
Distributed ID Generators: The Clock Rollback Trap You Must Address

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
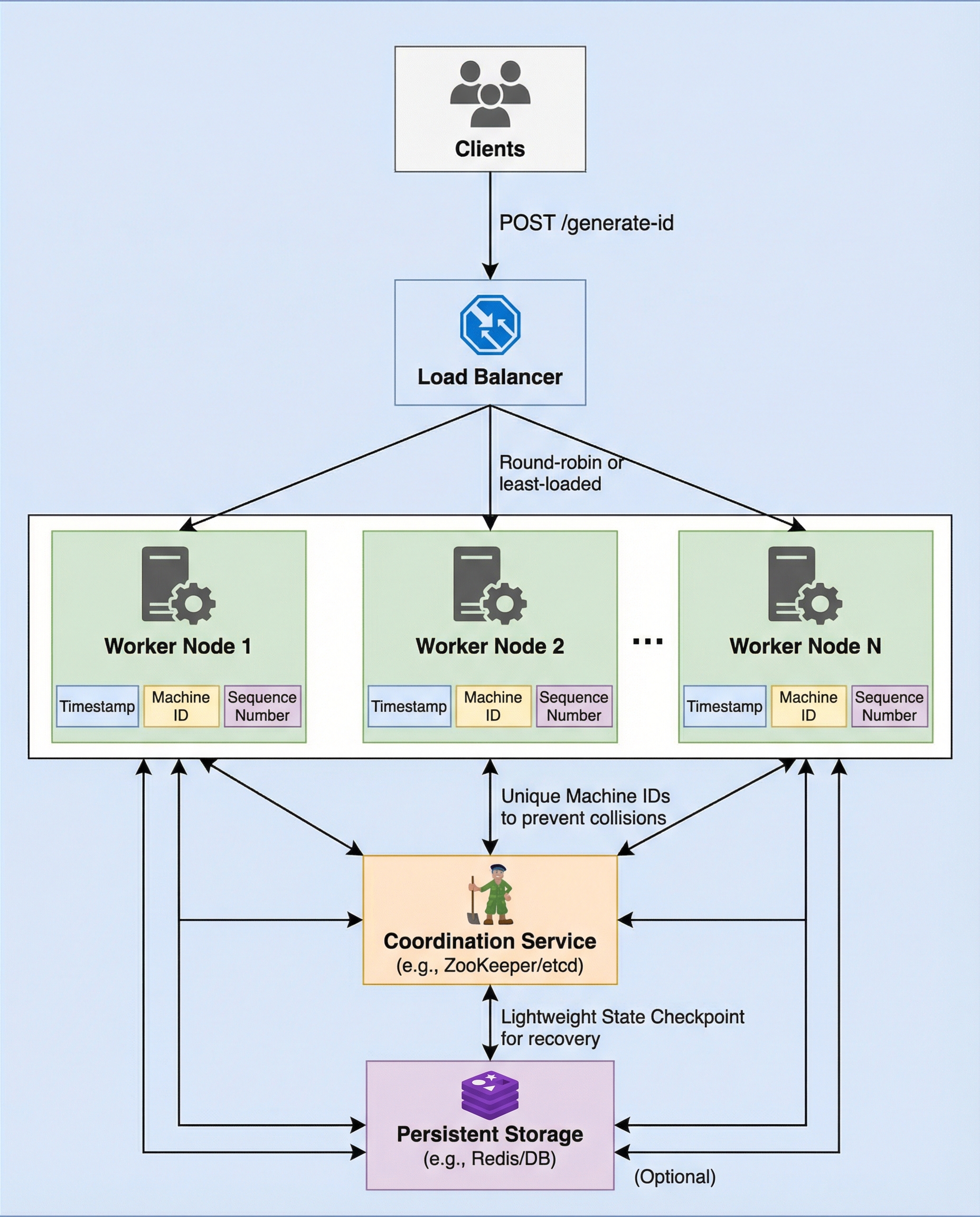 {:style="max-width:800px;height:auto;"}
{:style="max-width:800px;height:auto;"}
Distributed ID Generators: The Clock Rollback Trap You Must Address
Distributed, Snowflake-style ID generators rely on the system clock to produce time-ordered, unique IDs. That dependency is convenient and efficient — until a node's clock moves backward. When that happens you risk generating duplicate IDs, breaking monotonic ordering, and introducing hard-to-debug correctness issues into your system.
This post explains the problem, the simple rule you must state and enforce in interviews and production code, and practical mitigations to make your ID generator safe and robust.
The problem in one sentence
If current_timestamp < last_timestamp, a worker must stop issuing IDs until the clock catches up (or switch to a safe fallback). Also persist last_timestamp so a restart doesn't "forget" progress and reissue old ranges.
