
ML System Design Interviews: The 6 Things You Must Nail

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
ML System Design Interviews: The 6 Things You Must Nail
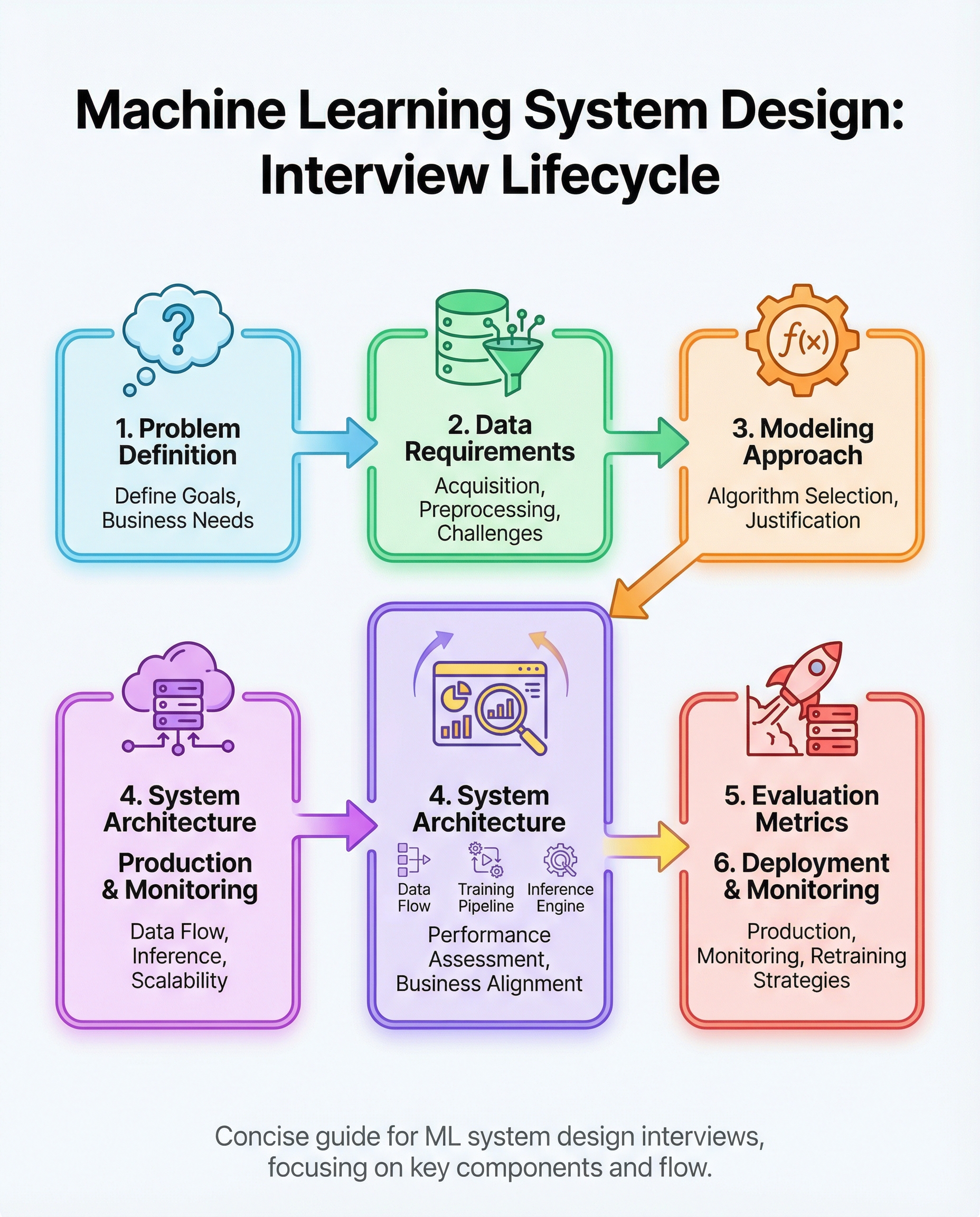
ML system design interviews evaluate whether you can design an end-to-end, production-ready machine learning system—not just train a model. Interviewers expect structured thinking across product, data, modeling, infrastructure, and operations.
Below are the six areas you must be ready to nail, with practical questions to ask, design choices to justify, and common trade-offs to discuss.
1) Define the business goal and constraints
- Start by clarifying the product objective: what business outcome are we optimizing (e.g., increase CTR, reduce fraud losses, improve retention)?
- Ask about constraints: latency, throughput, budget, regulatory/privacy rules, and SLAs.
