
Stop Measuring Code Gen with BLEU: Interviewers Want This Instead

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Stop Measuring Code Gen with BLEU: Interviewers Want This Instead
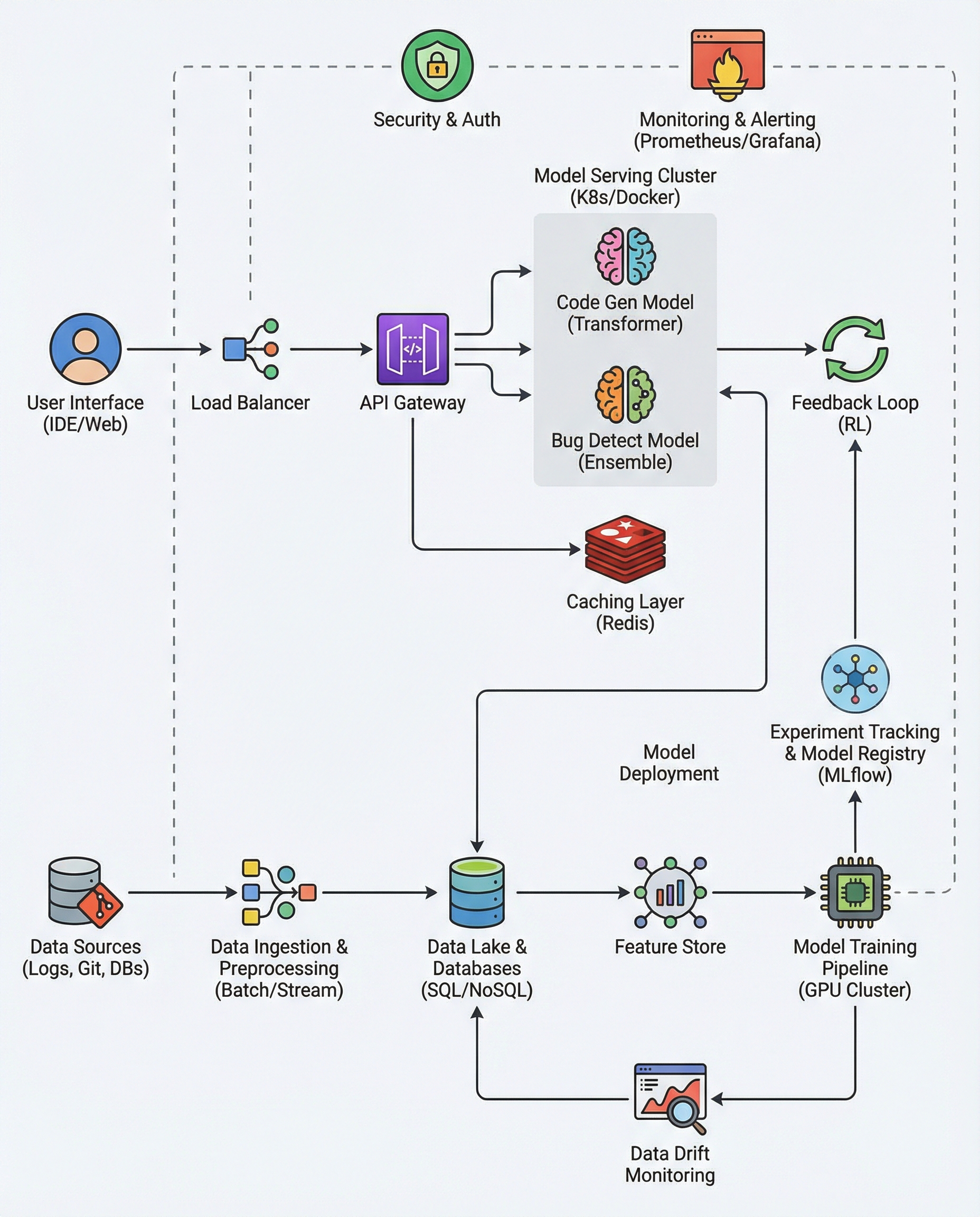
Automated code generation is getting better — but our evaluation methods haven't always kept up. BLEU (and similar surface-similarity metrics) reward output that looks like reference code, not code that actually works. That makes BLEU a weak, often misleading metric for interview or production evaluations.
