
Read-Through vs Write-Behind Cache: Know the Trade-offs (Interview Must)

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Read-Through vs Write-Behind Cache: Know the Trade-offs
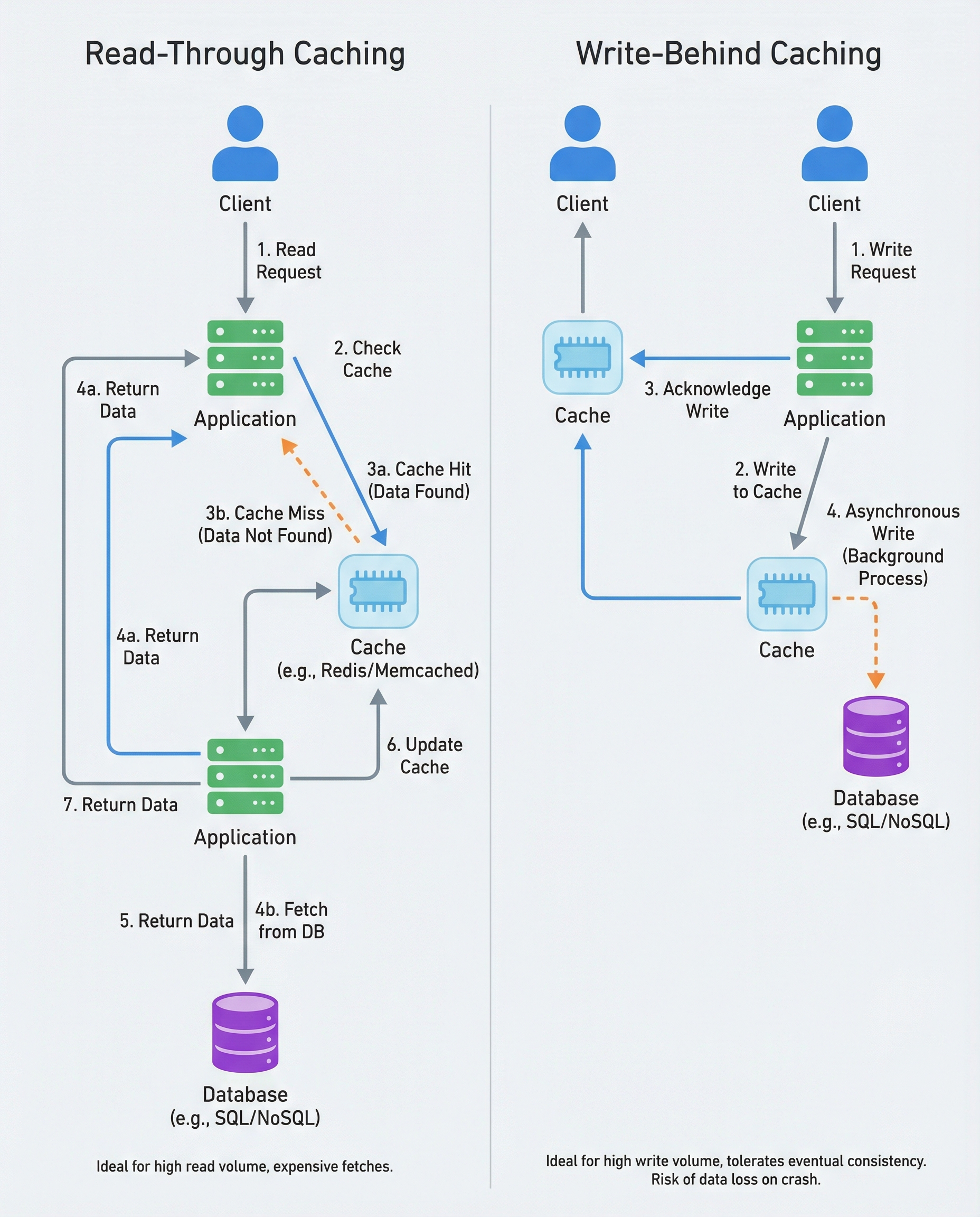
Caching is not “add Redis and pray.” Interviewers expect you to name a caching pattern, justify it, and defend its failure modes. Two common patterns you should know are Read-Through and Write-Behind. Below is a concise, interview-ready guide explaining how each works, when to use it, the trade-offs, and how to defend your choice.
Quick summary
- Read-Through: Application reads cache first; on a miss, it fetches from the database and populates the cache. Best for read-heavy, expensive-to-fetch data. Watch invalidation and stale reads.
- Write-Behind (Asynchronous Write): Application writes to the cache first; the cache persists to the database asynchronously. Useful for high write throughput and batching, but introduces eventual consistency and some durability risks.
Read-Through Cache
How it works
- App attempts to read from cache.
- If cache hit: return cached value.
- If cache miss: read from the database, populate the cache, then return the value.
When to choose it
- Read-heavy workloads (hot data repeatedly requested).