- Translate the business goal into measurable objectives and KPIs (e.g., revenue uplift, false positive cost, time-to-detect).
- Example question to ask: What is the operational cost of a false positive vs a false negative?
Why this matters: A clear goal shapes everything downstream—data collection, model choice, evaluation metrics, and deployment strategy.
2) Specify data needs and the pipeline
- Identify data sources and ownership: user events, transactional databases, third-party feeds, labels.
- Sketch an ingestion pipeline: streaming vs batch, retention policy, privacy filters, and access controls.
- Describe cleaning and validation: schema checks, deduplication, handling missing values, and label quality.
- Define feature engineering strategy: online vs offline features, feature store, normalization, and feature drift monitoring.
- Consider labeling strategy: human labeling, heuristics, weak supervision, or distant supervision; include label latency and quality trade-offs.
Why this matters: High-quality, reliable data and features underpin stable production performance. Interviewers want to see you think beyond training data to production data flows.
3) Justify model choice
- Choose models appropriate to constraints and data: simple linear/logistic models, tree-based models, deep learning, or hybrid approaches.
- Discuss trade-offs: interpretability, inference latency, sample efficiency, ease of debugging, and retraining cost.
- Consider ensemble or cascaded models when needed (e.g., lightweight filter + heavyweight scorer).
- Explain planned regularization, calibration, and techniques to handle class imbalance (resampling, cost-sensitive loss, focal loss).
Why this matters: Interviewers want reasoning: why this model is the right fit, not just the best-performing one in isolation.
4) Design architecture for training and low-latency inference
- Training architecture: batch vs online training, distributed training needs, orchestration (Airflow, Kubeflow), experiment tracking, and reproducibility.
- Serving architecture: model server choices (TF Serving, TorchServe, custom microservice), caching, batching, and replication for scale.
- Latency considerations: model size, quantization, pruning, hardware (CPU vs GPU vs specialized accelerators), and timeout strategies.
- Feature availability: use of feature store and consistent online/offline feature computation to avoid training-serving skew.
Why this matters: A model that works offline can fail in production without an appropriate serving design and feature consistency.
5) Pick metrics tied to the business (and discuss trade-offs)
- Choose primary metrics that reflect business value (e.g., revenue per session, fraud detection cost saved, precision@k for ranking).
- Use secondary metrics to monitor health (latency, coverage, calibration, fairness metrics).
- Discuss thresholding and operating point selection (precision vs recall trade-off) and how it maps to business costs.
- Plan offline and online evaluation: holdout sets, time-aware splits, shadow launching, A/B testing, and safety guardrails.
Why this matters: Good metrics connect model performance to the real impact on users and the business.
6) Plan deployment, monitoring, drift detection, and retraining
- Deployment strategy: canary releases, staged rollout, blue/green or shadow deployment.
- Monitoring: data and prediction distributions, model metrics, latency, error rates, and business KPIs.
- Drift detection: detect covariate, concept, and label drift; set alerts and define thresholds for investigation.
- Retraining lifecycle: automated vs manual retraining, validation gates, continuous training pipelines, and rollback plans.
- Operational concerns: logging, explainability for root cause, runbooks, and SLOs for incident response.
Why this matters: Production ML is an ongoing process—robust monitoring and retraining are essential for long-term value.
Practice scenarios and quick pointers
Recommender systems (recsys): handle cold-start, feedback loops, diversity and fairness, and optimize for business metrics like conversion or retention. Use offline ranking metrics (NDCG, precision@k) plus online A/B testing.
Fraud detection: expect extreme class imbalance and adversarial behavior. Prioritize low-latency inference, cost-sensitive metrics, and human-in-the-loop review with easy explainability.
Imbalanced classes: prefer precision/recall and PR curves over accuracy. Use resampling, class weights, threshold tuning, and calibration techniques.
Quick checklist to use during the interview
- Clarify the product goal and constraints
- Outline data sources and label strategy
- Propose a model and justify it with trade-offs
- Sketch training and serving architecture (feature consistency)
- Select business-aligned metrics and evaluation plans
- Describe deployment, monitoring, drift detection, and retraining plan
Common pitfalls to avoid
- Focusing only on model training without addressing data and serving
- Ignoring label quality and distributional differences between train and prod
- Choosing an over-complicated model when a simpler approach meets business needs
- No plan for monitoring, drift detection, or incident response
Master these six areas and you’ll show interviewers that you can design ML systems that survive and deliver value in production—not just win on a leaderboard.
Good luck, and practice designing systems for recsys, fraud, and imbalance cases to build intuition across common trade-offs.
#MachineLearning #SystemDesign #DataScience

