
ML System Design Interviews: The 6 Things You Must Nail

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
ML System Design Interviews: The 6 Things You Must Nail
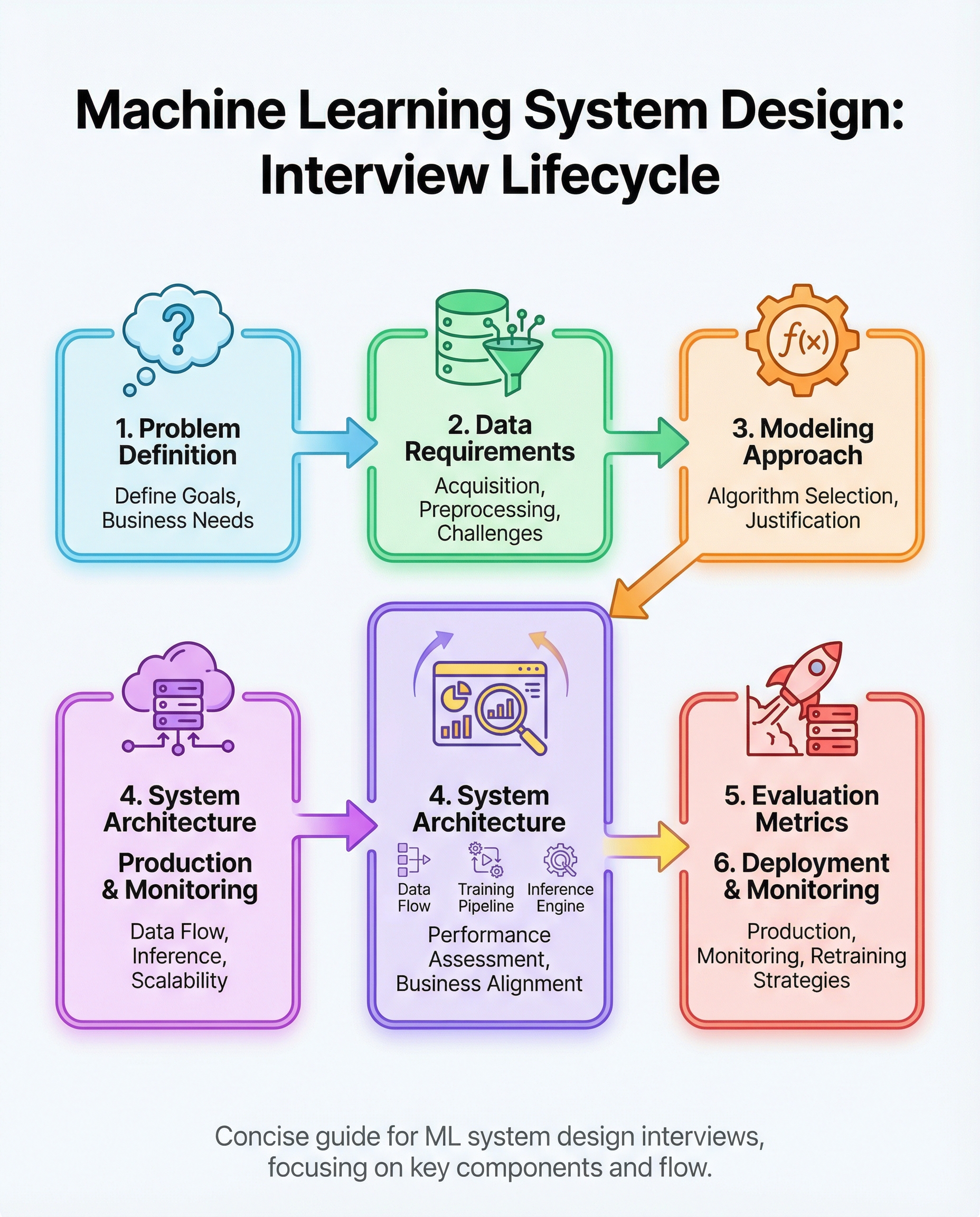
Machine-learning system design interviews evaluate your ability to design an end-to-end, production-ready ML solution — not just to train a model. Interviewers expect a structured approach that balances business goals, data realities, engineering trade-offs, and maintainability.
