
Top‑K at Scale: Why Pre‑Aggregation Beats “Compute on Demand” in Interviews

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
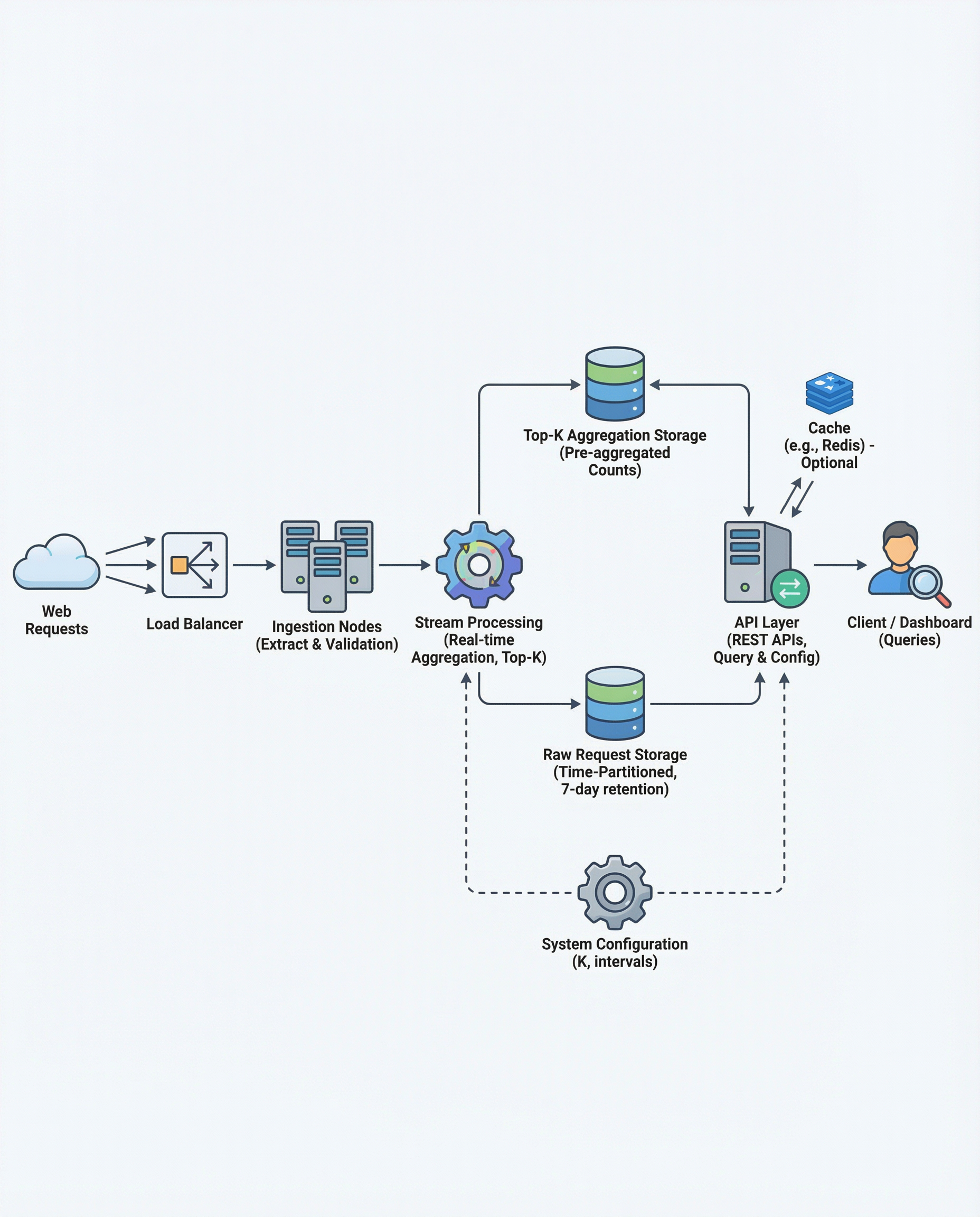
Top‑K at Scale: Why Pre‑Aggregation Beats “Compute on Demand”
When you design a Top‑K system for very high ingestion rates (e.g., 10M events/min), the key interview-worthy insight is simple: don't compute Top‑K at query time. Instead, pre‑aggregate in the stream layer and store compact results keyed by (interval_start, interval_duration). That converts an expensive scan over raw logs into a tiny, constant‑time lookup.
