
In Traffic Control ML, Your RL Metric Isn’t “Accuracy”—It’s Waiting Time
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
In Traffic Control ML, Your RL Metric Isn’t “Accuracy”—It’s Waiting Time
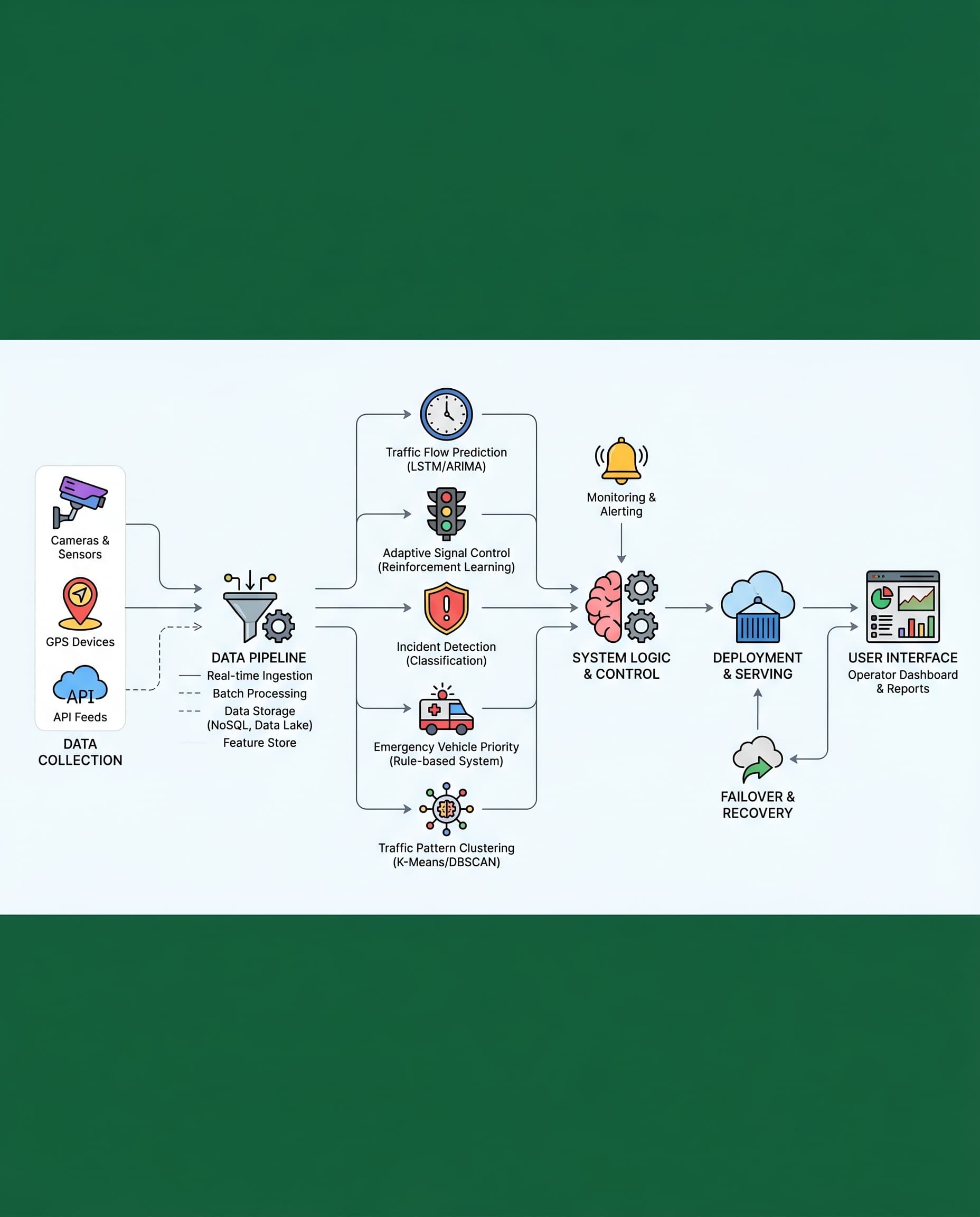
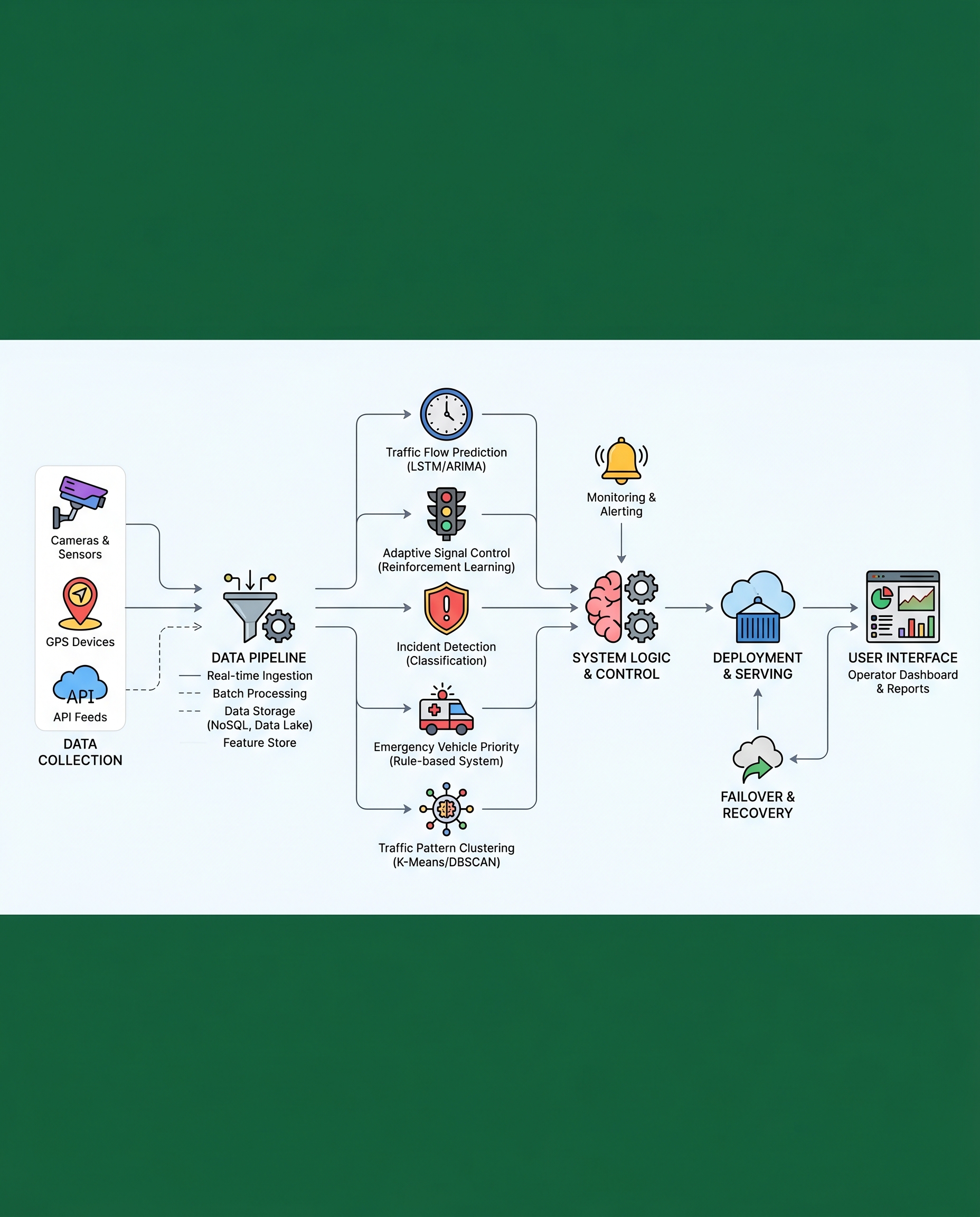
Adaptive traffic signal control is a classic reinforcement learning (RL) use case. But a surprisingly common mistake is to treat it like a classification task and measure performance with accuracy. That’s misleading. In traffic control the objective is to move vehicles through the network efficiently — so evaluate RL policies by how they reduce congestion.
Below is a concise, practical checklist for interviews, experiments and deployments.
Define the objective up front
Be strict about this in interviews and design reviews: your objective is to minimize congestion, not maximize an abstract accuracy score. Operationalize that objective with measurable traffic metrics.
Primary metrics to use
- Average waiting time (per vehicle): the single most informative metric for user-level impact. Measures how long vehicles spend stopped or moving below a speed threshold.
- Queue length (per lane / per approach): indicates how congestion builds and where bottlenecks occur.
- Cumulative reward (episode total): keep as an auxiliary metric to ensure the learned policy is improving according to the reward function you designed.
Why these and not accuracy? Accuracy is meaningful for classification boundaries, not for continuous system performance where the cost of small differences in delay is real and compounding.
Evaluation protocol (recommended)
- Train and test exclusively in a realistic traffic simulator first (SUMO, AIMSUN, CityFlow, etc.). Real roads are unsafe for exploration—you must avoid uncontrolled experiments on live intersections.
- Use representative traffic patterns: peak/off-peak, incident scenarios, and route diversions. Evaluate across distributions, not a single scenario.
- Compare against strong baselines: fixed-time plans, actuated signals, and existing adaptive controllers (e.g., SCOOT, SCATS, MOVA-like controllers).