If you're interviewing candidates or validating code-generation systems, insist on evaluation tied to execution and specifications. Here’s a practical, interviewer-focused guide to doing that.
Why BLEU fails for code
- BLEU measures token/phrase overlap, not functional behavior. Two implementations with zero token overlap can both be correct (or both be wrong).
- It encourages style matching over correctness. Generated code that “looks right” can still fail tests, violate constraints, or be insecure.
- Small syntactic differences (naming, ordering) hurt BLEU but often don't matter for correctness — so BLEU can undercount good solutions.
Bottom line: BLEU is useful for surface similarity research, not for judging whether code meets requirements.
Define “correct” concretely
For interviews and automated evaluation, define correctness as a combination of:
- Passing a suite of unit and integration tests. Functional tests are the primary signal.
- Meeting explicit constraints: API signatures, input/output formats, performance/complexity targets, memory limits.
- Security requirements: absence of obvious vulnerabilities (e.g., injection, unsafe eval, unsanitized input), and passing static-analysis or lint/security checks.
- Adherence to non-functional specs where applicable (e.g., idempotency, concurrency behavior).
Make these checks part of an automated harness so evaluation is objective and reproducible.
Practical evaluation pipeline (recommended for interviews)
- Test-first or provided-tests approach
- Give candidates (or the model) a test suite and require code to pass it. This focuses the assessment on behavior.
- Automated execution harness
- Run unit and integration tests in isolated sandboxes. Capture pass/fail, error traces, and runtime metrics.
- Constraint checks
- Validate API shapes, complexity bounds (big-O or practical perf tests), and resource usage.
- Static analysis
- Run linters and security scanners. Flag unsafe patterns and critical violations.
- Post-correctness evaluation
- Only after tests pass, measure readability, maintainability, and user satisfaction. This prevents optimizing for “nice-looking wrong code.”
- Human review for edge cases
- Use targeted human review for ambiguous failures, security concerns, or design decisions that tests don’t cover.
Hold-out sets: avoid overfitting to a single style
- Build your evaluation set from multiple projects, domains, and languages. Don’t let a model overfit to a single repo or coding style.
- Include both small algorithmic tasks and realistic integration scenarios.
- Keep a strict hold-out set (never used during development or model fine-tuning) to get an honest estimate of generalization.
- When evaluating interview candidates, rotate tasks and use broader corpora so candidates aren’t being judged on one narrow problem type.
Metrics to track (beyond BLEU)
- Functional pass rate: percent of tests passed.
- Time-to-correct: time or iterations to reach a passing solution.
- Flakiness rate: nondeterministic failures in the harness.
- Security/lint violations per run.
- Performance metrics: runtime and memory on representative inputs.
- Human-rated maintainability/readability (only for code that passes tests).
These metrics create a balanced view: correctness first, quality second.
Tips for interviewers
- Make tests explicit and runnable. Candidates shouldn’t have to infer hidden requirements.
- Favor behavior-driven prompts that specify inputs, outputs, and constraints.
- Use sandboxing to safely run untrusted code.
- If you care about design, require refactors or explain-the-design steps after a correct solution is produced.
- Avoid judging by style alone. A correct, concise solution is better than a verbose-looking one that fails edge cases.
Quick checklist for replacing BLEU in interviews
- [ ] Provide or require tests as the primary evaluation.
- [ ] Automate sandboxed execution and capture results.
- [ ] Enforce API/complexity/security constraints.
- [ ] Use cross-project/language hold-outs to measure generalization.
- [ ] Measure user satisfaction and readability only after tests pass.
Conclusion
BLEU is a surface metric that misaligns with what interviewers and engineers care about: working, safe, maintainable code. Replace BLEU with an evaluation strategy built on executable tests, constraint checks, cross-domain hold-outs, and post-correctness quality signals. That gives you objective, actionable measures of whether generated code actually solves the problem.
#MachineLearning #MLOps #AIEngineering

