
Backup Interviews: The One Detail That Separates Seniors—Resumable, Chunked Uploads
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.

Backup Interviews: The One Detail That Separates Seniors—Resumable, Chunked Uploads
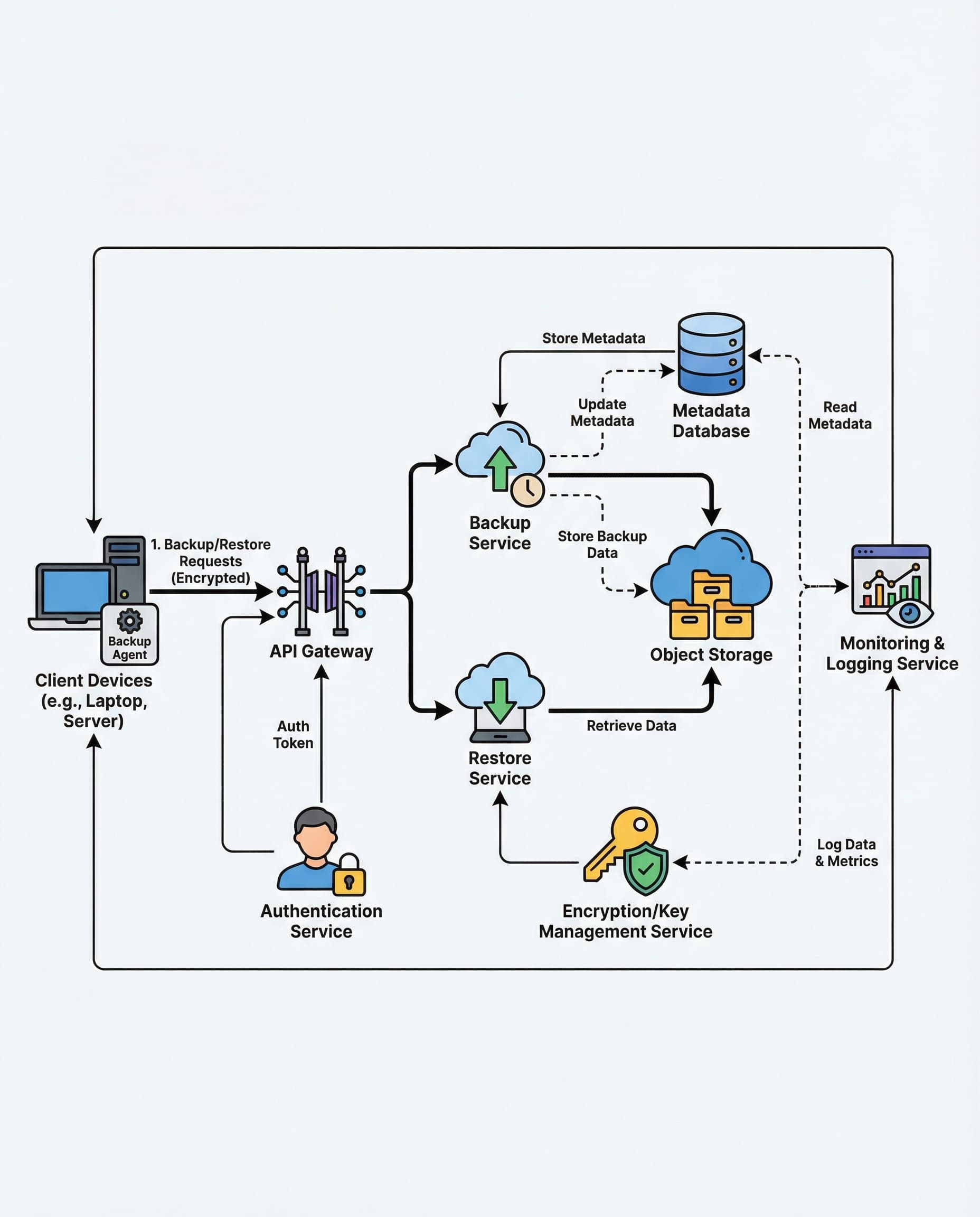
In cloud backup systems the simplest reliability lever is also the one interviewers love to ask about: resumable, chunked uploads. Backups regularly fail mid-transfer — Wi‑Fi drops, laptops sleep, cellular blips. If you upload whole files atomically, you often restart from zero and miss backup windows. Splitting data into chunks and making uploads resumable changes the game.
