
Stop Using Accuracy on Imbalanced Data (Interview-Proof Evaluation Checklist)

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Stop Using Accuracy on Imbalanced Data
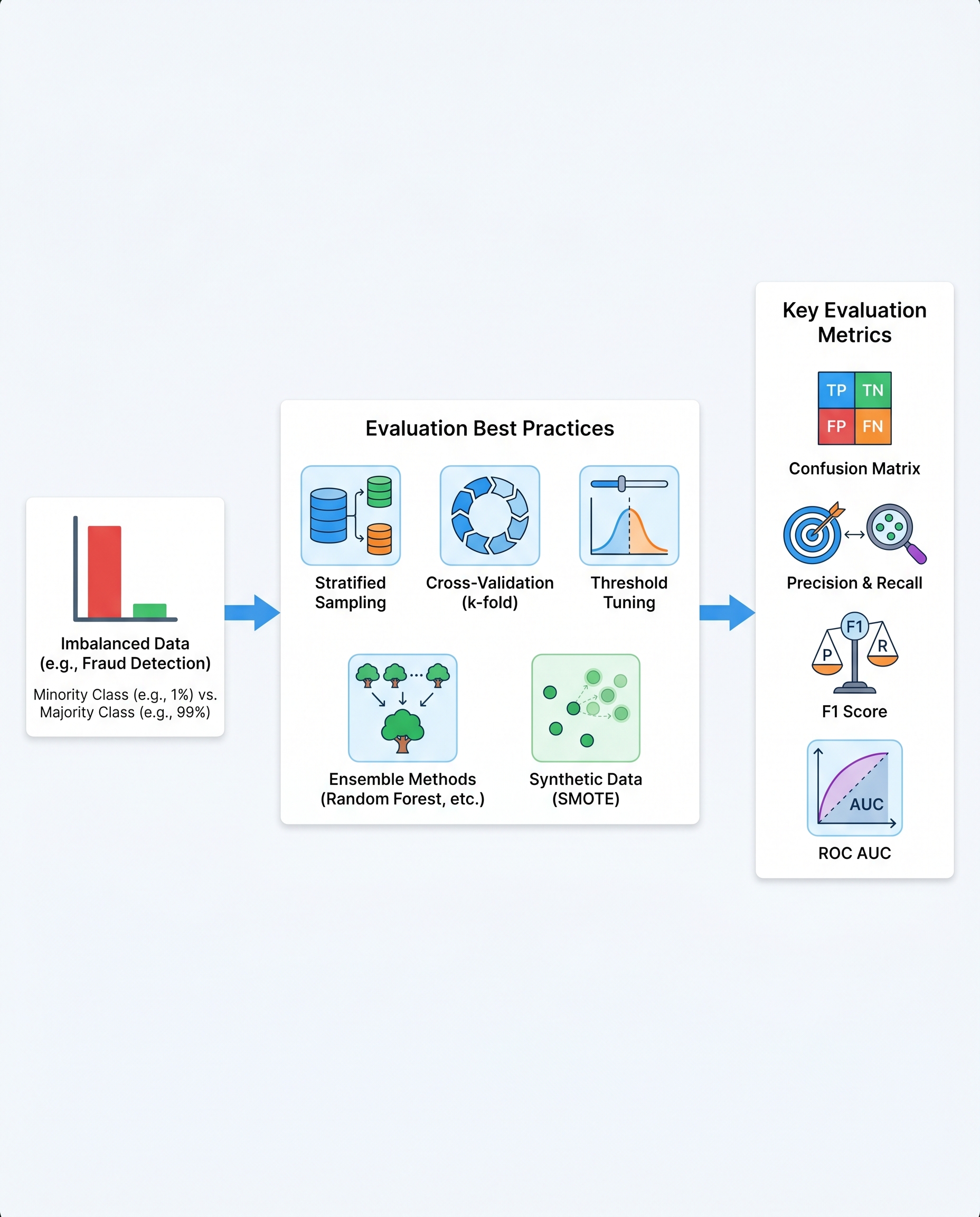
Accuracy is misleading when classes are imbalanced. If fraud is 1% of transactions, a model that always predicts "no fraud" is 99% accurate but utterly useless. In interviews (and reports), lead with the confusion matrix and choose metrics that reflect business risk.
Quick refresher: confusion matrix
| Actual \ Predicted | Positive | Negative |
| Positive | True Positive (TP) | False Negative (FN) |
| Negative | False Positive (FP) | True Negative (TN) |
Report these four numbers first — they make every subsequent metric meaningful.
Core metrics and when to use them
- Precision = TP / (TP + FP)
- Use when false alarms are costly (e.g., manual review workload).
- Recall (a.k.a. Sensitivity) = TP / (TP + FN)
- Use when missing positives is costly (e.g., undetected fraud or disease).
- F1 = 2 (Precision Recall) / (Precision + Recall)
- Harmonic mean of precision and recall; balances both.
- F-beta
- Use when you want to weight recall (beta>1) or precision (beta<1) more heavily.
- Specificity = TN / (TN + FP)
- When true negatives matter.
- Balanced Accuracy = (Sensitivity + Specificity) / 2
- Corrects plain accuracy for imbalanced classes.
- Matthews Correlation Coefficient (MCC)
- A single-number summary that handles imbalance well.
- ROC-AUC
- Good for threshold-independent ranking performance, but can be optimistic on very imbalanced data.
- Precision-Recall AUC (PR-AUC)
- Often more informative than ROC-AUC for highly imbalanced problems because it focuses on the positive class.
Evaluation and model-selection best practices (interview checklist)
- Lead with the confusion matrix and class prevalence. Always show TP/TN/FP/FN and the base rate.
- Show a naive baseline (e.g., predict majority class) so your model’s lift is clear.
- Pick metrics that map to business cost: precision, recall, F-beta, PR-AUC, or cost-weighted expected value.
- Use PR-AUC alongside ROC-AUC for imbalanced tasks — PR-AUC highlights performance on the rare class.
- Use stratified train/validation/test splits and/or stratified k-fold CV to preserve class ratios.
- Calibrate probabilities (Platt scaling, isotonic) if you’ll threshold on probability or combine models.
- Tune the decision threshold to optimize business metrics (cost matrix, expected utility), not just a symmetric threshold.
- Consider ensembles (stacking, bagging) to stabilize predictions on rare classes.
- Use resampling (SMOTE, ADASYN) carefully — validate that synthetic examples improve real-world performance and avoid leakage.
- Report uncertainty: confidence intervals, bootstrapped metrics, or CV variability.
- Visualize: confusion matrix heatmap, Precision-Recall curve, ROC curve, and calibration plot.
- Test on a realistic holdout (temporal split if data is time-dependent) and monitor post-deployment for drift.
Practical tips
- Always state class prevalence up front — a 0.1% positive rate changes interpretation.
- If business costs are known, convert FP/FN into dollars and optimize expected value directly.
- When precision matters, show how many false positives per 1,000 alerts your system will generate.
- When recall matters, report how many positives you’ll miss at your chosen operating point.
One-sentence takeaway
Don't report accuracy alone on imbalanced datasets. Start with the confusion matrix, choose metrics tied to business consequences (precision/recall/F-beta/PR-AUC), and tune thresholds and validation strategies accordingly.
#MachineLearning #DataScience #MLOps