The problem
At 10M events per minute (~167k events/second), a naive "compute on demand" approach that scans raw logs for each query is infeasible:
- Latency: scanning large volumes takes seconds to minutes.
- Cost: repeated scans multiply compute and I/O costs.
- Complexity: queries contend with retention/partitioning and require complex indexes.
Interview tip: quantify the scale and explain why a full scan won't meet latency or cost targets.
The pattern: pre‑aggregate in the stream layer
- Ingest events into a streaming pipeline (Kafka, Kinesis, Pub/Sub).
- In the stream processing layer (Flink, Beam, Spark Streaming, or a stateful stream processor) maintain Top‑K state per key + window.
- Periodically flush the compact Top‑K result into an aggregation store keyed by (interval_start, interval_duration, optional_group_key).
- Keep raw events in a separate cold store (S3/BigQuery/HDFS) for audit and replay.
Result: queries read the precomputed Top‑K for the requested interval — a small lookup instead of a huge scan.
Why store by (interval_start, interval_duration)?
- Deterministic keys: you can look up exactly the precomputed result for a requested interval.
- Small payload: you store only the condensed Top‑K list (and metadata), not all events.
- Efficient retention: partition by time so expiring data is a delete/drop partition operation, not an expensive query.
Storage separation: audit vs fast reads
Interview rule: separate raw storage (for auditing and replay) from the aggregation store (for low-latency reads).
- Raw store: append-only, compressed, long retention (S3, GCS, HDFS).
- Aggregation store: fast read/low latency (Redis, DynamoDB, Cassandra, or a tuned OLTP store). Partition by time for fast pruning.
This separation simplifies compliance and replay while keeping production queries fast and cheap.
Implementation notes & options
- Windowing: choose fixed windows (e.g., per minute, per hour) or hierarchical intervals; store results per-window.
- Algorithms: use exact Top‑K with deterministic state (Space‑Saving) or approximate sketches (Count‑Min + heavy-hitters) for memory savings.
- State backend: RocksDB (embedded in Flink), Redis, or a durable KV like DynamoDB for read-serving.
- Freshness: stream processors can provide near‑real‑time updates; trade off latency vs cost by controlling flush frequency.
- Fallback: for ad‑hoc or long historical ranges, either run a background recompute job from raw logs or combine windowed aggregates.
Example architecture (high level)
- Events -> Kafka
- Stream processor (Flink/Beam) maintains in-memory state or embedded RocksDB state store
- Every interval the processor writes {interval_start, interval_duration, group_id} -> TopK list to DynamoDB/Redis
- Raw events batched to S3 for long‑term storage and replay
- API queries read from the aggregation store; if not available, fall back to precomputed neighboring intervals or asynchronous recompute
Interview talking points (concise)
- Explain the scale and why scanning raw logs fails on latency/cost.
- Propose pre‑aggregation in the streaming layer and storing per time interval.
- Emphasize separation: raw audit store vs aggregated read store.
- Mention partitioning by time for cheap retention (delete/expire, not query).
- Discuss tradeoffs: freshness, storage vs compute, approximate vs exact Top‑K.
When compute‑on‑demand might make sense
- Low ingestion volume (orders of magnitude smaller than 10M/min).
- Very ad‑hoc queries across arbitrary time ranges where precomputation would explode storage.
- Prototyping or one‑off analytics tasks.
Short summary
At high ingestion rates, pre‑aggregate Top‑K in the stream layer, materialize per (interval_start, interval_duration), store results in a fast read store, and keep raw logs separately for audit/replay. Partition by time so retention is just deletion — simple, predictable, and interview‑friendly.
#SystemDesign #DataEngineering #Streaming

