
System Design Interviews: If You Ignore These 3, You Fail

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
System Design Interviews: If You Ignore These 3, You Fail
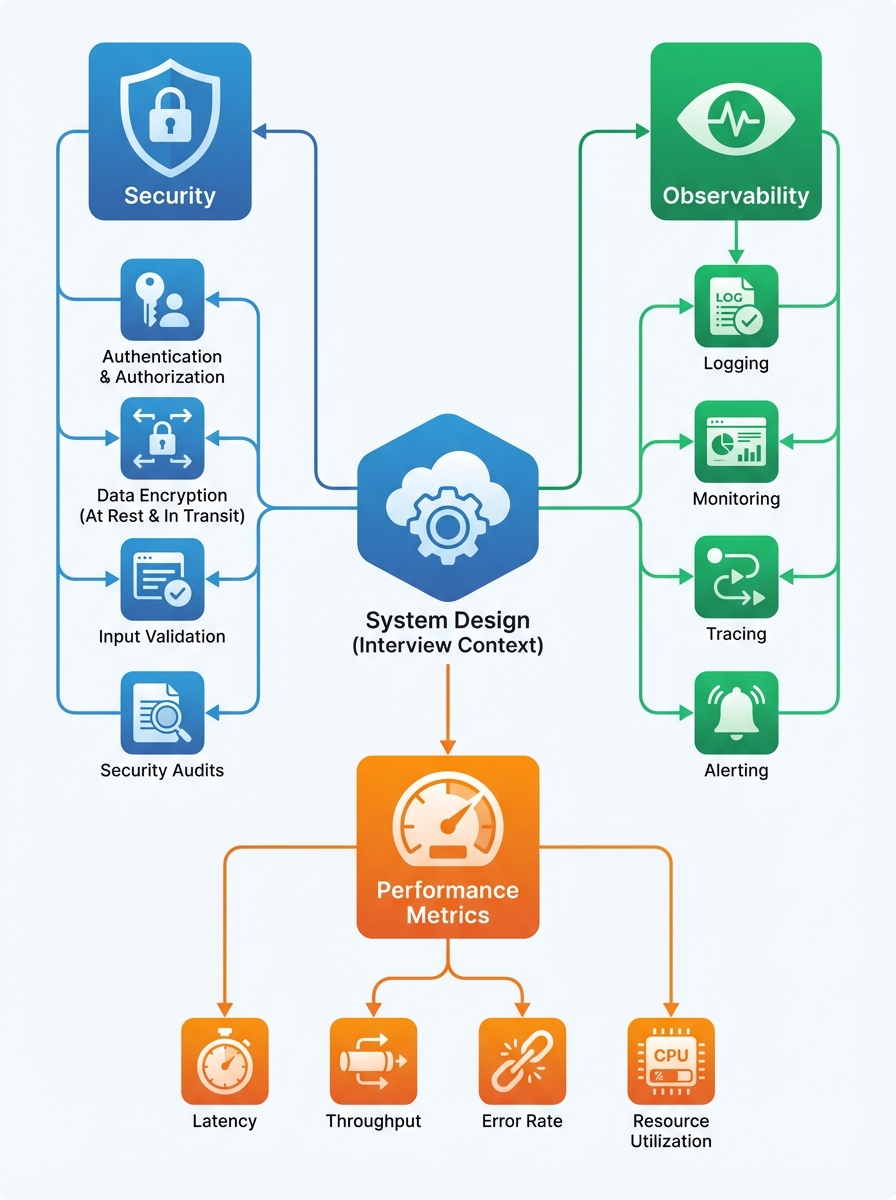
In system design interviews you’re not just sketching boxes and arrows—you’re showing you can operate a real system. Interviewers want to know you can build something that is secure, observable, and performs under load. If you treat these as "later" or "implementation details," you risk failing the interview.
Below are the three non-negotiable pillars to address early in any design discussion, what interviewers expect you to say, and concise examples you can use in real interviews.
