits, and good metadata — your API will be both efficient and predictable.
If you want, I can generate example SQL queries and cursor encoding/decoding snippets in the language of your choice (Node, Python, Go, etc.).

