
Unsupervised Feature Extraction: What Interviewers Expect You to Know

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
 {width="600"}
{width="600"}
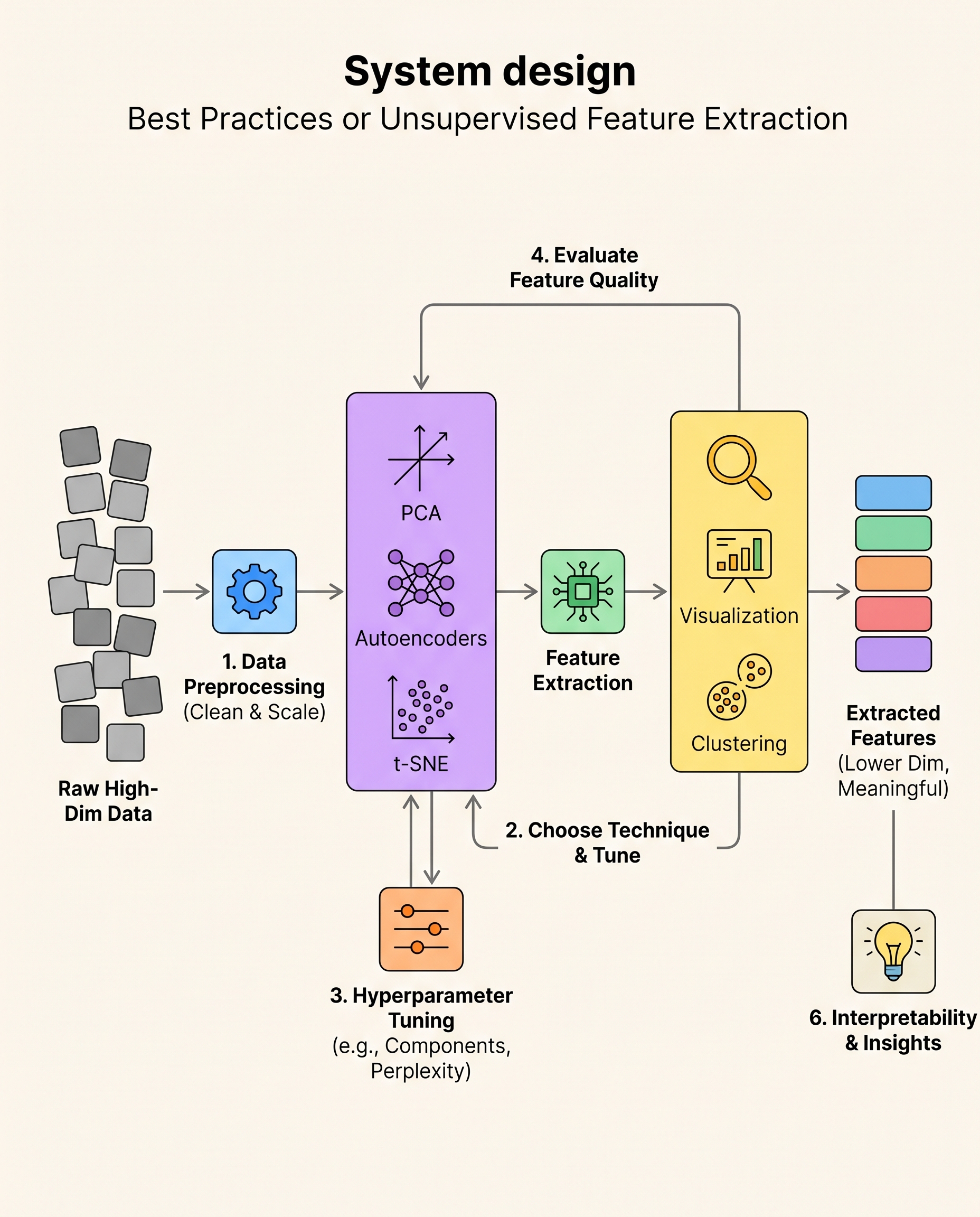
Unsupervised feature extraction turns high‑dimensional data into compact, informative representations—without labels. Interviewers will test both conceptual understanding and practical choices: preprocessing, method selection, hyperparameter tuning, validation, and interpretability.
Why interviewers care
Unsupervised feature extraction is a common step in pipelines for visualization, clustering, anomaly detection, and as a preprocessing stage for supervised models. Interviewers want to know you can:
- Choose an appropriate method for the problem and data.
- Explain trade-offs (speed vs. fidelity vs. interpretability).
