
ML Interviews: Explain Deployment End-to-End to Prove Production Readiness

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
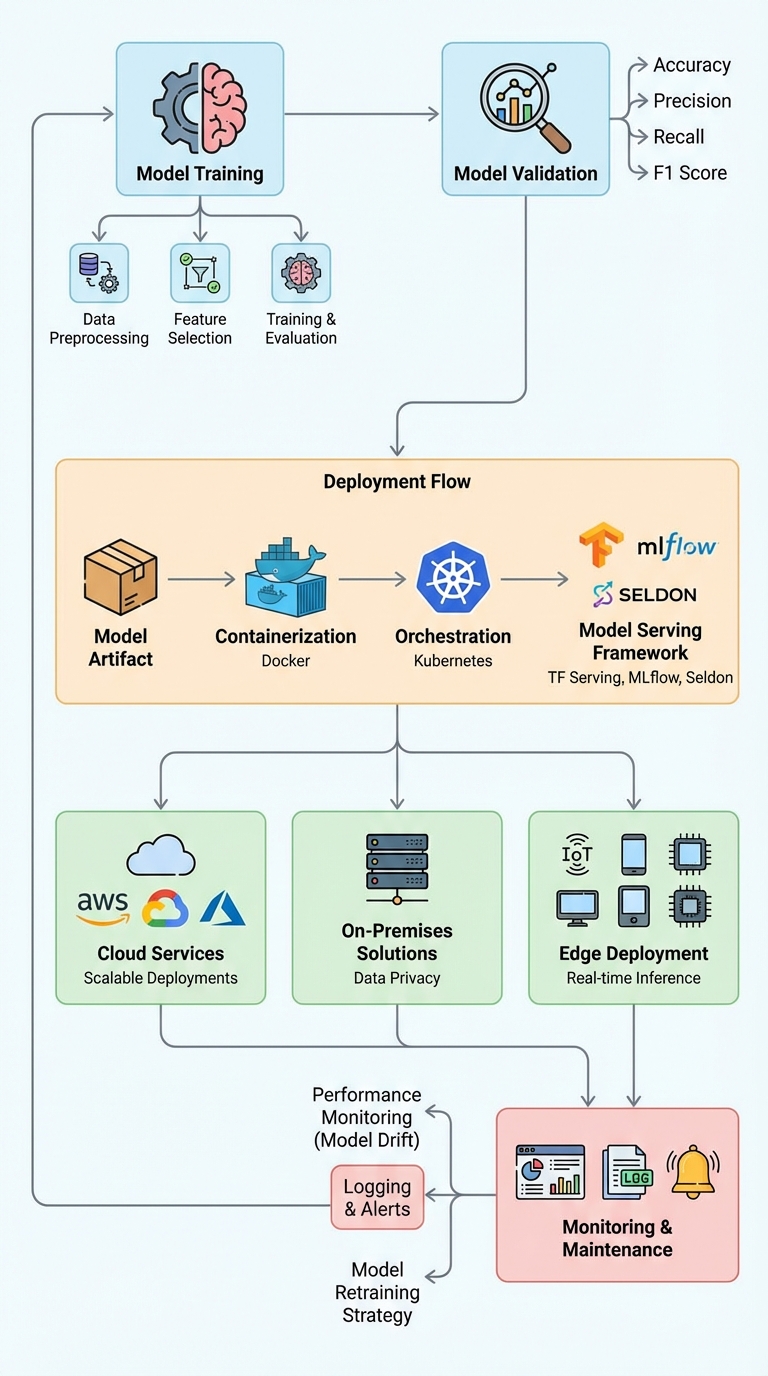 {style="max-width:800px;width:100%;height:auto;"}
{style="max-width:800px;width:100%;height:auto;"}
In ML interviews, "I trained a model" is only the beginning. To show you’re production-ready, walk the interviewer through the entire deployment lifecycle: how you validated the model, how you serve it, how you keep it healthy in production, and how you plan for incidents and improvement.
