
System Design Interview: Build a Push Notification Service That Scales

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
System Design Interview: Build a Push Notification Service That Scales
Push notifications are short server→client messages used to drive engagement, re-engage users, and surface time-sensitive information (e.g., order updates, security alerts). In system design interviews you must show how you'd design a solution that scales to millions of messages per second while staying reliable, accurate, and secure.
Below is a concise, interview-friendly design: clear requirements, high-level architecture, critical components, scaling strategies, and trade-offs.
1. Core requirements (must-haves)
- Scalability: support millions of pushes/sec and large fan-out (one message → millions of devices).
- Reliability & correctness: no silent drops; once-and-only-once or at-least-once guarantees depending on use case.
- Targeting: segment by user preferences, behavior, region, device type, and A/B experiments.
- Analytics: capture delivery, open/click, and latency metrics for each notification.
- Security & authenticity: prevent spoofing and unauthorized sends; data in transit must be protected.
- Low latency for time-sensitive notifications; scheduling and rate-limiting for non-urgent messages.
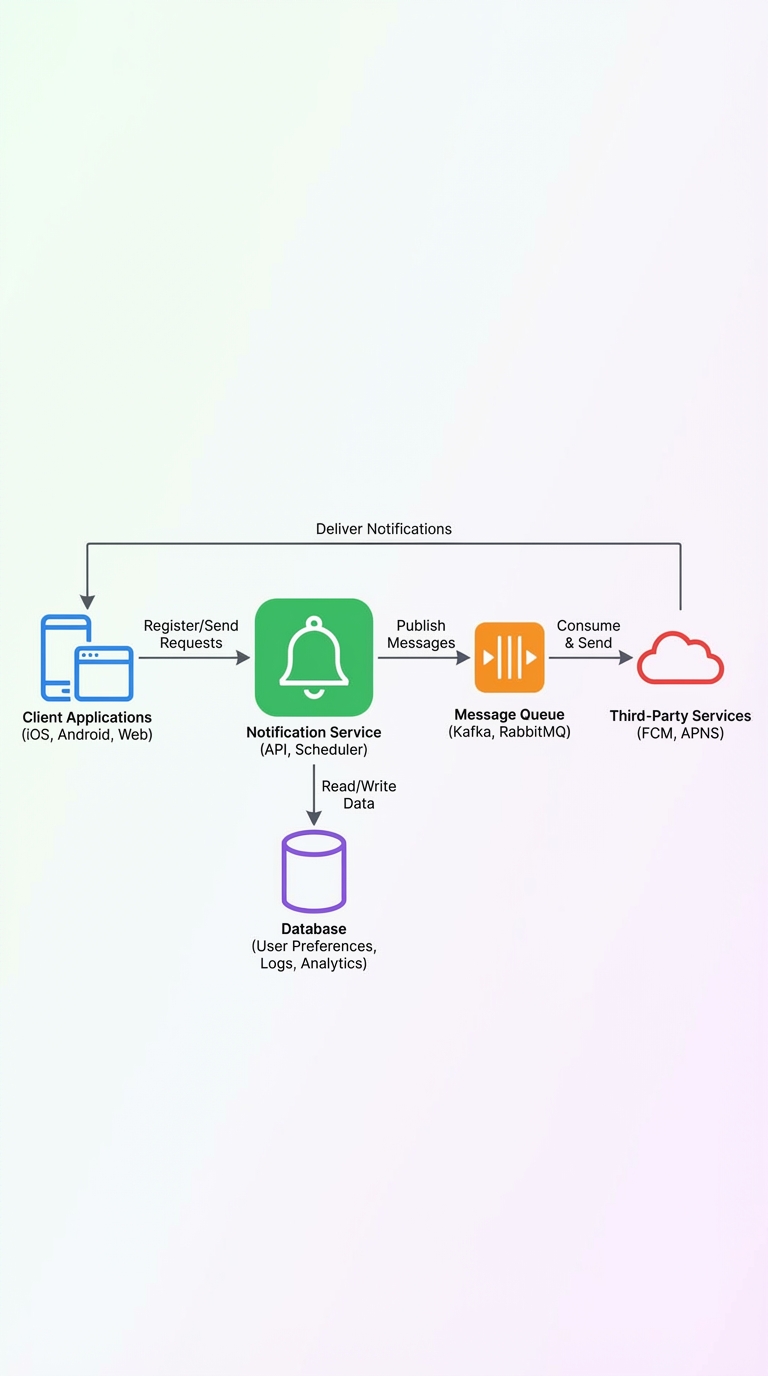
2. High-level architecture
- Clients register device tokens with the service.
- API layer accepts "send" and "schedule" requests.
- Message queue (e.g., Kafka) buffers bursts and preserves ordering for topics where needed.
- Worker/fan-out layer expands a message to target device tokens.