Why clock rollback is dangerous
Snowflake-like IDs typically embed: timestamp | worker_id | sequence. If the timestamp component moves backwards:
- IDs may collide (same timestamp + same worker_id + same sequence).
- Global monotonic order is violated — downstream consumers relying on time ordering will be surprised.
- Hard-to-reproduce bugs appear after restarts, clock corrections, VM snapshots, or misconfigured NTP.
A single node with a backward clock can undermine the ID guarantees for the entire system.
The clear rule to follow
Always implement and communicate this rule clearly in interviews and docs:
- If current_timestamp < last_timestamp, stop issuing IDs until current_timestamp >= last_timestamp.
- If you cannot wait, switch to a safe fallback (see options below).
- Persist last_timestamp across restarts so the node does not revert to reusing old timestamp ranges.
This is the minimal, correct behavior.
Fallback strategies (when waiting is unacceptable)
If blocking ID generation is not acceptable, consider one of these safe fallbacks rather than issuing timestamps that go backward:
- Use a reserved higher-order bit (or worker-local counter) to indicate a "clock-wrap" and ensure uniqueness, but this complicates ordering guarantees.
- Use a logical counter appended to the ID (e.g., bump a monotonic counter while the clock is behind). This preserves uniqueness but breaks pure time ordering.
- Delegate a short-lived range of IDs from a central allocator (one node temporarily becomes authoritative) — reduces how long you must wait.
- Switch to hybrid logical clocks (HLC) or Lamport clocks which combine physical and logical time to preserve causality when clocks drift.
Each fallback trades monotonic timestamp ordering for availability or additional complexity — choose according to your system's priorities.
Persisting last_timestamp: why and how
If a node restarts and loses its in-memory last_timestamp, it may start issuing IDs with timestamps earlier than those it issued before the restart. Persist last_timestamp to durable storage so restarts don't cause reuse of old timestamp ranges.
Persistence options:
- Append-only file or small metadata file written atomically (fsync/rename) on timestamp changes.
- Local embedded database (SQLite/LevelDB) with durable writes.
- Distributed coordination store (etcd/ZooKeeper/Consul) if you already use one and want cross-node guarantees.
Trade-offs:
- Writing to disk on every single ID issuance is expensive — instead persist when the timestamp increments (i.e., on boundary transitions) or periodically plus during graceful shutdown.
- For maximum safety (no chance of reuse even after a crash), persist the new last_timestamp before returning IDs that depend on it. This is slower but safest.
Example pseudocode (safe, blocking approach):
function next_id():
now = current_time_ms()
if now < last_timestamp:
// Rule: do not emit IDs until time catches up
wait_until(last_timestamp)
now = current_time_ms()
if now == last_timestamp:
sequence = (sequence + 1) & sequence_mask
if sequence == 0:
// sequence overflow: wait until next millisecond
wait_until(next_millisecond)
now = current_time_ms()
else:
sequence = 0
last_timestamp = now
persist_last_timestamp(last_timestamp) // durable write or periodic flush
return compose_id(now, worker_id, sequence)
Notes on persistence: persist_last_timestamp should be atomic. A safe pattern is to write to a temp file and rename, or use an embedded DB that guarantees durable commits.
Operational mitigations
- Configure time synchronization software (chrony recommended) to slew the clock instead of stepping when possible. Stepping the clock backward is the main root cause.
- Avoid restoring snapshots of VMs with older clocks without advancing the clock first.
- Use monotonic clocks for measuring intervals (but be careful: monotonic clocks don't map to wall-clock timestamps embedded in IDs).
- Add alerts when a node's clock jumps backward or when ID generator starts blocking for time.
Alternatives to Snowflake-style timestamps
If you want to avoid the clock problem entirely, consider alternatives:
- ULID: lexicographically sortable, but still depends on clock correctness.
- UUIDv1: includes timestamp and node identifiers (similar problems).
- HLC (Hybrid Logical Clock): preserves causality and is resilient to clock skew.
- Centralized ID allocator: single place that hands out ranges — simpler but a single point of failure unless replicated.
Summary checklist
- Implement the rule: if current_timestamp < last_timestamp, do not emit IDs.
- Persist last_timestamp so restarts don't reuse old timestamps.
- Choose a fallback (wait, logical counter, central allocator, HLC) based on ordering vs availability needs.
- Harden ops: use chrony, monitor clock jumps, avoid VM snapshot pitfalls.
- Consider HLC or other schemes if you need stronger causal guarantees.
Clock rollback is one of those subtle issues that bites in production. Stating the rule clearly in interviews and enforcing it in code will save you from duplicate IDs, broken ordering, and late-night incident responses.