Below are the six areas you must cover and how to communicate them clearly in an interview.
1) Define the business goal and constraints
- Start by clarifying the objective: What business metric moves when this system succeeds? (e.g., click-through rate, fraud reduction, revenue per user).
- Ask about constraints: latency requirements, throughput, cost, privacy/regulatory limits, data retention, and SLAs.
- Sketch success criteria and failure modes the interviewer should care about.
Interview tip: Restate the goal and constraints before diving deeper to confirm alignment.
2) Specify data needs and the pipeline
- Describe data sources: events, logs, labeled datasets, third-party feeds.
- Outline collection and ingestion: batch vs. streaming, labeling process, sampling strategies.
- Cleaning and validation: missing values, deduplication, outlier detection, schema validation.
- Feature engineering: online vs. offline features, feature freshness, and versioning.
- Data storage and access: feature store, data lake, time-partitioned tables.
Interview tip: Mention data quality checks and how they affect downstream model performance.
3) Justify your model choice
- Trade-offs: complexity vs. interpretability, accuracy vs. latency, offline training cost vs. online inference cost.
- Candidate models: linear models for speed and interpretability, tree-based models for tabular data, neural nets for high-dimensional or sequential inputs, embeddings for recommendations.
- Explain why you chose a model family and fallback strategies (simpler baseline models).
Interview tip: If uncertain, propose a simple baseline first and describe an upgrade path.
4) Design architecture for training and low-latency inference
- Training architecture: distributed training vs. single-node, hyperparameter tuning, offline evaluation pipelines, CI for models.
- Inference architecture: online serving (low-latency), batch scoring (offline), caching, feature retrieval latency mitigation.
- Scalability: autoscaling, model sharding, A/B and canary deployments.
- Reliability: retries, graceful degradation, and fallbacks if features are missing.
Interview tip: Draw or verbally describe the flow: data → training → model registry → serving → monitoring.
5) Pick metrics tied to the business (and discuss trade-offs)
- Choose metrics that map to business outcomes: precision/recall for fraud; CTR/Conversion for recommender systems; F1 or ROC-AUC for imbalanced tasks.
- Discuss thresholds and operating points: when to prioritize precision over recall (e.g., fraud) and vice versa (e.g., discovery features in recommender systems).
- Secondary metrics: latency, throughput, cost-per-inference, and model fairness metrics.
Interview tip: Show you understand the cost of false positives vs. false negatives and propose monitoring alarms for those.
6) Plan deployment, monitoring, drift detection, and retraining
- Deployment plan: blue/green or canary rollout, rollback strategy, feature gating.
- Monitoring: model performance (loss, accuracy), data distribution monitoring, latency/throughput, business KPIs.
- Drift detection: population vs. concept drift, statistical tests, shadow deployments to compare new vs. current models.
- Retraining strategy: scheduled vs. trigger-based retraining, incremental learning vs. full retrain, validation before promotion.
Interview tip: Discuss concrete thresholds or alerting logic you would use for automated retraining or human review.
Practice scenarios — what to rehearse
- Recommender systems: cold-start, personalization, ranking vs. candidate generation, online/offline features.
- Fraud detection: class imbalance, precision-vs-recall trade-offs, explainability for investigators, adversarial behavior.
- Imbalanced classification: sampling strategies, cost-sensitive learning, synthetic data (SMOTE), appropriate evaluation metrics.
Quick checklist to use in interviews
- Restate business goal and constraints
- Sketch data sources and pipeline
- Propose a model and justify it
- Outline training + serving architecture
- Pick business-aligned metrics and trade-offs
- Describe deployment, monitoring, and retraining
Mastering these six areas shows that you can design production-ready ML systems that are robust, scalable, and aligned with business needs. Practice speaking through each step, draw a simple architecture diagram, and be ready to justify any trade-offs.
If you'd like, I can convert this into a one-page interview cheat sheet or generate practice prompts (recsys, fraud, imbalance) to rehearse.
#MachineLearning #SystemDesign #DataScience