- External push services (FCM for Android, APNs for iOS) deliver to devices.
- Datastore for user preferences, device tokens, and logs.
- Cache (Redis) for hot preferences and recent device lists.
- Monitoring, metrics, and analytics pipeline to collect delivery/open events.
3. Component details
API Layer
- Authenticated REST/gRPC endpoints for producers (apps, backend services).
- Validation, quota checks, and basic targeting filtering.
- Persist send requests to persistent queue or primary DB (if scheduled).
Message Queue
- Durable topics for spikes and retry logic.
- Partitioning by target shard (user id or topic) to allow parallelism and ordering.
Fan-out Workers
- Read from queue, resolve target device tokens (from cache/DB), apply preferences and rate limits, then batch requests to FCM/APNs.
- Implement retry/backoff and idempotency keys for at-least-once delivery semantics.
Device Token Store
- Stores mapping: user_id → [device_token, platform, last_active, locale, prefs].
- TTL on stale tokens; periodic cleanup for invalid tokens.
Cache
- Redis caching frequently used device lists and user prefs to reduce DB load.
Delivery Adapters
- Thin adapters for FCM/APNs with connection pooling and exponential backoff.
- Track feedback (invalid tokens) and update token store.
Analytics Pipeline
- Event ingestion (delivery, click/open) → stream processing (Kafka/Fluentd) → OLAP storage for dashboards and reports.
Monitoring & Alerting
- Track success rate, latency percentiles, queue depth, error rates, and downstream service limits.
4. Scaling strategies
Horizontal scaling
- Partition work by user ID, topic, or geographic shard. Scale API, workers, and adapters independently.
Batching and connection pooling
- Batch tokens per device platform to reduce number of requests and maximize throughput.
Backpressure and throttling
- If downstream (FCM/APNs) quota reached, apply graceful degradation, queueing, or rate limiting.
Hot key mitigation
- Very popular topics (e.g., global announcement) should be handled with a publish/subscribe topic and parallel delivery shards.
Caching
- Cache audience resolution to avoid repeated DB lookups for frequent sends.
5. Reliability and correctness
Delivery guarantees
- For critical notifications (security), aim for at-most-once with strong idempotency and confirmation flows, or at-least-once with deduplication on the client.
Retries & DLQ
- Retries with exponential backoff and a Dead Letter Queue (DLQ) for messages that repeatedly fail.
Idempotency
- Use message IDs to detect and ignore duplicates in workers and delivery adapters.
Validation of delivery
- Correlate downstream acknowledgements and device events to verify delivery; mark tokens invalid when FCM/APNs reports them.
6. Targeting & personalization
Audience selection
- Support arbitrary predicates (segments by event, attributes, cohorts) computed via precomputed audience lists (offline) or real-time filtering.
Preferences and suppression
- Respect user opt-outs, Do Not Disturb windows, and platform-specific rate limits.
A/B testing
- Include campaign metadata and track variants in analytics.
7. Analytics & observability
- Events to capture: enqueue, dispatch, delivery ack, failure, open/click, bounce.
- Stream these to a metrics pipeline to compute KPIs in near real-time.
- Expose dashboards for queue depth, success rate, latency P95/P99, and platform error breakdowns.
8. Security
- Authenticate producers with short-lived tokens and RBAC.
- Sign messages and use HTTPS/TLS for all transport.
- Audit logs for sends and admin actions.
- Rate-limit to prevent abuse and spoofing.
9. Data model (simplified)
- DeviceToken { user_id, token, platform, created_at, last_active, status }
- Notification { id, payload, audience, scheduled_at, priority, sender_id }
- DeliveryLog { notification_id, device_token, status, attempt_count, last_error, timestamp }
10. Capacity planning (simple example)
- If average payload + headers per request is 1 KB and you need 1M messages/sec, bandwidth ~1 GB/sec (≈8 Gbps). Design network and adapter pooling accordingly.
- Use batching (e.g., 500 tokens/batch) to reduce concurrent connections and control outbound throughput.
11. Trade-offs and interview talking points
- At-least-once vs at-most-once: choose based on business needs (e.g., marketing can tolerate duplicates; security alerts cannot miss).
- Strong ordering is expensive: only enforce per-user or per-topic when required.
- Cost vs freshness: precompute audiences for large campaigns vs compute them on demand for targeted real-time sends.
12. Quick interview checklist
- State requirements and SLAs first.
- Draw the high-level flow: Client → API → Queue → Workers → FCM/APNs → Device.
- Discuss partitioning, batching, backpressure, retries, and idempotency.
- Cover analytics, monitoring, and security.
- Mention trade-offs and optimizations for cost and latency.
Designing a push notification service in an interview is about clarity: show how components interact, explain your scaling levers, and justify trade-offs based on correctness, latency, and cost.

