
Heteroskedasticity: OLS Coefficients Stay Unbiased—So Why Can Your Conclusion Be Wrong?

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
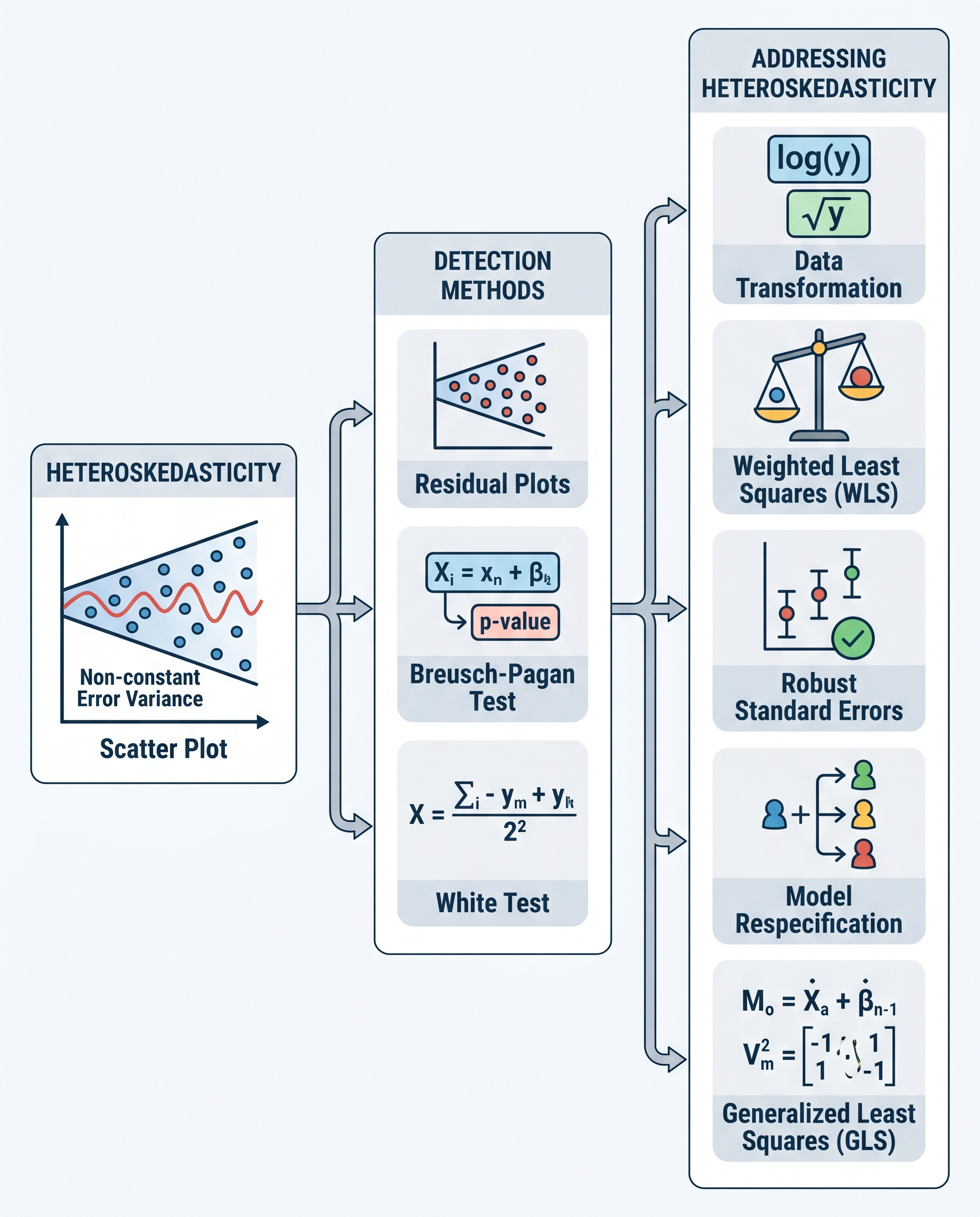
Quick takeaway
Heteroskedasticity does not generally bias OLS coefficient estimates, but it does make the usual standard errors (and therefore t-tests and confidence intervals) unreliable. The fix is usually to keep the estimated coefficients and use heteroskedasticity-robust (sandwich) standard errors for valid inference.
What is heteroskedasticity?
Heteroskedasticity means the variance of the error term changes with covariates: Var(u | X) is not constant. In many real-world datasets the spread of residuals grows or shrinks with certain predictors (e.g., income dispersion rising with age, measurement noise increasing with magnitude).
Why OLS coefficients remain unbiased
Unbiasedness of OLS estimates rests primarily on the assumption E[u | X] = 0 (errors have zero conditional mean). That condition can hold even if Var(u | X) varies with X. So the point estimates β̂ produced by OLS remain (conditionally) unbiased and consistent under heteroskedasticity.
Why inference breaks
The usual OLS standard error formula assumes homoskedasticity (constant variance). Under homoskedasticity:
Var(β̂) = σ² (X'X)^{-1}.
When errors are heteroskedastic the true variance becomes:
Var(β̂) = (X'X)^{-1} X'ΩX (X'X)^{-1},
where Ω is a diagonal matrix of error variances. If you keep using the homoskedastic formula you get wrong standard errors — often underestimating or overestimating uncertainty. That leads to misleading t-statistics, p-values, and confidence intervals: you might falsely declare effects significant (Type I error) or miss real effects (Type II error).
Fast fixes and best practices
- Use heteroskedasticity-robust (sandwich) standard errors. These adjust the estimated Var(β̂) to account for varying error variance and restore valid hypothesis testing.
- Popular robust estimators: HC0, HC1, HC2, HC3 (HC3 often recommended in small samples because it's more conservative).
- Consider clustering if observations are correlated within groups (cluster-robust SEs).
- Run diagnostic tests to detect heteroskedasticity (e.g., Breusch–Pagan, White test) — but even if you skip tests, robust SEs are inexpensive and usually appropriate as a precaution.
Quick code examples
In Python (statsmodels):
from statsmodels.api import OLS res = OLS(y, X).fit(cov_type='HC3')
In R (sandwich & lmtest):
library(sandwich); library(lmtest) model <- lm(y ~ X) coeftest(model, vcov = vcovHC(model, type = "HC3"))
Practical tips
- Report robust standard errors in applied work when heteroskedasticity is plausible.
- If data are clustered (e.g., students within schools), use cluster-robust SEs rather than simple heteroskedasticity-robust SEs.
- In very small samples be cautious: some robust methods still rely on large-sample approximations; prefer HC3 or permutation/bootstrap approaches when appropriate.
Bottom line
Heteroskedasticity rarely ruins your β̂ — but it can wreck your inference. The simplest reliable approach is to keep the OLS coefficients and use heteroskedasticity-robust (or cluster-robust) standard errors so your t-tests and confidence intervals are trustworthy.
#DataScience #Statistics #MachineLearning