- Report:
- Mean and variance of average waiting time and queue length
- Cumulative reward per episode (with the exact reward function made explicit)
- Statistical significance (confidence intervals or hypothesis tests) across multiple random seeds and traffic seeds
- Log per-episode and per-step diagnostics so you can diagnose failure modes (e.g., oscillations, instability, starvation of some approaches).
Safety and transition-to-reality
- Use offline evaluation and replay buffers to validate learned behavior on recorded traces before any live test.
- Use safe-exploration or constrained RL approaches during any real-world trials (e.g., bound minimum green times, emergency-vehicle priority, or rule-based overrides).
- Plan a phased rollout: pilot with low-risk intersections, shadow mode comparisons, then limited live A/B tests under supervision.
- Consider sim-to-real transfer techniques (domain randomization, calibration with loop-detector noise, model-based fine-tuning) to reduce the reality gap.
Practical tips for interviews and experiments
- When asked about metrics, always answer: "minimize average waiting time and queue length; use cumulative reward as a sanity check." Explain why classification metrics are irrelevant.
- Be ready to show how you compute each metric from simulator outputs (arrival time, departure time, lane occupancy) and how you aggregate them.
- Emphasize reproducibility: fixed seeds, detailed environment configs, and baseline implementations.
Short checklist for a candidate
- State objective: minimize congestion (explicitly define it).
- Primary evaluation: average waiting time + queue length.
- Auxiliary evaluation: cumulative reward, stability diagnostics.
- Validation: train and test in simulator; use safe and staged real-world validation if you get to deployment.
Conclusion
In adaptive signal control, accuracy is the wrong lens. Optimize for waiting time and queue length, validate in simulators, and use cumulative reward and safety constraints to guide deployment. That framing separates thoughtful RL work from toy experiments.
#MachineLearning #ReinforcementLearning #MLOps

