
Stop Treating GPS Updates Like Relational Data: The Interview Trade-off That Wins

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Stop Treating GPS Updates Like Relational Data: The Interview Trade-off That Wins
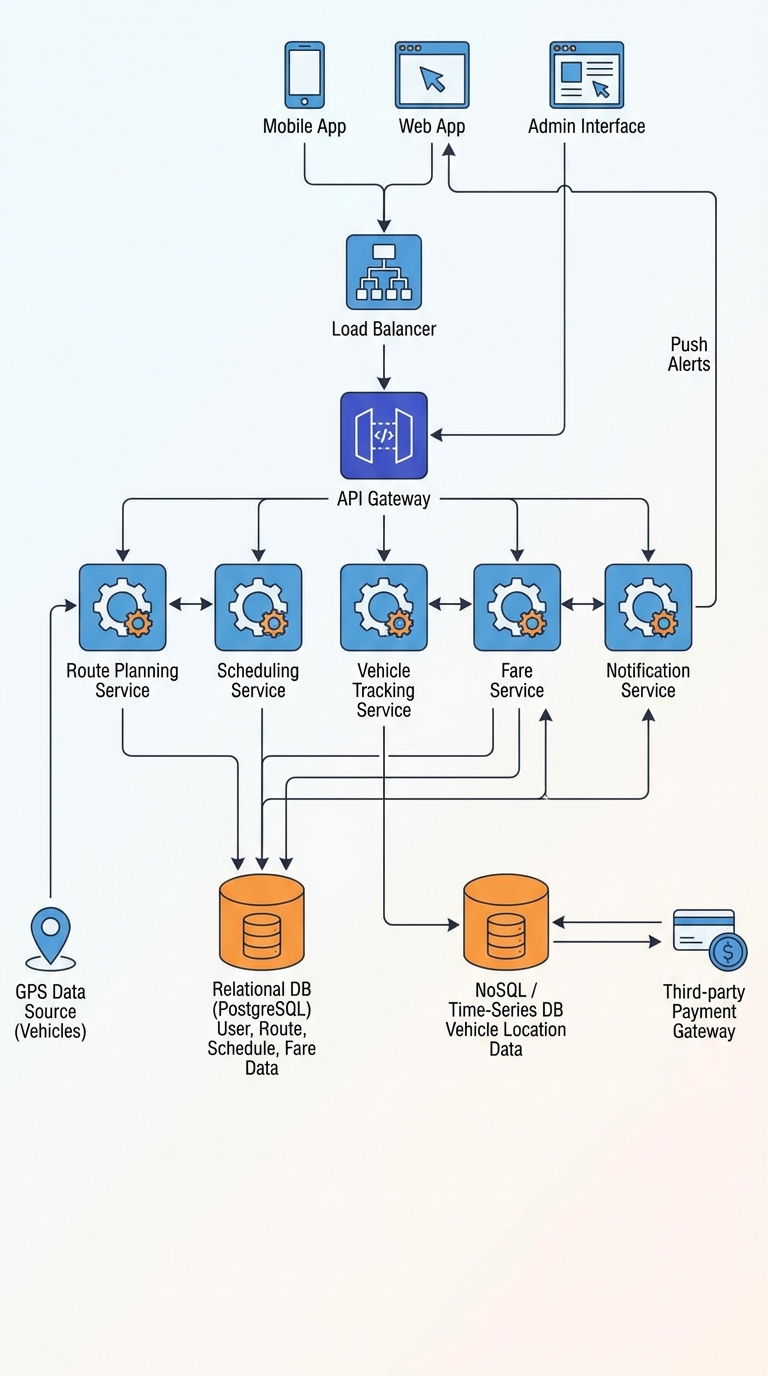
High-frequency GPS pings and core relational data are different workloads and deserve different storage approaches. Users, Routes, Schedules, and Fares belong in PostgreSQL — they need integrity, joins, and transactional correctness. Vehicle GPS pings (every ~15s for ~400 vehicles — ~27 writes/sec) are a write-heavy, append-only time series that will choke OLTP tables: index pressure, WAL growth, vacuum churn, locking, and storage bloat.