1. Start with training and validation
- Summarize the training dataset, preprocessing steps, and key validation metrics (e.g., accuracy, F1, AUC, precision/recall, calibration). Mention the business metric you optimized for.
- Explain cross-validation strategy, test set separation, and how you prevented leakage.
- If applicable, discuss uncertainty estimation (e.g., prediction intervals, MC dropout) and how you use it in serving.
2. Describe your serving strategy
Be explicit about the serving mode and why it fits the use case:
- Batch: periodic scoring for low-latency-insensitive use cases (e.g., nightly recommendations).
- Online / real-time: low-latency API for user-facing predictions.
- A/B / canary / shadow: compare new models to production or test in parallel without affecting users.
Give deployment patterns you’ve used (blue/green, canary, shadow) and trade-offs for each.
3. Name real environments and constraints
Call out concrete environments and constraints:
- Cloud (AWS/GCP/Azure) for managed infra and scalability.
- On-prem for data privacy, compliance, or low-latency local processing.
- Edge devices for ultra-low latency or offline operation.
Discuss networking, data locality, and privacy implications across those environments.
4. Be specific about tooling
Interviewers expect concrete tools and why you chose them:
- Reproducibility: Docker, Conda, or container images.
- Orchestration & scaling: Kubernetes, ECS, or serverless platforms.
- Model serving: TensorFlow Serving, TorchServe, Seldon, MLflow/MLflow Models, BentoML.
- CI/CD & pipelines: GitHub Actions, Jenkins, Argo CD, or Tekton for model deployments.
- Model registry & experiment tracking: MLflow, Weights & Biases, or a dedicated registry.
Mention IaC (Terraform) or config-as-code used to provision infra if relevant.
5. Show production maturity: monitoring, drift, and alerts
Explain how you keep models reliable:
- Monitoring: latency, throughput, error rates, and business KPIs tied to model performance.
- ML-specific metrics: prediction distribution, data drift (feature drift), concept drift, and model confidence.
- Observability: structured logs, distributed traces, and dashboards (Prometheus/Grafana, CloudWatch).
- Alerts & SLOs: when dashboards trigger incident playbooks.
- Retraining plan: automated retrain schedules, criteria for retrain (drift thresholds or KPI degradation), and rollback strategy.
Give examples: e.g., "If data drift exceeds threshold X, start offline validation; if business metric drops Y%, trigger a canary rollback."
6. Talk about versioning and reproducibility
- Model versioning: use a registry and immutable model artifacts; include hashed code + data references.
- Rollback: how you revert to a previous stable model (artifact + infra state).
- Reproducibility: store environments (Docker images), seed values, and training configs.
7. Be ready for scenario questions
Interviewers will probe with scenarios. Practice concise remediation plans:
- Performance drop: triage (input distribution → feature pipeline → model), compare recent cohorts, run shadow tests.
- Scalability issue: load testing, autoscaling rules, batching predictions, caching, or moving heavy preproc off the critical path.
- Corrupted inputs/latency spikes: input validation, graceful degradation, rate limiting, and circuit breakers.
- Versioning conflicts: verify model registry, rollback, and coordinate schema migrations.
Quick interview checklist
- State training & validation metrics and why they matter.
- Pick and justify a serving strategy (batch vs online vs A/B).
- Name environments (cloud/on‑prem/edge) and constraints.
- List exact tools you’d use (Docker, K8s, TF Serving, MLflow, etc.).
- Describe monitoring, drift detection, alerts, and retraining triggers.
- Explain versioning and rollback procedures.
Conclude by emphasizing that production readiness is about operationalizing the model lifecycle, not just achieving good offline metrics. If you can clearly explain deployment decisions, trade-offs, and incident plans, you’ll demonstrate the practical skills interviewers are testing.
#MachineLearning #MLOps #DataScience

