
Read-Through vs Write-Behind Cache: Know the Trade-offs (Interview Must)

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
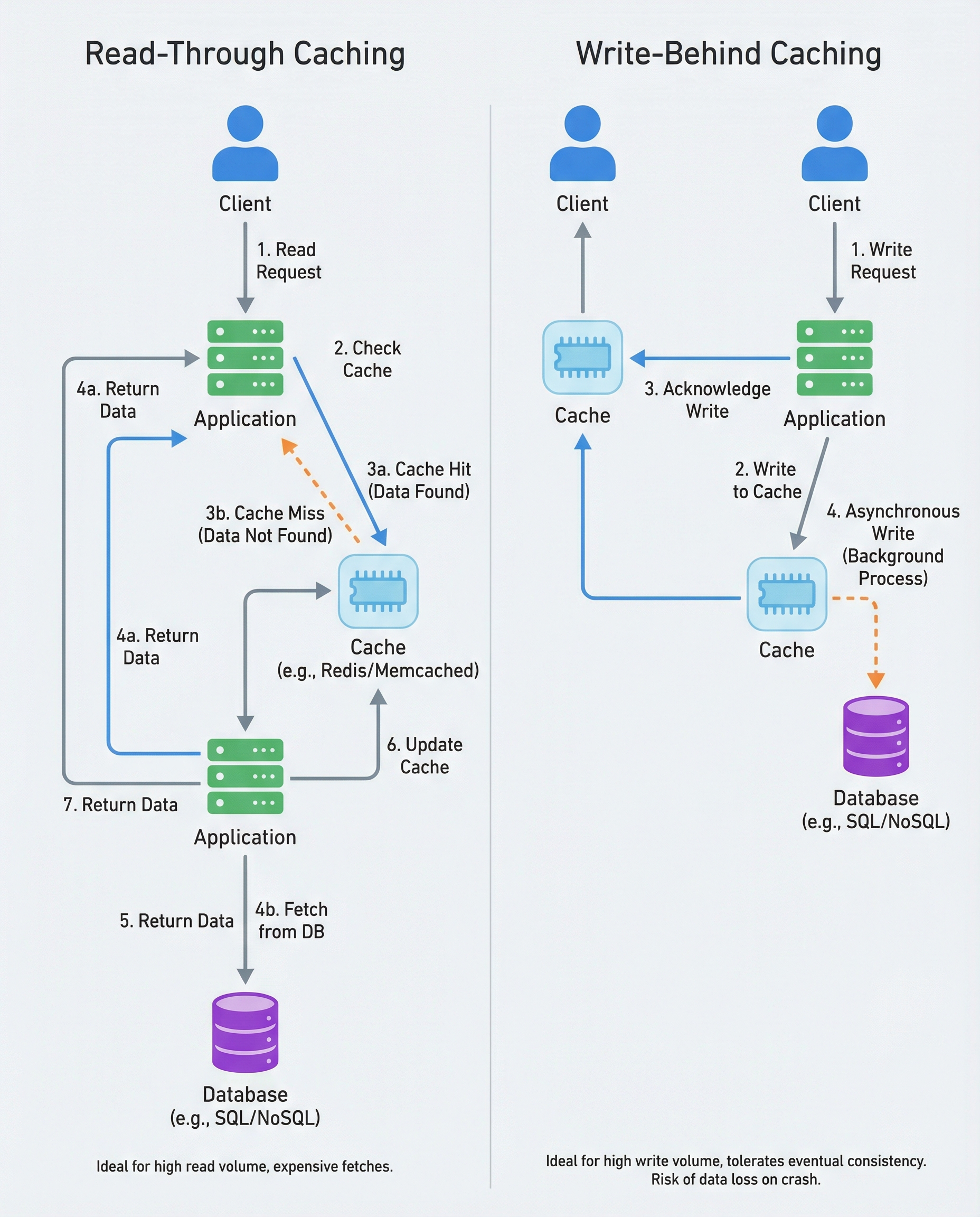
Caching is not "add Redis and pray." In interviews you must be able to explain which caching pattern you picked, why, and how you'll defend it under failure. Two common patterns are Read-Through and Write-Behind. Below is a compact guide you can use in interviews and design discussions.
Patterns — what they do
Read-Through
- Flow: application reads cache first; on a cache miss, the cache layer (or the application) fetches the data from the DB, returns it to the caller, and populates the cache.
