
Stop Using Random Splits: The Time-Based Validation Rule for Recommenders

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Stop Using Random Splits: The Time-Based Validation Rule for Recommenders
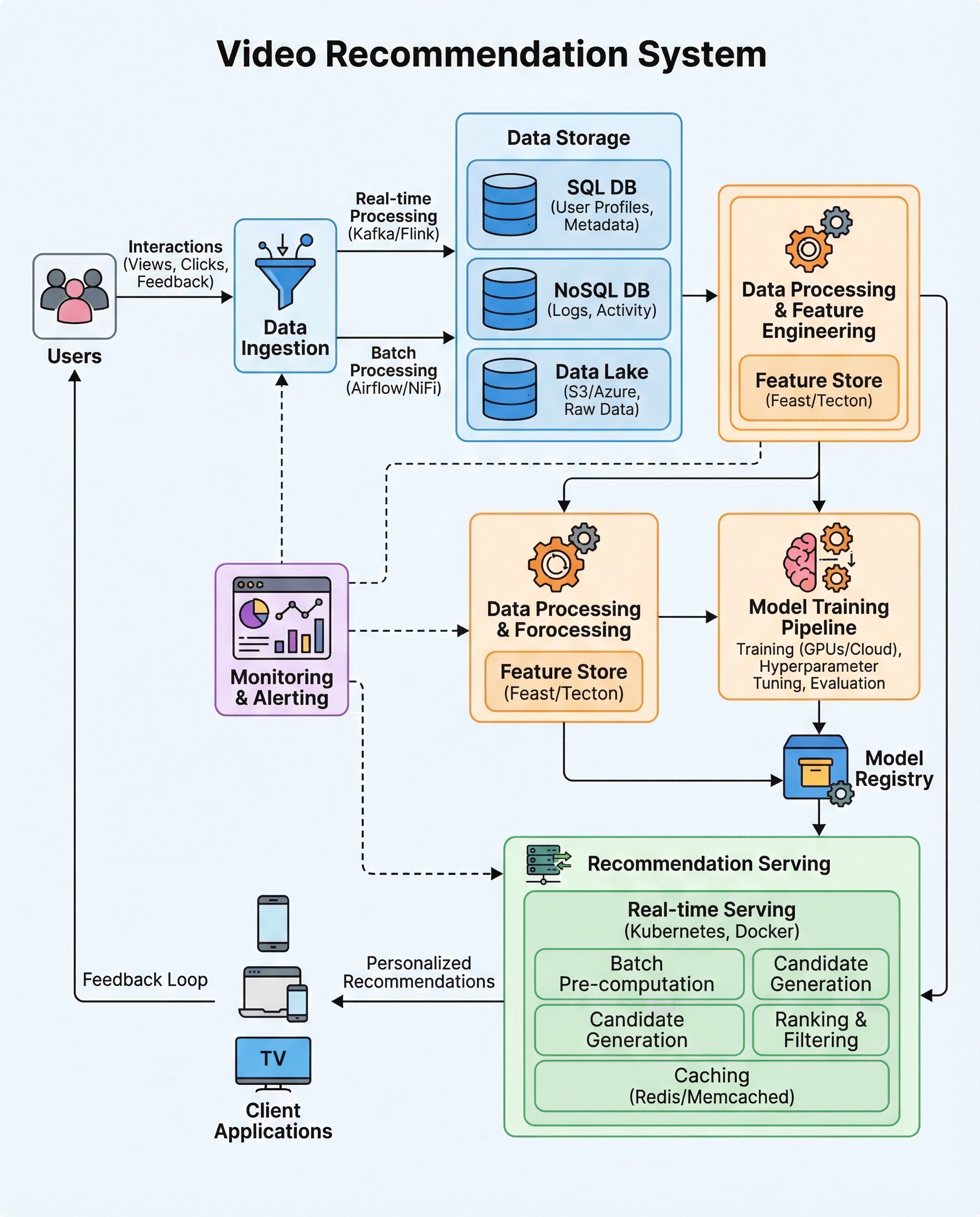
In video-recommendation (and broader recommender-system) interviews, a common evaluation mistake shows up again and again: randomly splitting interaction data into train/validation/test. That approach leaks future information into your training set and gives you inflated Precision@K / NDCG numbers that won't transfer to production.
Do it correctly: split interactions by time per user — train on each user's past interactions and validate/test on their later interactions. This mirrors the real production task (predict the next watch), surfaces temporal drift, and makes your offline metrics meaningful.
Why random splits fail
- Temporal leakage: Random sampling can place later interactions into training and earlier ones into testing for the same user, which lets models learn from the future.
- Over-optimistic metrics: Precision@K and NDCG computed on random splits tend to be unrealistically high, misleading model selection.
- Missing drift: Random splits hide changes in user behavior, item catalog, and popularity over time.
- Misaligned with production: In production you predict future events from historical data — your offline evaluation should match that.
The rule (simple and powerful)
For each user, split their interaction history by time:
- Train = that user's earlier events
- Validation/Test = that user's later events
This per-user, time-based split ensures the model is always evaluated on truly future behavior for each user.
Practical approaches
- Fixed-ratio per user: sort interactions by timestamp and take e.g. first 80% as train, last 20% as test.
- Time cutoff: choose a global cutoff timestamp (or sliding windows) and use events before as train and events after as test.
- Temporal cross-validation / backtesting: evaluate multiple train→test time windows to measure stability and drift.
Example (pseudocode using pandas)
# df columns: user_id, item_id, timestamp
df = df.sort_values(['user_id', 'timestamp'])
def split_user(g, train_frac=0.8):
n = len(g)
if n < 2:
g['set'] = 'train' # or drop users with too few events
return g
cutoff = int(n * train_frac)
g.loc[g.index[:cutoff], 'set'] = 'train'
g.loc[g.index[cutoff:], 'set'] = 'test'
return g
df = df.groupby('user_id', group_keys=False).apply(split_user)
Tips and caveats
- Minimum events per user: decide how to handle users with very few interactions (drop, keep all in train, or use special handling).
- Cold-start users: time-based splits reveal cold-start problems. Use them to evaluate hybrid or cold-start strategies.
- Evaluation window size: choose windows that reflect how often you'll refresh models in production.
- Metrics: keep using Precision@K, NDCG, recall, etc., but compute them in the time-split setting so they reflect future-prediction performance.
- Monitor drift: run time-sliced evaluations regularly to detect degrading performance due to content or user-behavior changes.
Conclusion
If you can't explain why a time-based, per-user split is necessary for recommender evaluation, you don't really understand recommender evaluation. Stop using random splits — split by time per user, align your offline tests with the production task, and trust your metrics.
#MachineLearning #RecommenderSystems #DataScience

