
Stop Double-Counting Clicks: Deduplication Is the Interview Deal‑Breaker

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
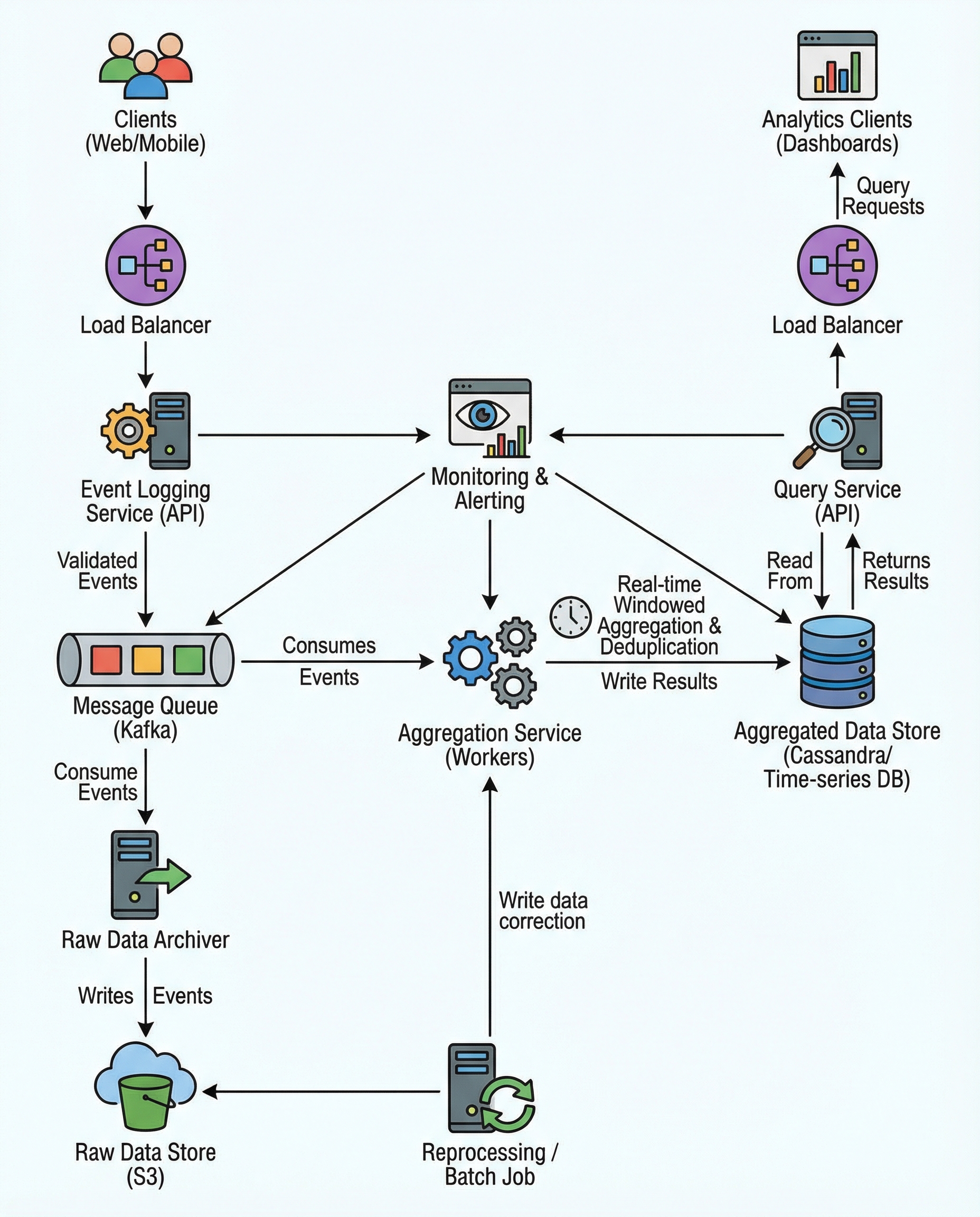
Why deduplication matters
In ad-click aggregation, deduplication isn't optional. With at-least-once delivery semantics (client retries, broker replays, consumer restarts), the same click event can be delivered multiple times. If your pipeline doesn't recognize duplicates, your counts are inflated and your metrics are unreliable.
The non-negotiable rule
Generate a stable event_id at ingestion (for example, a hash of ad_id + user_id + timestamp) and enforce idempotency downstream. Treat event_id as the canonical identifier for a click and use it everywhere you need uniqueness.
How to generate a stable event_id
- Use a deterministic combination of immutable fields: ad_id, user_id (or device_id), event timestamp (with sufficient resolution), and any client-provided click token if available.
- Hash the concatenated string (e.g., SHA256) to produce a compact ID.
Example (Python pseudocode):
import hashlib
def make_event_id(ad_id, user_id, ts_ms, click_token=None):
parts = [str(ad_id), str(user_id), str(ts_ms)]
if click_token:
parts.append(str(click_token))
raw = "|".join(parts)
return hashlib.sha256(raw.encode("utf-8")).hexdigest()
Where to dedupe (practical stages)
1) Ingestion — reject obvious client retries fast
- At the edge, compute event_id and check a fast cache (Redis, edge LRU) to short-circuit retries.
- Respond idempotently to clients (same acknowledgement for the same event_id) so clients stop retrying.
- This reduces downstream load and lowers end-to-end duplication latency.
2) Aggregation / Streaming consumers — short-lived "seen" set per window
- Maintain a per-key seen set (in-memory or state store like RocksDB in Flink/Kafka Streams) with TTL roughly equal to your replay tolerance window.
- When a record arrives, drop it if event_id is already seen for that time window.
- Use state TTL or expirations to bound memory. Redis with SETNX+EXPIRE, a Bloom filter (for memory efficiency, with acceptable false positives), or the streaming framework's keyed state with TTL are common approaches.
3) Storage / Warehousing — dedupe on write
- Enforce uniqueness at the destination: primary/unique key on event_id or upsert logic (INSERT ... ON CONFLICT DO NOTHING / MERGE semantics).
- This is your last line of defense. Even if upstream dedupe missed something, the store prevents double writes.
Details & corner cases
- Timestamp granularity: if your timestamp is coarse (seconds) two legitimate clicks may collide. Prefer ms or include a client-generated nonce/click_token.
- Clock skew: prefer server-ingestion timestamp as part of the event_id or combine both client and server timestamps carefully.
- Legitimate duplicates: decide business rules for near-duplicates (e.g., same user clicking the same ad twice within N seconds might be valid). Configure your seen-window accordingly.
- Memory/scale: use approximate structures (Bloom filters) for huge scale, but be aware of false positives. If precision is critical, use exact keyed state with eviction.
Idempotency patterns downstream
- Use event_id as a primary key in databases and metrics stores.
- For counters, apply upsert semantics or maintain per-event processed markers to ensure you only count once per event_id.
- Record processing results alongside event_id so retries can be answered from stored results.
Why this matters for interviews (and production)
If you can't clearly explain how to generate a stable event_id and where to dedupe (ingestion, aggregation, storage), your reported counts are fiction. Deduplication is both a practical pipeline requirement and a common interview litmus test for real-world streaming design knowledge.
If you implement this properly, you get accurate metrics, predictable load, and an easier-to-debug pipeline.
If you can’t explain this, your counts are fiction.
#DataEngineering #StreamingAnalytics #SystemDesign