- Validate that extracted features are useful.
1) Preprocess first (always)
Good representations start with clean inputs.
- Handle missing values: impute or mask depending on method.
- Scale features: standardize (zero mean, unit variance) for PCA/ICA; consider robust scaling if outliers exist.
- Normalize if using distance-based methods (t‑SNE, UMAP, K‑means).
- Optionally apply log or Box–Cox transforms to reduce skew.
Tip: Document preprocessing because downstream representations depend heavily on it.
2) Pick the right tool (and know why)
Common methods and when to use them:
- PCA — linear dimensionality reduction; fast, deterministic, and interpretable via loadings. Use for compression and noise reduction.
- t‑SNE — non‑linear visualization (2D/3D). Preserves local structure, but not global distances; stochastic and computationally expensive on large datasets.
- UMAP — faster alternative to t‑SNE that often preserves more global structure; good for visualization and as a preprocessing step for clustering.
- Autoencoders — neural networks that learn non‑linear embeddings. Flexible for complex manifolds and scalable with data; require more tuning and training data.
- ICA — separates independent sources; useful when signals are statistically independent (e.g., EEG).
- NMF — parts-based, non-negative representations; useful for interpretability in domains like text or images.
Be ready to justify your choice by linking method assumptions to data characteristics.
3) Tune key hyperparameters
Interviewers expect awareness of the most impactful knobs:
- PCA: number of components (explained variance threshold, scree plot, cumulative variance).
- t‑SNE: perplexity (roughly related to neighborhood size), learning rate, number of iterations, initialization.
- UMAP: n_neighbors (local vs. global structure), min_dist (compactness), metric.
- Autoencoders: bottleneck size, architecture depth/width, activation functions, regularization (dropout, L1/L2), training epochs.
Explain how you decide values: grid search, cross-validation on downstream tasks, visual inspection, or elbow-method heuristics.
4) Validate feature quality
You must show features are useful — interviewers expect concrete validation steps:
- Visualization: scatterplots (PCA/UMAP/t‑SNE) colored by known labels or metadata.
- Clustering: run K‑means or hierarchical clustering on embeddings; evaluate with silhouette score, Davies–Bouldin, or adjusted Rand index if labels exist.
- Downstream task: train a simple classifier/regressor on extracted features and compare performance vs. raw features.
- Reconstruction error (autoencoders) and checking for overfitting.
Use multiple diagnostics; visual checks + quantitative metrics are persuasive.
5) Combine methods when sensible
Pipelines often mix methods for speed and stability:
- PCA (reduce to, e.g., 50 components) → t‑SNE/UMAP for 2D visualization (reduces noise and runtime).
- Pretrained autoencoder embeddings → clustering or classification.
Explain why you combined them (noise reduction, speed, improved signal-to-noise ratio).
6) Balance performance with interpretability
Interviewers will ask about trade-offs. Example talking points:
- PCA: interpretable loadings vs. limited to linear relationships.
- Autoencoders/Deep embeddings: expressive but less interpretable—use techniques like feature attribution, latent traversal, or sparse/variational autoencoders to improve interpretability.
- NMF/ICA: often more interpretable for parts-based or independent-source problems.
Common interview questions (and brief answers)
- Q: "When would you use PCA vs. t‑SNE?" A: PCA for linear compression and preprocessing; t‑SNE for non‑linear visualization of local neighborhoods.
- Q: "How do you choose the number of PCA components?" A: Use explained variance (e.g., keep components explaining 90–95%), scree plot elbows, or downstream validation.
- Q: "How to validate unsupervised features without labels?" A: Use clustering metrics, reconstruction error, stability under subsampling, or performance on a downstream task with proxy labels.
Practical checklist to mention in interviews
- [ ] Impute missing values and scale appropriately
- [ ] Choose method based on data size, linearity, and interpretability needs
- [ ] Tune critical hyperparameters thoughtfully (and explain why)
- [ ] Validate using visual + quantitative methods
- [ ] Consider combining methods for speed/stability
- [ ] Discuss trade-offs and interpretability strategies
Quick sample answer structure for interviews
- Summarize the problem and data (size, sparsity, labels availability).
- State your chosen method and why (assumptions & trade-offs).
- Explain preprocessing steps and key hyperparameters.
- Describe validation plan and fallback options.
Wrap-up: show you can connect method assumptions to data characteristics, demonstrate hands-on validation, and discuss interpretability — that's what interviewers want to hear.
#MachineLearning #DataScience #MLOps

