
System Design Interviews: The Scalability + Reliability Checklist You Must Recite

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
System Design Interviews: The Scalability + Reliability Checklist You Must Recite
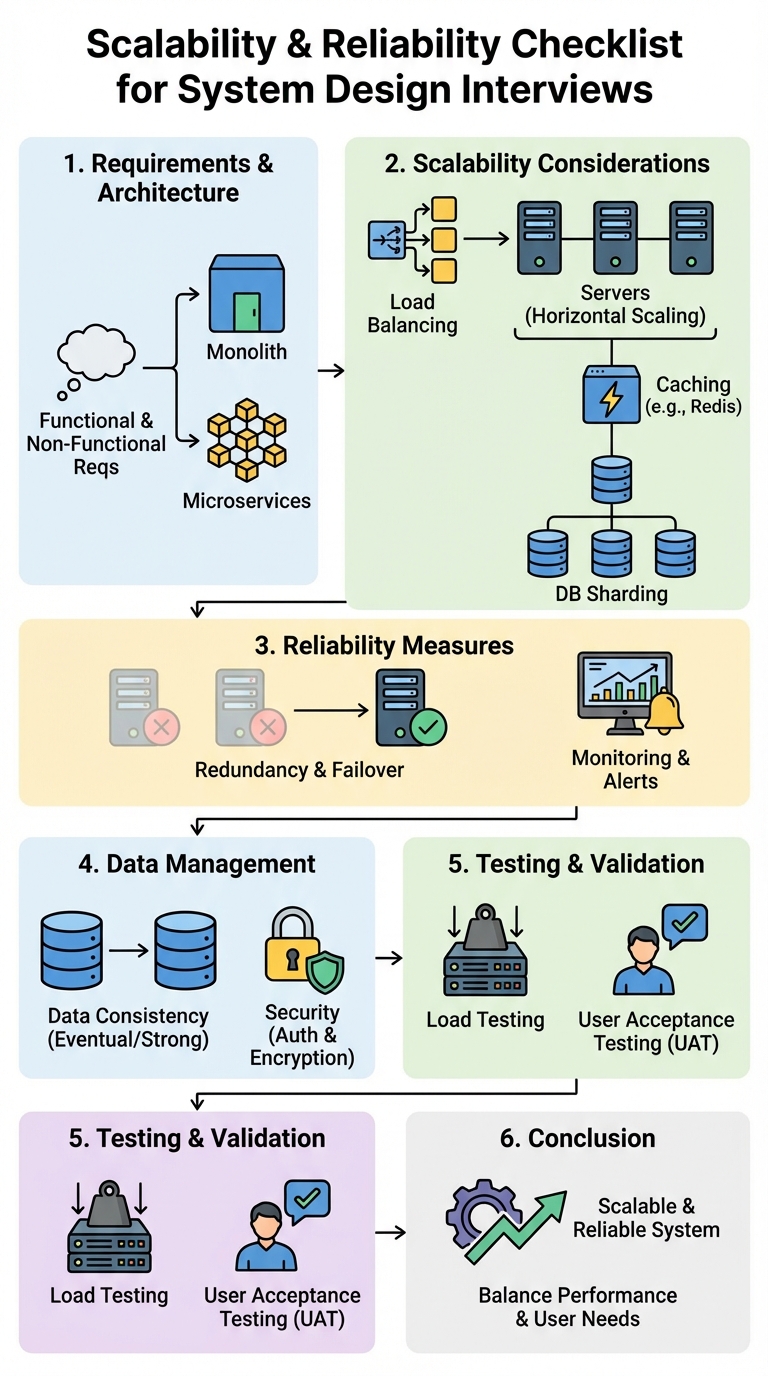
In system design interviews you don't win by drawing boxes — you win by showing you can make, justify, and trade off practical decisions. Below is a compact, interview-ready checklist that helps you present a complete, balanced design focused on scalability and reliability.
Use this as a script: state assumptions, call out tradeoffs, and support choices with numbers where possible.