The problem, in numbers
- 400 vehicles × one ping every 15 seconds = 400 × 4 = 1,600 pings/minute ≈ 26.7 writes/sec.
- If you insert every ping into the same relational table with indexes and foreign keys, you'll pay in:
- index maintenance and bloat
- increased WAL and replication overhead
- more frequent vacuum and lock contention
- larger backups and slower queries for unrelated transactional workloads
Treating GPS updates like relational, transactional row-centric data is an architectural mismatch.
The interview move (concise answer)
Propose: push Vehicle_Location into a time-series/NoSQL store, keep only the latest location in a fast cache for real-time reads, and persist the full stream asynchronously for analytics and history.
This demonstrates system thinking: you separate concerns (OLTP for relational integrity vs scalable append-only storage for telemetry), minimize contention, and design for the right SLAs.
Recommended architecture (high level)
- PostgreSQL (or similar) — store core relational models: Users, Routes, Schedules, Fares, and other business-critical entities.
- Event bus (Kafka / Kinesis / Pub/Sub) — ingest GPS pings reliably and decouple producers from consumers.
- Time-series / NoSQL store for raw stream — append-only storage optimized for writes and time-based queries (TimescaleDB, InfluxDB, ClickHouse, Cassandra, DynamoDB).
- Cache for latest position — Redis or a small materialized view updated from the stream for ultra-low-latency reads.
- Long-term cold storage — S3 or object store for raw telemetry snapshots, parquet/ORC for analytics.
- Analytics engine — ClickHouse, BigQuery, or similar for aggregation and historical queries.
Flow: device -> ingestion -> event bus -> (1) cache update for latest location (sync/near-sync) (2) append to time-series store and object storage asynchronously -> analytics / history queries.
Why this trade-off wins
- Write scalability: time-series/NoSQL stores are optimized for high write throughput and sequential writes.
- Minimal OLTP impact: relational tables avoid constant churn, keeping transaction latency low.
- Storage & retention control: TTLs, rollups, and downsampling reduce long-term storage costs.
- Separation of concerns: transactional correctness remains in Postgres; telemetry concerns are handled by systems built for that purpose.
- Practical: most use cases tolerate eventual consistency for location updates; you only need the latest location to be near-real-time.
Practical choices and patterns
- Time-series DB: TimescaleDB (if you want Postgres compat), InfluxDB, or ClickHouse (for analytics).
- Wide-column / NoSQL: Cassandra or DynamoDB for massive scale / multi-region.
- Event streaming: Kafka (strong durability + ecosystem), Kinesis, or Pub/Sub.
- Cache: Redis (hash per vehicle with TTL) or a bounded in-memory store for latest location.
- Cold storage + analytics: S3 → Parquet → ClickHouse / BigQuery for cost-effective historical analysis.
Schema suggestions:
- Keep a single
latest_vehicle_locationcache entry per vehicle (vehicle_id → {lat, lon, timestamp, heading}). - Persist raw pings as append-only records partitioned by date and vehicle_id (for efficient range scans).
- Use TTLs and downsampling: keep high-resolution data for recent window (days/weeks), aggregate older data (hourly/daily) for long-term retention.
Interview talking points
- Mention metrics: expected writes/sec, retention window, query patterns (latest vs historical), SLO for read latency.
- Explain consistency model: eventual consistency for latest location is acceptable in most cases; if strict consistency is required, discuss trade-offs and write path changes.
- Partitioning key: use vehicle_id + time to avoid hot partitions; consider producer-side batching.
- Idempotency: include message IDs or monotonic timestamps so consumers can dedupe.
- Cost & ops: compressed, append-only stores + TTLs reduce storage; streaming decouples spikes and simplifies scaling.
One-liner to use in interviews
"Keep relational data in Postgres, treat GPS pings as a time-series stream: cache the latest location, write the full stream into a time-series/NoSQL store asynchronously — it minimizes OLTP contention and scales reliably."
This approach shows you can recognize workload patterns, pick the right tools, and articulate trade-offs rather than defaulting to a single datastore for everything.

