
Same Data, Same Model… Different Results? The One Detail Interviewers Want You to Say
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Same Data, Same Model… Different Results? The One Detail Interviewers Want You to Say

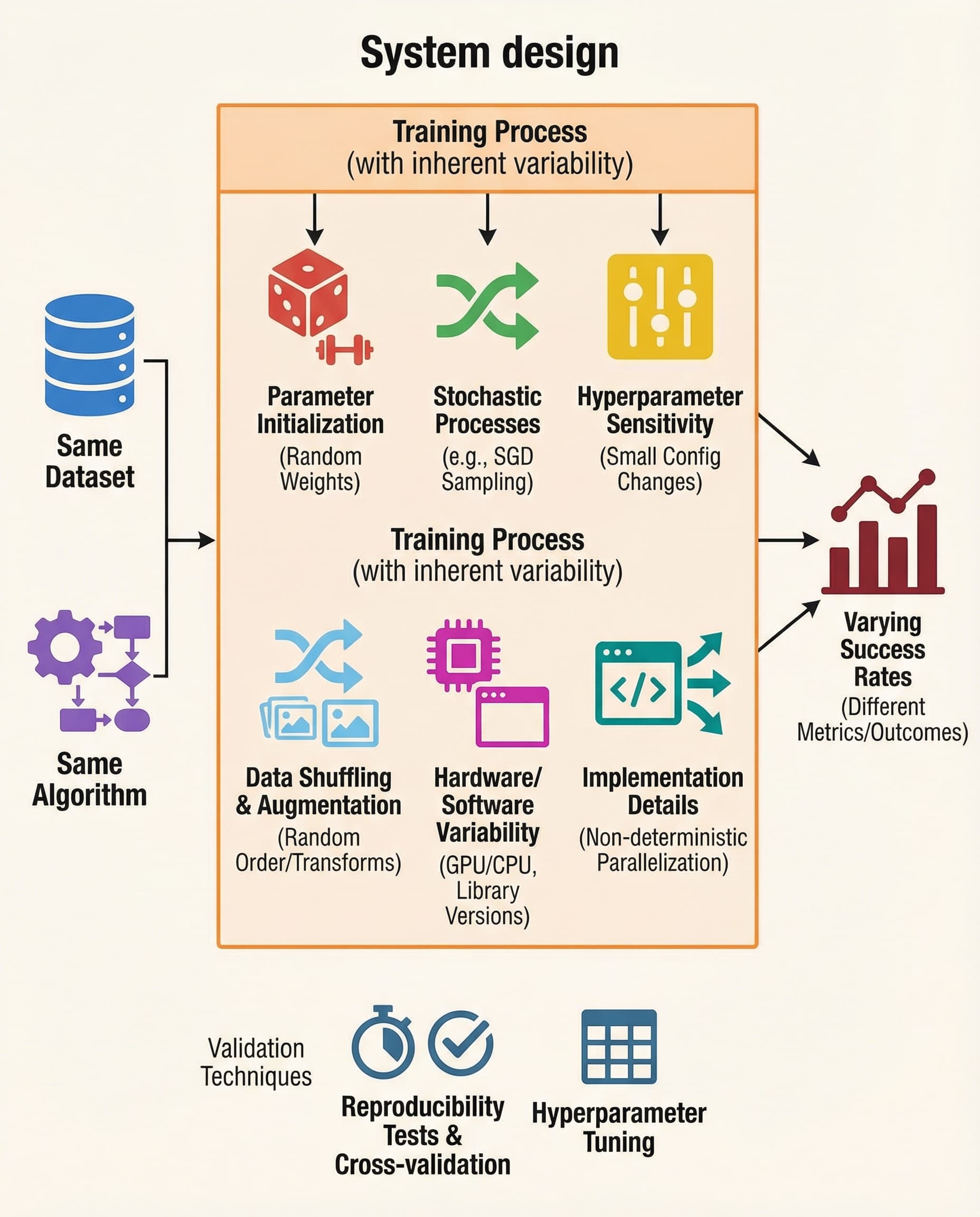
In interviews, don’t lead with "noise" as your first explanation. The single most important point to call out is non-determinism arising from randomness and compute. In short: even with the same dataset and algorithm, tiny sources of randomness and floating‑point differences can steer training down different optimization paths.
Why identical data + model can produce different results
- Random initialization and SGD ordering: random weight seeds and the order of mini-batches change the optimization trajectory; small early differences can amplify.
- Data shuffling and augmentation: what the model "sees" first affects learning, especially with non-convex objectives.
- Hardware, drivers and libraries: different GPUs/CPUs, CUDA/cuDNN versions or BLAS implementations cause tiny floating‑point differences that can accumulate.
- Framework non-determinism: some operations are inherently non-deterministic (atomic adds, parallel reductions), and different library versions may change implementation details.
What interviewers want to hear (concise phrasing)
"I’d point out non-determinism from randomness and compute. To address it, I’d fix and document seeds, log environment and library versions, and run repeated trials (or k‑fold CV) to report mean ± std. If strict determinism is required, enable deterministic ops and lock versions — noting this can incur a performance cost."
Practical, actionable steps to improve reproducibility
Fix random seeds consistently
Python, NumPy, framework and GPU seeds (examples):
# PyTorch
import random, os
import numpy as np
import torch
seed = 42
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# TensorFlow
tf.random.set_seed(42)
Make data pipeline deterministic where possible
Use deterministic augmentations or fixed random states for augmentation libraries.
Set dataloader workers to 0 or use deterministic worker initialization where supported.
Log environment and versions
Record OS, Python, framework (PyTorch/TensorFlow) versions, CUDA, cuDNN, driver and GPU model.
- Helpful commands:
pip freeze,nvidia-smi,nvcc --version. Save the seed and environment info alongside model checkpoints and experiment logs.
Use deterministic/backward flags and environment variables when needed
PyTorch:
torch.use_deterministic_algorithms(True)andtorch.backends.cudnn.deterministic = True(may slow training).- Newer NVIDIA setups: set
CUBLAS_WORKSPACE_CONFIGand related env vars if using cuBLAS deterministic features. Be aware: enforcing determinism can change numerical behavior and slow performance.
Containerize and pin dependencies
Use Docker containers or conda environments with exact package versions to make experiments portable and reproducible.
Run repeated trials and report uncertainty
Perform multiple independent runs (e.g., 5–10) or k‑fold cross‑validation.
Report mean ± standard deviation (or CI) for key metrics rather than a single run.
Automation and logging
Automate experiments with scripts and log metadata (seed, commit hash, command-line args) to experiment trackers (MLflow, Weights & Biases, etc.).
- Include the seed in model filenames and experiment metadata.
Quick checklist to state in interviews
- "I’d lock seeds, log environment and package versions, run multiple trials (or k‑fold CV) and report mean±std. If necessary, enable framework deterministic flags and pin dependencies in a container."
Notes and tradeoffs
- Full determinism is sometimes impossible or too costly; focus on reducing sources of variance and transparently reporting uncertainty.
- Small differences can be acceptable if you quantify them and they don’t change your model selection.
Bottom line: interviewers want to hear that you understand the true causes (randomness + compute) and that you have concrete steps—seeds, versioning, repeated trials—to diagnose and mitigate them.
#MachineLearning #Reproducibility #MLOps #DataScience

