
Stop Using Accuracy on Imbalanced Data (Interview-Proof Evaluation Checklist)

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
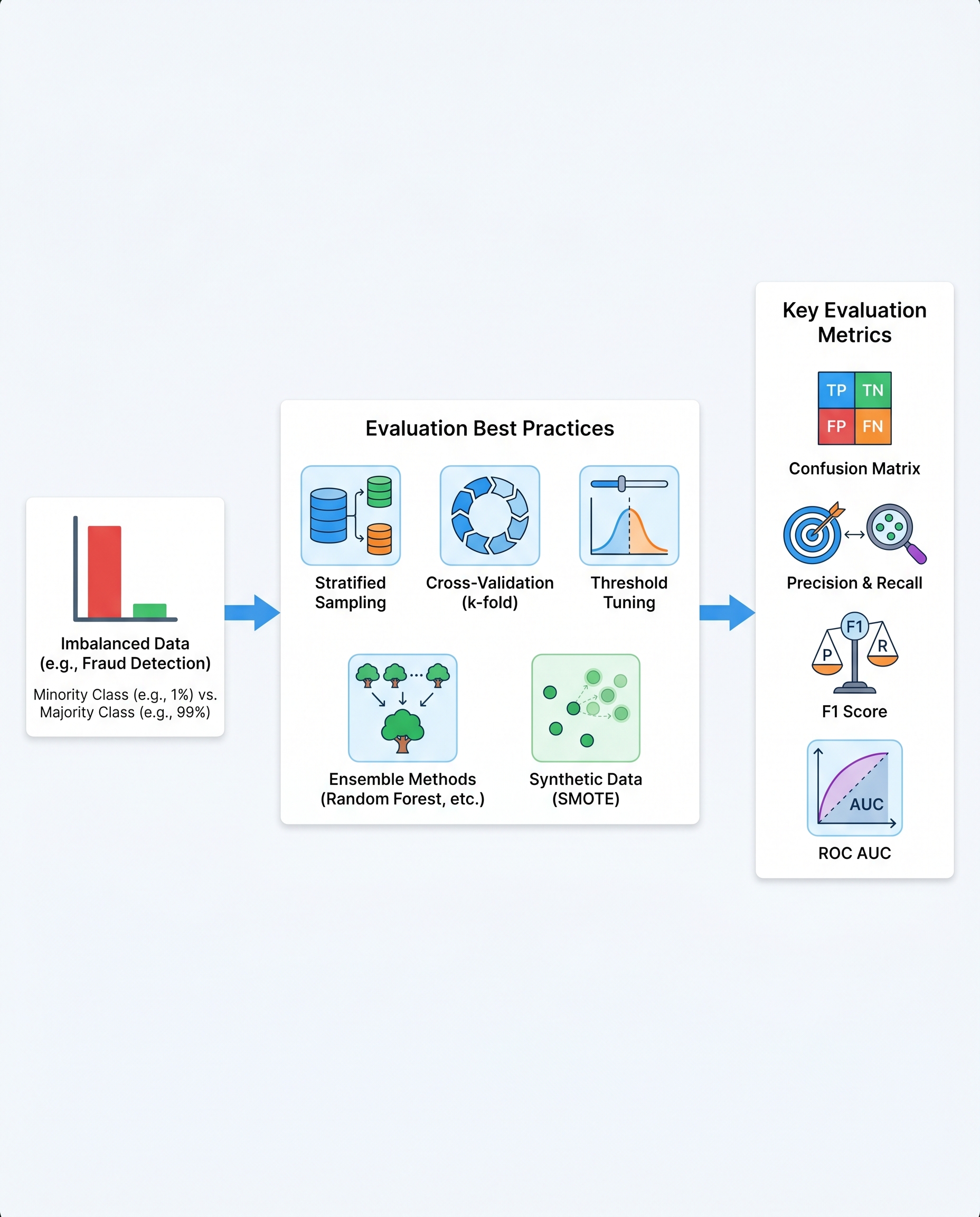
Stop Using Accuracy on Imbalanced Data (Interview-Proof Evaluation Checklist)
Accuracy is seductive but dangerous on imbalanced datasets. When positives are rare (e.g., 1% fraud), a model that predicts "negative" for everything gets 99% accuracy — and is worthless. In interviews and production reviews, lead with the confusion matrix and justify the metrics you choose.
Key concepts (start here in an interview)
- Confusion matrix: report TP, TN, FP, FN — these are the building blocks for every metric.
- Precision (positive predictive value): Precision = TP / (TP + FP). Use when false alarms are costly.
- Recall (sensitivity, true positive rate): Recall = TP / (TP + FN). Use when missing positives is costly.
- F1 score: harmonic mean of Precision and Recall — useful when you want a balance.
- ROC-AUC: threshold-independent measure comparing TPR vs FPR across thresholds.
- PR-AUC: for extreme class imbalance, Precision-Recall AUC often reflects performance on the rare class better than ROC-AUC.
Example: 10,000 examples, 1% positive (100 positives). A model that predicts all negatives: Accuracy = 99% but Recall = 0% and Precision = undefined. This is why accuracy alone lies.
When to pick which metric
- Business cares about false alarms (e.g., support cost): prioritize Precision.
- Business cares about catching every positive (e.g., medical screening): prioritize Recall (sensitivity).
- You need a single scalar for model selection but both errors matter: use F1 or a weighted F-score tuned to business harm.
- Comparing models regardless of threshold: use ROC-AUC, but prefer PR-AUC when positives are rare.
Interview-proof evaluation checklist
- Show the confusion matrix (TP / TN / FP / FN) for at least one realistic threshold.
- Report Precision, Recall, and F1 — explain which one maps to business cost.
- Report threshold-independent metrics (ROC-AUC and PR-AUC) for model comparison.
- Use stratified train/validation/test splits to preserve class ratios.
- Use k-fold cross-validation (stratified) to reduce variance in estimates.
- Tune the decision threshold based on business cost (cost matrix or expected value), not just default 0.5.
- Consider model calibration (Platt scaling, isotonic) if you use probabilities in downstream decisions.
- Try ensembles (stacking, bagging) — they often improve rare-class detection.
- If you resample (SMOTE, oversampling), do it only inside cross-validation folds to avoid leakage.
- Check for label quality: rare events often have noisier labels — audit a sample.
Practical tips and pitfalls
- Threshold tuning: convert model scores to business outcomes. Example: if catching a fraud saves $500 and investigating a false alarm costs $20, choose the threshold that maximizes expected profit.
- PR-AUC vs ROC-AUC: ROC can be overly optimistic when negatives dominate. Use PR curves to see precision-recall trade-offs at low recall levels.
- SMOTE and synthetic oversampling: useful but can cause overfitting if synthetic samples leak information or if minority subgroups are heterogeneous. Prefer careful feature engineering and ensemble methods first.
- Calibration: a well-calibrated probability lets you compute expected costs directly and set thresholds sensibly.
Short summary (what to say in an interview)
"I never report accuracy on imbalanced data. I start with a confusion matrix, report Precision/Recall/F1 and PR-AUC/ROC-AUC, and tune the decision threshold to business costs. I use stratified CV, guard against leakage with resampling, and validate model calibration before deployment."
Quick checklist you can memorize
- Confusion matrix ✓
- Precision / Recall / F1 ✓
- PR-AUC / ROC-AUC ✓
- Stratified splits & k-fold CV ✓
- Threshold tuned to cost ✓
- Calibration & leakage checks ✓
- SMOTE only inside folds ✓
#MachineLearning #DataScience #MLOps