Below is a practical, interview-friendly design pattern you can explain and defend.
Problem
- Long transfers are brittle: network interruptions, client restarts, and transient server errors will abort uploads.
- Re-uploading entire files wastes time, bandwidth, and energy, and increases collision with backup windows.
High-level solution
- Split files into fixed-size chunks.
- Hash each chunk and use an idempotent API like
putChunk(backupId, chunkIndex, checksum). - Persist progress (which chunks are stored) in per-backup metadata so the client can resume exactly where it stopped.
- Add exponential backoff, integrity checks, and duplicate handling on the server.
This combination makes uploads resumable, verifiable, and efficient.
Core components
1) Chunking
- Use fixed-size chunks (e.g., 4–16 MiB). Fixed size simplifies indexing and retry logic. Consider variable chunking only for dedup-heavy designs.
- Compute a checksum (SHA-256 or a strong hash) per chunk. This enables integrity checks and idempotency.
Trade-offs:
- Small chunks: better resume granularity, larger index/metadata.
- Large chunks: fewer round trips, worse restart cost on failure.
2) Idempotent chunk upload API
Provide a server API like:
putChunk(backupId, chunkIndex, checksum, data)
Server behavior:
- If chunkIndex already stored with the same checksum: return success (idempotent).
- If stored with different checksum: reject (checksum mismatch) to avoid corruption.
- If not present: store chunk and mark it in metadata.
This avoids duplicate work and ensures safe retries.
3) Persisted progress (metadata)
Keep a per-backup metadata object that tracks which chunk indices are already accepted. Minimal metadata schema:
{
"backupId": "...",
"fileId": "...",
"chunkSize": 4194304,
"chunks": {
"0": "sha256:...",
"1": "sha256:...",
"4": "sha256:..."
},
"status": "in_progress"
}
The client can query this metadata and resume uploading only missing chunks. Persist metadata atomically (or use a compare-and-set) so progress is never lost.
4) Retries and backoff
- Use exponential backoff with jitter for transient errors.
- On client restart, re-check metadata and only upload missing chunks.
- Limit retry budget per chunk to avoid infinite loops.
5) Integrity and verification
- Server verifies chunk checksum on receive; reject corrupted uploads.
- Optionally: server computes its own checksum and cross-checks client-supplied checksum.
- After all chunks uploaded, perform a final composition step that verifies the assembled file hash matches the expected file hash (if provided).
Example resumable upload flow (client)
- Split file into chunkCount chunks and compute checksums.
- Request or create
backupIdand read metadata about already-uploaded chunks. - For each missing chunk:
putChunk(backupId, chunkIndex, checksum, data)with retries/backoff- On success, record progress locally or rely on server metadata
- When all chunks present, call
finalizeBackup(backupId, expectedDigest)which triggers server-side verification and composition.
Pseudocode:
for i, chunk in enumerate(chunks):
if server_has_chunk(backupId, i):
continue
attempt = 0
while attempt < MAX_ATTEMPTS:
try:
putChunk(backupId, i, checksum(chunk), chunk)
break
except TransientError:
sleep(exponential_backoff(attempt))
attempt += 1
if attempt == MAX_ATTEMPTS:
raise UploadFailed
finalizeBackup(backupId, fileChecksum)
Server-side considerations
- Atomic metadata updates: use compare-and-swap to avoid races when multiple clients upload the same backup.
- Garbage collection: remove orphaned chunks after a timeout or when a backup is abandoned.
- Authorization: ensure clients can only write chunks for their backups.
- Storage layout: store chunks keyed by (backupId, chunkIndex) or by checksum (content-addressed) to enable deduplication.
- Concurrency: allow parallel chunk uploads to speed up large backups; throttle to control IO.
Additional enhancements
- Content-addressed storage: store chunks by checksum to deduplicate across backups and users (watch multi-tenant privacy/legal constraints).
- Client-side encryption: encrypt chunks before upload; store per-backup metadata for decryption keys (or use zero-knowledge patterns).
- Partial restores: let clients request ranges or subsets of chunks for faster restores.
Interview-ready takeaway
Reliability in backups is not a single promise you make to users — it's a protocol you design and implement: chunk, hash, idempotent put, persist progress, retry with backoff, and verify. Explain the trade-offs (chunk size, metadata complexity, concurrency) and you've shown the mentality of a senior engineer: think beyond "it works once" to "it recovers gracefully."
#CloudComputing #SystemDesign #DevOps

