
Graph Systems Interview: Sharding Is Not Optional—It’s the Performance Lever

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Graph Systems Interview: Sharding Is Not Optional—It’s the Performance Lever
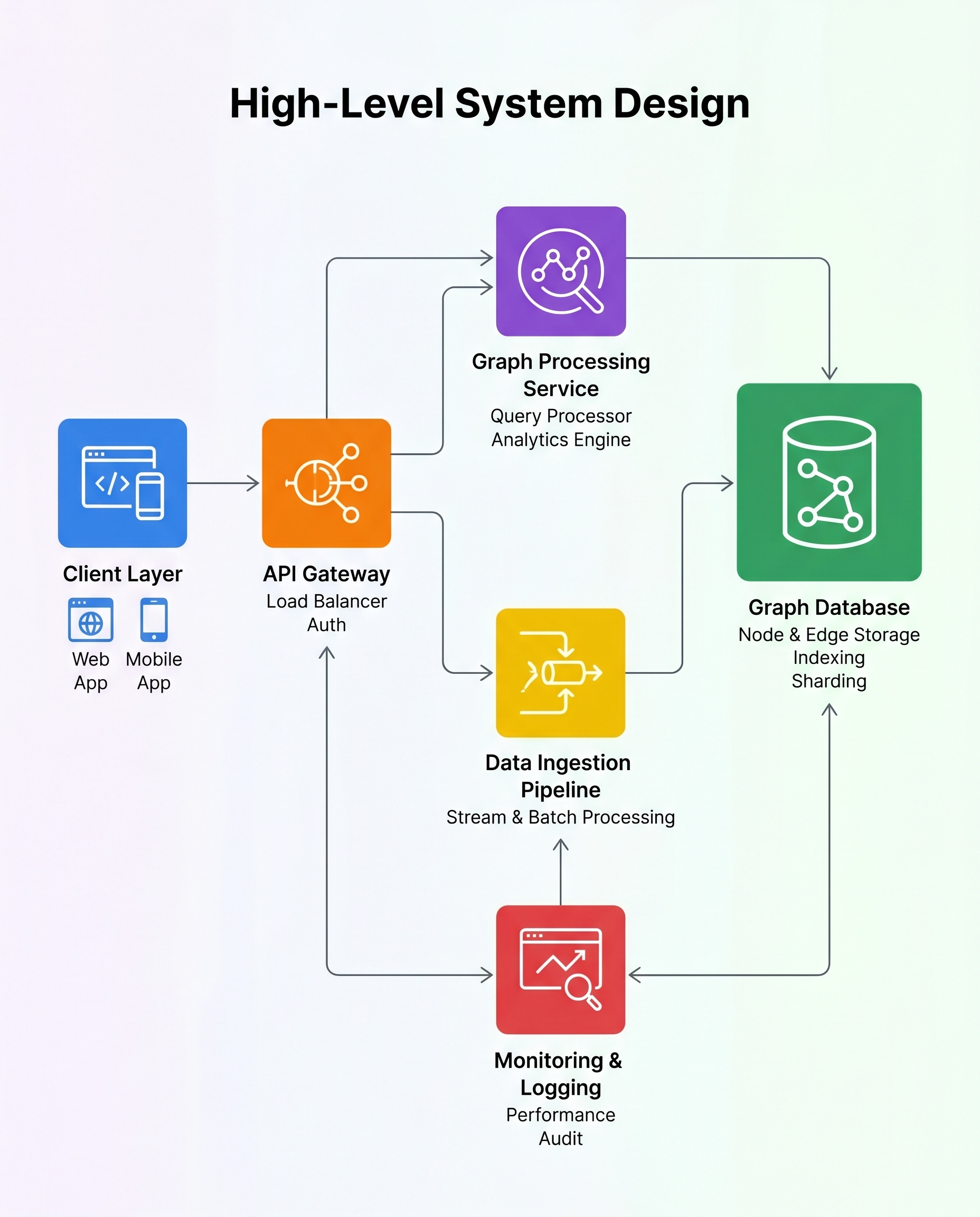
In large-scale graph systems, sharding isn't optional—it's the primary performance lever. A graph with a billion nodes and 10 billion edges cannot live on one machine, so you must partition it across servers. How you shard directly shapes traversal latency, throughput, and operational complexity.
Why sharding matters
- A good partitioning keeps traversals local, reducing cross-shard network hops.
- Fewer hops mean lower latency for breadth-first search (BFS), shortest-path queries, and other traversals that walk many edges.
- Better locality improves throughput under peak load because servers spend less time waiting on remote RPCs and more time processing.
In interviews, avoid saying only “we shard.” Always explain the how and the impact.
Common sharding strategies (and when to use them)
Hash by node_id
- Pros: simple, even distribution of nodes; good for balancing storage and baseline throughput.
- Cons: destroys locality—randomized neighbors likely spread across shards, increasing cross-shard hops.
Community / region-based partitioning
- Pros: groups tightly connected nodes together so typical traversals stay local; reduces cross-shard communication for social graphs, geospatial graphs, or domain-specific clusters.
- Cons: harder to compute and maintain; can create imbalance if some communities are much larger or hotter than others.
Vertex-cut (edge-based partitioning)
- Pros: useful for scale-free graphs with high-degree hubs (avoids placing extremely high-degree nodes entirely on one server); spreads edge processing across machines.
- Cons: requires coordination for replicated vertex state and can increase write complexity.
Hybrid and streaming partitioners
- Use heuristics or online algorithms (e.g., streaming or incremental partitioners) to balance load while preserving some locality.
Key trade-offs and metrics to discuss
When you describe a sharding approach, tie it to measurable traversal cost and operational metrics:
- Balance: per-shard node and edge counts (storage & CPU fairness).
- Edge-cut / communication volume: number of edges crossing shards—lower is better for locality.
- Latency impact: expected number of remote hops per traversal (BFS depth × cross-shard hop probability).
- Hotspots: skew in access patterns; how you detect and mitigate hot shards.
- Rebalancing cost: how state is moved or replicated when partitions change.
Mention concrete techniques: consistent hashing for smooth joins/leaves, METIS or label-propagation for community partitioning, or stream partitioners for low-latency ingestion.
Interview checklist — how to present your answer
- State that sharding is required and name your goal (e.g., minimize cross-shard hops while balancing load).
- Propose one or two concrete partitioning strategies (hash, community, vertex-cut) and when you'd pick each.
- Explain consequences: fewer cross-shard hops → lower traversal latency and higher throughput.
- Call out operational concerns: rebalancing, replication, hot-spot mitigation, and how to measure success.
- If possible, quantify (example: “With community partitioning we expect X% fewer cross-shard edges, reducing average BFS latency from Y ms to Z ms”).
Bottom line
Sharding is the single most important architectural decision for large graph systems. In interviews, tie your partitioning choices directly to traversal cost and operational metrics—don’t just state that you shard. Explain how the chosen strategy reduces cross-shard hops, lowers latency for traversals like BFS and shortest path, and increases throughput under peak load.
#SystemDesign #DataEngineering #GraphAnalytics