1) Requirements — lock them down first
- Clarify functional requirements (features, request patterns, critical flows).
- Quantify non-functional requirements: latency SLOs (e.g., p95 < 100ms), throughput (RPS), availability target (e.g., 99.95%), and growth projections (user growth, transaction growth per month/year).
- Ask about constraints: budget, regulatory, data residency, client SDKs, device types.
- Outcome: write a 1–2 line requirements statement and target numbers.
2) Architecture — high-level choices and data flow
- Choose a deployment model: monolith vs microservices. State pros/cons (speed of iteration vs team independence and operational overhead).
- Show a clear data flow: clients → API gateway/load balancer → services → data stores/queues → caches.
- Define communication patterns: synchronous (REST/gRPC) vs asynchronous (message queues, pub/sub). Explain why.
- Draw one clear path for the critical request and annotate failure modes and latency.
3) Scale — horizontal first, then optimizations
- Prefer horizontal scaling: stateless service instances behind a load balancer.
- Add caching (e.g., Redis) for hot reads; explain TTL and cache invalidation strategy.
- Use CDNs for static content and edge caching.
- When a single data partition is the bottleneck, shard/partition the dataset: pick shard key and explain tradeoffs (hot keys, rebalancing complexity).
- Use read replicas for read-heavy workloads; consider write scalability (leader/follower, multi-leader tradeoffs).
4) Reliability — eliminate single points of failure
- Remove SPOFs: multiple instances, multi-AZ or multi-region deployments for critical services.
- Replication and redundancy: DB replication factor, cross-region replication for DR.
- Automated failover and leader election (e.g., Raft, ZooKeeper, managed DB failover).
- Graceful degradation: prioritized functionality when degraded (serve cached responses, limit feature set).
- Resilience patterns: circuit breakers, retries with exponential backoff, bulkheads.
5) Observability — detect and respond quickly
- Instrument metrics: latency (p50/p95/p99), error rates, throughput, saturation (CPU/memory), queue lengths.
- Distributed tracing for request flow and root-cause analysis.
- Structured logs and correlation IDs.
- Alerts: define thresholds and pages (avoid noisy alerts). Use escalation policies and runbooks.
6) Data — consistency, durability, and lifecycle
- Choose a consistency model: strong vs eventual. Explain impact on user experience and latency.
- Data model and storage choices: relational vs NoSQL vs object store — justify by access patterns.
- Backups and recovery: RPO (how much data you can lose) and RTO (how quickly you must recover).
- Retention and GDPR/CCPA considerations: archival, deletion, and legal hold.
7) Security and compliance
- Authentication (AuthN) and authorization (AuthZ): tokens, OAuth2/OpenID Connect, RBAC or ABAC.
- Encrypt in transit (TLS) and at rest (KMS-managed keys).
- Secrets management, key rotation, and least privilege for services.
- Audit logs, breach detection, rate limiting, and input validation.
8) Validation — prove it works at scale and under failure
- Load testing tools: k6, JMeter, Locust; test target RPS and bottlenecks.
- Chaos and failover tests: simulate AZ/region outages, instance termination, network partitioning.
- Canary releases and progressive rollouts to catch regressions early.
- Measure and tune: profiling, database slow query analysis, and cache hit ratios.
Quick interview script (recite this)
- Clear requirements with numbers (latency, throughput, availability).
- High-level architecture and data flow diagram.
- Scaling plan: stateless services, caching, sharding when needed.
- Reliability: redundancy, failover, graceful degradation.
- Observability: metrics, tracing, alerts and runbooks.
- Data decisions: consistency, backups, retention.
- Security: authN/authZ, encryption, auditing.
- Validation: load tests, chaos/failover tests.
Tips for delivery:
- Always state assumptions and tradeoffs explicitly.
- Use concrete numbers; if unknown, propose realistic targets and explain why.
- If asked for alternatives, show one or two options and the triggers for choosing them.
Memorize this checklist and use it to structure answers that are both practical and defensible.