- Good when: reads are frequent, the DB fetch is relatively slow/expensive, and you want cache population to be transparent.
- Consistency: synchronous read path, but must handle invalidation and stale reads.
Write-Behind (a.k.a. write-back)
- Flow: application writes to the cache and returns immediately. The cache asynchronously persists the change to the database later.
- Good when: extremely high write throughput is required, you want to batch DB writes, or reduce DB write latency.
- Consistency: eventual consistency. Risk of data loss if the cache fails before persistence.
(For completeness: write-through synchronously writes both cache and DB on each update — safer but slower than write-behind.)
Quick pros & cons
Read-Through
- Pros: simple semantics for reads, cache automatically refreshed on miss, good read latency.
- Cons: cache invalidation complexity (stale reads), potential stampedes on misses, added read latency on cold misses.
Write-Behind
- Pros: low write latency, batching reduces DB load, good for bursty writes.
- Cons: eventual consistency, possible data loss on cache crash, complexity of ensuring durability and ordering.
Failure modes and mitigations (what interviewers expect you to defend)
Stale reads (Read-Through)
- Mitigations: short TTLs for volatile data, cache invalidation on writes (delete/update), versioned data, read-your-writes guarantees where needed.
Cache stampede (Read-Through)
- Mitigations: request coalescing (single flight), locking / mutex in cache layer, probabilistic early refresh (refresh-ahead), background warming.
Lost writes (Write-Behind)
- Problem: cache accepted write but crashed before persisting.
- Mitigations:
- Use a durable message queue or write-ahead log (Kafka, persistent queue) for changes so they survive process restarts.
- Persist updates to an append-only log before acknowledging the client.
- Replicate cache (clustered cache) and ensure replication is durable.
- Use synchronous persist for critical ops (hybrid approach: write-through for critical, write-behind for bulk).
Ordering and idempotency (Write-Behind)
- Ensuring eventual persistence happens in correct order and duplicates don't break correctness.
- Mitigations: include sequence numbers/versions, make DB writes idempotent, use compaction of older updates.
Backpressure and queue buildup (Write-Behind)
- Mitigations: backpressure to clients, throttling, fall back to synchronous DB writes when queue is full.
Consistency expectations (both patterns)
- Be explicit about SLA: strong consistency vs eventual consistency, acceptable staleness window, and what user operations require synchronous durability.
Implementation hints
For safe write-behind:
- Before acknowledging client: append change to a durable queue (disk-backed or Kafka). Let a separate consumer persist to DB, retry on failure.
- Ensure idempotent consumers or make DB writes conditional on version.
For read-through caches:
- Implement single-flight to avoid stampedes.
- Use TTLs + proactive refresh for hot keys.
- Consider cache-aside approach (application manages cache) if you need explicit control.
Instrumentation:
- Track cache hit ratio, write queue depth, persistence lag, and error/retry rates. These numbers justify your choice in interviews.
When to choose which
Choose Read-Through (or cache-aside) when:
- You need low read latency, reads greatly outnumber writes, and DB fetch cost is high.
- You can tolerate occasional cold misses and handle invalidation.
Choose Write-Behind when:
- You must minimize write latency and handle very high write throughput.
- You can accept eventual consistency and will build durable buffering to avoid data loss.
Hybrid approaches:
- Use write-through for critical operations (payments, accounting) and write-behind for analytics/telemetry.
- Use read-through with a durable write queue so reads benefit while writes are buffered safely.
Interview-ready summary (short script)
- State the pattern and why: “I’d use Read-Through because this service is read-heavy and DB reads are costly.”
- Clarify consistency SLA: “We need read latency under X ms; we can tolerate Y seconds of eventual consistency.”
- Call out failure modes: “Main risks are stale reads and cache stampedes.”
- Describe mitigations: “We’ll use TTLs, single-flight, and background refresh. If we need stronger durability on writes, we’ll use a durable queue or switch to write-through for those endpoints.”
- Metrics to monitor: cache hit ratio, miss latency, persistence lag, and queue size.
Rule of thumb: optimize reads with Read-Through; optimize writes with Write-Behind — then be prepared to defend the failure modes and describe concrete mitigations.
#SystemDesign #SoftwareEngineering #TechInterviews

