
ML System Design Interviews: The Only Framework You Need

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
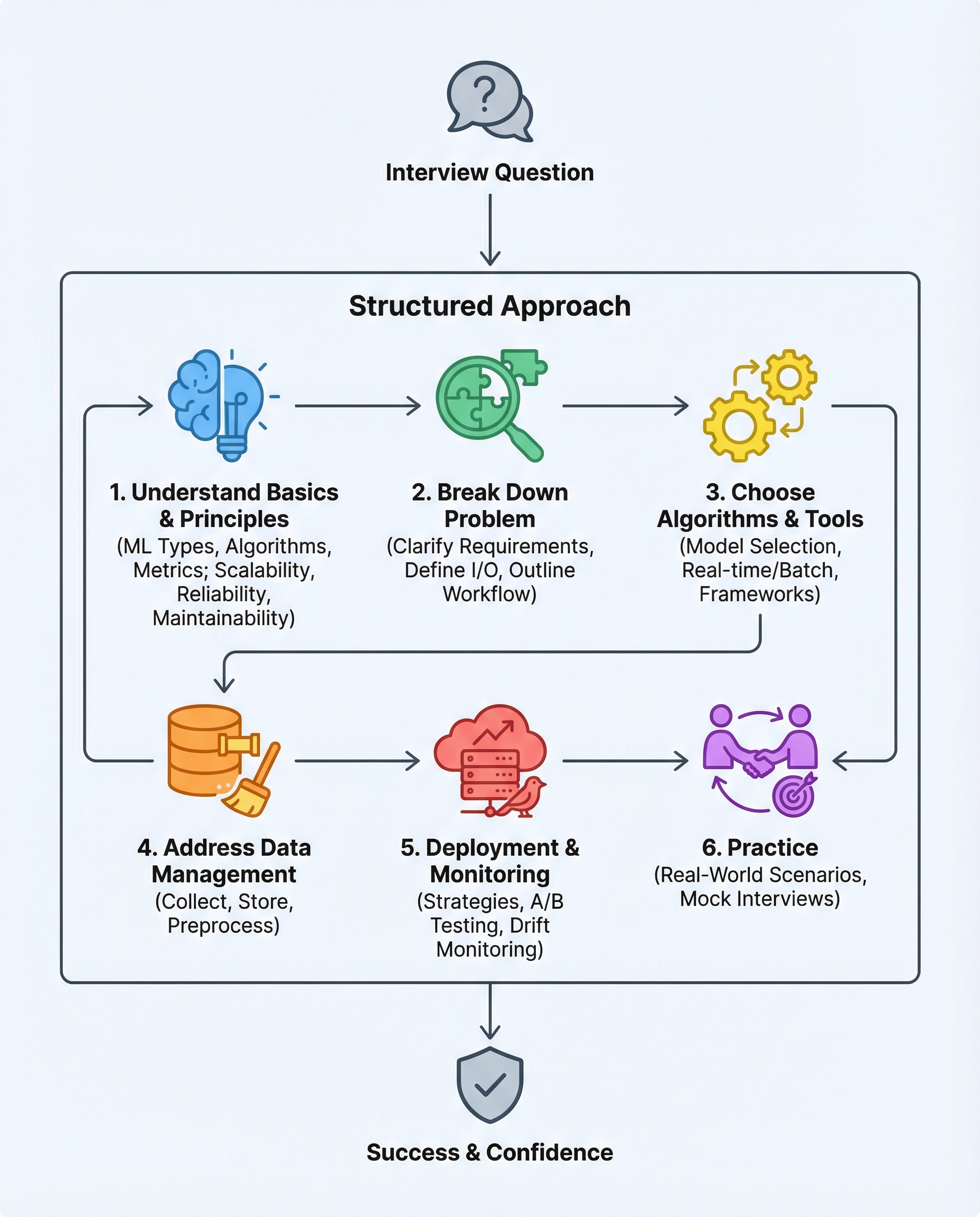
ML System Design Interviews: A Practical, End-to-End Framework
ML system design interviews assess more than modeling skill — they probe engineering judgment, trade-off reasoning, and operational thinking. Use this compact framework to structure your answers: clarify requirements, define inputs/outputs, sketch an end-to-end workflow, choose tooling based on constraints, nail data management, and explain deployment plus monitoring.
1) Start by clarifying requirements (don’t assume)
- Ask about business goals and success metrics: accuracy, latency, throughput, cost, fairness, explainability.