- Data is expensive/slow to compute or fetch.
- Stronger read latency SLAs.
Benefits
- Simple to reason about for reads: if cache hit, very fast.
- Keeps cache warm automatically as reads occur.
- Easier to maintain stronger read consistency if you handle invalidation carefully.
Drawbacks and failure modes
- Cache invalidation complexity: updates must invalidate or update the cache, or clients risk stale reads.
- Hot-spot or stampede on cache miss: many requests might simultaneously miss and hit the DB.
- Cold-start cost: first read after eviction or deployment is slow.
Mitigations
- Use TTLs (time-to-live) to bound staleness.
- Implement cache-aside with locking or request coalescing to prevent stampedes (e.g., mutex, singleflight, token bucket).
- For writes, choose invalidation or update-on-write strategy and explain trade-offs (immediate update vs simple invalidate).
Interview script (short)
"I’d use read-through for read-heavy workloads where reads are latency-sensitive. I’d ensure proper invalidation or use short TTLs and request coalescing to avoid stampedes. If consistency is required, I’d update the cache on writes or use a small write-through path—otherwise accept bounded staleness."
Write-Behind Cache (Asynchronous Write)
How it works
- App writes the new value to the cache immediately.
- The cache (or an associated process) queues the change and writes it to the database asynchronously (often batched).
- Reads usually happen from the cache, which has the latest value.
When to choose it
- High write throughput where batching or aggregation reduces DB load.
- Use cases that tolerate eventual consistency (analytics counters, session stores, temporary state).
- When write latency must be minimal for the client.
Benefits
- Very low write latency for clients.
- Allows batching and merge operations (reduce DB writes, improve throughput).
- Can significantly reduce database write pressure in write-heavy systems.
Drawbacks and failure modes
- Eventual consistency: reads from other clients or services that read the DB directly may see stale data.
- Durability risk: if the cache or process crashes before persisting to DB, recent writes can be lost.
- Operational complexity: need reliable queuing, retry logic, and monitoring for the async pipeline.
Mitigations
- Use durable queues (e.g., Kafka, persistent message queues) for the write-behind stream.
- Implement retries, idempotent writes, and at-least-once/ exactly-once considerations.
- Persist critical data synchronously or use write-ahead logs to avoid data loss.
- Provide clear SLAs: bound the asynchronous window and document eventual consistency for clients.
Interview script (short)
"I’d pick write-behind when write latency must be low and we can tolerate eventual consistency. I’d add a durable queue, idempotent DB upserts, and monitoring/alerts for backpressure or queue failures. For critical data, I’d not use write-behind and instead do synchronous writes."
Side-by-side trade-offs
- Latency: Read-Through optimizes read latency; Write-Behind optimizes write latency.
- Consistency: Read-Through can be made closer to strongly consistent with immediate cache updates; Write-Behind is inherently eventual.
- Complexity: Write-Behind is operationally more complex (queues, retries, idempotency). Read-Through mostly needs invalidation logic.
- Durability: Read-Through keeps the DB authoritative; write-behind risks losing unflushed updates unless mitigated.
Practical decision checklist
Ask these questions to choose a pattern:
- Is the workload read-heavy or write-heavy?
- Can the application tolerate eventual consistency? If no, avoid write-behind for critical paths.
- Is write latency for the client more important than durability?
- Can we add durable queuing and retries to reduce write-behind risks?
- Do we need batching/aggregation to reduce DB load?
If reads dominate and consistency is important: prefer Read-Through (or read-through + write-through/update-on-write). If writes dominate and low client latency and batching matter: consider Write-Behind with strong mitigations.
How to defend in an interview
- State the pattern and why you chose it (latency, throughput, consistency requirements).
- Enumerate the failure modes (stale reads, stampedes, data loss) and the specific mitigations you will apply.
- Explain fallback plans: how you detect and recover, how you roll back if queues get blocked, and which data must be persisted synchronously.
- Give an example metric or SLA you would use to validate the choice (e.g., 99th percentile write latency < 20ms with eventual persistence within 5s).
Short example answers
Read-Through answer: "For a product details page that’s read-heavy and slow to produce, I’d use Read-Through so we cache DB results automatically on miss. To avoid stampedes and staleness, I’ll use TTL, request coalescing, and update the cache on writes where strict consistency is required."
Write-Behind answer: "For real-time counters ingesting millions of events per second, I’d use Write-Behind to batch writes and keep client latency low. I’ll persist updates through a durable queue (Kafka), build idempotent upserts, and monitor queue lag to ensure we don’t lose data. For any data that must be immediately durable, I’d bypass write-behind."
Final takeaway
Choose Read-Through to optimize reads and simplify read-side consistency; choose Write-Behind to optimize write throughput and latency but only if you accept eventual consistency and invest in durable async plumbing. In interviews, clearly state the trade-offs, the failure modes, and how you’ll mitigate them.