1) Security
Why it matters
Security is fundamental: a functional system that leaks data or lets attackers impersonate users is broken. Interviewers expect you to identify the biggest attack surface and propose practical mitigations.
What to call out
- Authentication & Authorization: Who can access what? Name an auth scheme (e.g., OAuth2 for third-party access, JWTs for stateless sessions) and where it is enforced (API gateway, service layer).
- Encryption: Data in transit (TLS) and at rest (disk encryption, database-level encryption). Mention key management (KMS) briefly.
- Input validation & sanitization: Prevent injection, malformed requests, and supply-chain issues.
- Least privilege & segmentation: Limit blast radius via roles, microservice boundaries, and network policies.
- Auditing & logging: What events you log, retention policies, and compliance considerations.
Concrete interview phrases
- "We'll use TLS for all client-server traffic and a KMS for key rotation."
- "AuthN at the gateway, authZ enforced per-service; keep tokens short-lived and rotate refresh tokens."
- "Log security events to a write-once audit store for compliance."
Common mistakes
- Skipping auth entirely or leaving authorization vague.
- Saying "we'll add encryption later" without explaining where/why.
2) Observability
Why it matters
When things fail, you must be able to detect, diagnose, and resolve issues quickly. Observability proves you can operate the system—not just design it.
What to call out
- Structured logs: Include request IDs, user IDs, timestamps, and component context.
- Metrics: Track SLO-related metrics (latency P95/P99, throughput, error rate) and resource metrics (CPU, memory).
- Tracing: Distributed tracing to follow a request end-to-end across services.
- Alerts & On-call: Define alert thresholds, escalation policies, and runbook examples.
- Retention & sampling: Log/trace retention, and sampling strategy for traces to control cost.
Concrete interview phrases
- "We’ll emit structured logs with a correlation ID and use a tracing system (e.g., OpenTelemetry) for P95/P99 latency investigations."
- "Alerts: page when error rate > 2% for 5 minutes; otherwise notify the team channel."
Common mistakes
- Omitting how you’ll correlate logs and traces across services.
- Not proposing concrete SLOs/alerts—saying "we'll monitor" is weak.
3) Performance
Why it matters
Performance determines user experience and cost. Interviewers want to see that you can quantify load, identify bottlenecks, and propose improvements.
What to call out
- Key metrics: latency (P50/P95/P99), throughput (requests/sec), error rate, and resource utilization.
- Capacity planning: Expected QPS, data growth, and scaling strategy (horizontal vs vertical).
- Caching & rate limiting: Where you cache (edge, CDN, in-memory), cache invalidation strategy, and client-side vs server-side caching.
- Backpressure & graceful degradation: How the system behaves under overload (queueing, shedding, reduced features).
- Optimization levers: Indexing for DBs, async processing, batching, and CDN for static assets.
Concrete interview phrases
- "Assume 5k RPS with 99th percentile latency target of 200ms. We'll horizontally scale stateless services behind a load balancer and use a write-through cache for hot reads."
- "If latency spikes, we'll shed noncritical traffic and route to degraded mode while we auto-scale."
Common mistakes
- Failing to quantify expected load or targets.
- Proposing caching without discussing invalidation or consistency trade-offs.
How to integrate these in an interview flow
- After clarifying requirements, state constraints and high-level goals: latency SLO, availability target, and any security/compliance constraints.
- Sketch the core components quickly; then iterate and call out security, observability, and performance for each component.
- For each trade-off you propose, mention how you’ll monitor and measure its impact.
Quick checklist to keep in your pocket
- Security: Who can access what? Where is auth enforced? How is data encrypted?
- Observability: Correlation IDs, key metrics (latency/error), tracing, alerting thresholds.
- Performance: Expected load, SLOs, caching strategy, and backpressure plan.
Addressing these three topics early converts a box-and-arrow diagram into a credible, operable system design. Make them explicit—don’t leave them as "implementation details."