- Confirm constraints: data availability, privacy, regulatory, compute budget, and expected traffic patterns.
- Prioritize features: which parts are critical now vs. can be deferred?
Sample clarifying questions:
- "What latency is acceptable for a single prediction?"
- "Is this real-time user-facing or a batch offline process?"
- "How will we measure success in production?"
2) Define inputs and outputs clearly
- State the exact input schema (features, formats, sample sizes) and output format (probabilities, labels, ranks, embeddings).
- Call out upstream dependencies (APIs, event streams, label sources) and required preprocessing.
Example: "Input = user_id, item_id, session_features; Output = top-5 ranked items with scores."
3) Draw the end-to-end workflow (data → training → inference)
- Sketch the pipeline out loud: data ingestion → cleaning → feature pipeline → training → validation → model registry → serving → monitoring.
- Mention orchestration (Airflow, Kubeflow, or managed alternatives) and where human-in-the-loop steps (labeling, triage) fit.
A concise E2E breakdown:
- Data collection & storage (events, logs, labels)
- ETL / feature engineering (batch & online features)
- Model training & evaluation (cross-validation, A/B test plan)
- Deployment (canary, A/B, blue-green)
- Monitoring & retraining (drift detection, alerting)
4) Choose tools based on data size & latency needs
- Batch (large data, offline predictions): Spark, BigQuery, S3, batch inference jobs.
- Real-time (low latency): streaming (Kafka, Pub/Sub), online feature store, low-latency model servers (TF Serving, TorchServe, Triton), caching.
- Hybrid: offline training with online feature enrichment via feature store.
Explain trade-offs: complexity vs. latency, cost vs. freshness, eventual consistency vs. complexity of strong guarantees.
5) Be strict about data management
- Collection: ensure instrumentation, schema, and lineage.
- Storage: partitioning, TTL, retention policies, access controls.
- Preprocessing: deterministic transforms, handle missing values, normalization; version transforms with code and tests.
- Versioning & provenance: dataset and model versioning (DVC, MLFlow), reproducible training pipelines.
- Labeling & quality: label agreement metrics, active learning if labels are scarce.
6) Model training, metrics & evaluation
- Pick baseline algorithms first (logistic regression, tree ensembles) before complex models.
- Define metrics aligned with business goals (precision/recall, AUC, MAP, latency percentiles, throughput, resource cost).
- Validation strategy: holdout, cross-validation, temporal splits for time series.
- Safety checks: bias/fairness tests, adversarial and edge-case evaluations.
7) Deployment strategies (safely roll out changes)
- Canary: serve new model to small fraction, compare metrics.
- A/B testing: measure business KPIs with control vs treatment.
- Blue-green: switch traffic to a fully provisioned new environment.
- Rollback plan: automated or manual rollback triggers on metric regressions.
8) Monitoring & maintenance (production readiness)
- Monitor input data distribution, model predictions, key business metrics, latency, errors.
- Drift detection: input feature drift, label drift, prediction distribution changes.
- Alerting thresholds and automated remediation (retrain pipeline kickoffs, traffic throttles).
- Observability: logs, traces, model explainability outputs, and dashboards.
9) Scalability, reliability & maintainability
- Scalability: autoscaling model servers, sharding strategies, batching for throughput cost reduction.
- Reliability: retries, backpressure, graceful degradation, fallback models.
- Maintainability: modular pipelines, CI/CD for data and models, tests for data contracts and model outputs, clear runbooks.
10) Finish with trade-offs & next steps
- Summarize the main trade-offs you made (latency vs. freshness, cost vs. accuracy, complexity vs. speed to market).
- Propose a rollout plan: MVP, metrics to watch, and iteration roadmap.
Checklist to mention in interviews:
- Clarified goals & constraints
- Defined inputs/outputs
- Sketched E2E system
- Chosen tooling with trade-offs
- Addressed data management & versioning
- Described deployment & monitoring
- Listed scalability & reliability considerations
Common pitfalls to avoid:
- Jumping into model choice without clarifying requirements
- Ignoring data quality and pipeline reproducibility
- Leaving out monitoring or rollback plans
Wrap up: In ML system design interviews, think like a systems engineer who understands ML. Be methodical, justify trade-offs, and always connect technical choices back to business impact.
#MachineLearning #SystemDesign #MLOps

