
Interview Trap: Accuracy Means Nothing If Your Multimodal System Can’t Hit Latency
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Interview Trap: Accuracy Means Nothing If Your Multimodal System Can’t Hit Latency
TL;DR — In cross-lingual, multimodal systems the real interview check is not the biggest transformer you can name, it’s a concrete serving plan that meets latency SLAs. Use large models offline for enrichment, lightweight models for real-time, add caching, autoscaling, and model optimizations like quantization or distillation.
Why accuracy alone won’t win the interview
Interviewers aren’t building a benchmark leaderboard — they’re building products. A model that achieves the highest F1 but times out at 2 seconds (or spikes to 5s at load) is a product failure. In real systems, tail latency, cost-per-inference, and reliability matter as much as raw accuracy. So when asked about architecture, don’t stop at “we’ll use XLM-R / CLIP” — show how you’ll serve it.
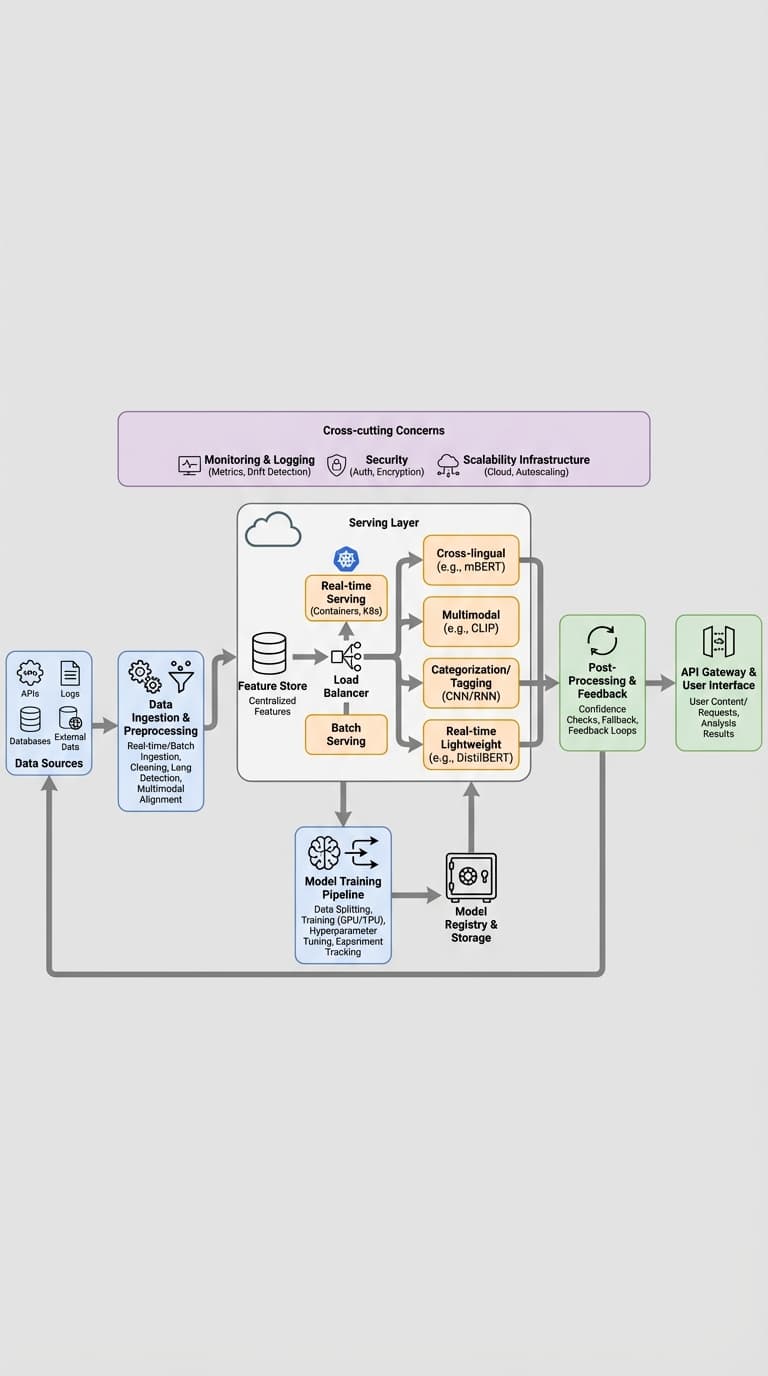
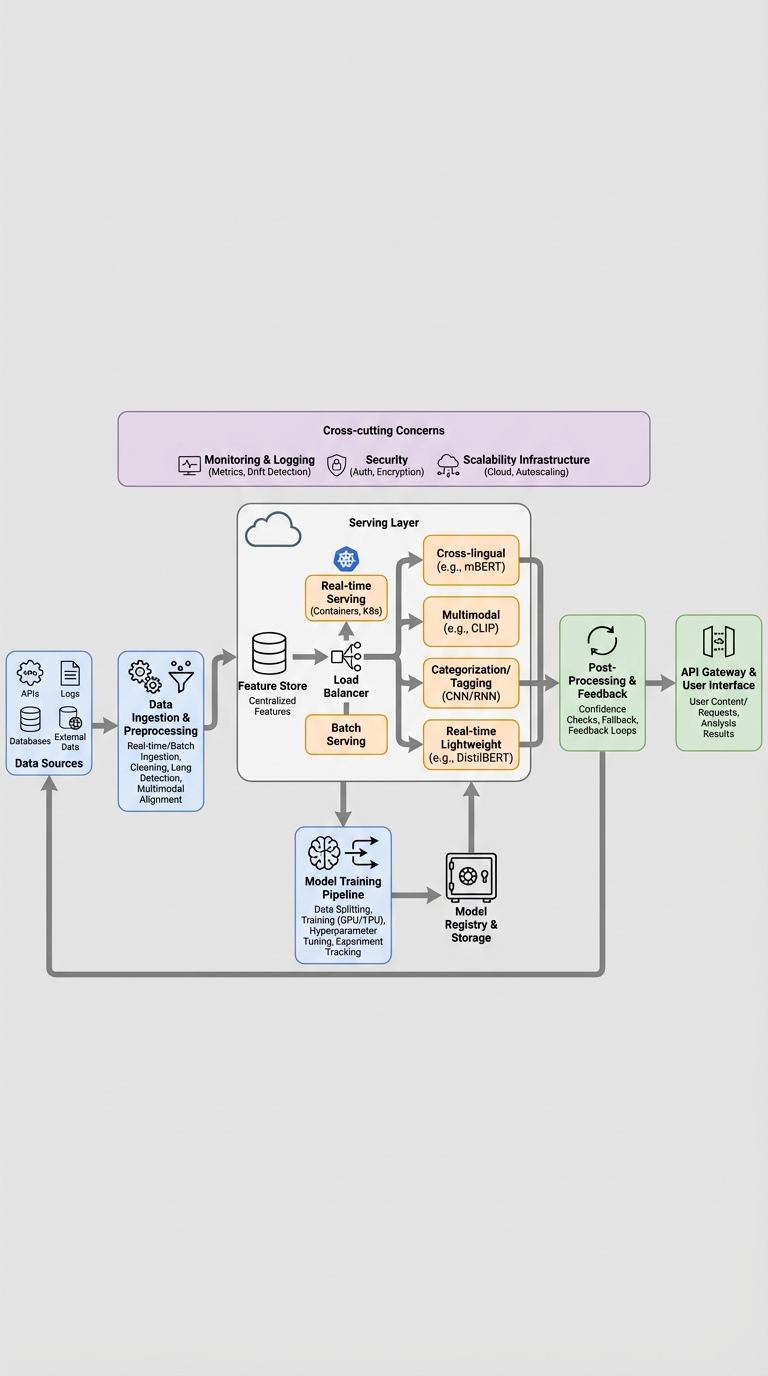
A clear serving plan (what interviewers want to hear)
Offline / batch enrichment with heavyweight models
- Use large models (XLM-R, CLIP, etc.) in offline pipelines to precompute expensive artifacts: embeddings, cross-modal similarity scores, translations, candidate generation, etc.
- Store results in a fast read store (vector DB like FAISS/Annoy, or Redis/Elasticsearch for metadata).
Lightweight models for real-time requests
- Serve distilled or compact models (DistilBERT, TinyBERT, mobile-sized CLIP variants) for on-path inference.
- Keep per-request compute under the SLA (e.g., 100–300 ms p95 for interactive features).
Caching
- Cache repeated content/responses (HTTP/CDN for static assets, Redis for dynamic inference outputs or embeddings).
- Use content hashing + TTLs and cache invalidation policies for freshness.
Autoscaling and resilience
- Autoscale inference workers (Kubernetes HPA, KEDA) and use queueing for bursts.
- Add circuit breakers and graceful degradation: fallback to cached or simpler rules if latency or errors spike.
Model optimization to cut inference cost
- Distillation to transfer knowledge from large offline models to fast online models.
- Quantization (INT8 or dynamic quantization) and pruning to reduce latency and memory.
- Use optimized runtimes (ONNX Runtime, TensorRT, TFLite) and batching where applicable.
Monitoring and SLOs
- Instrument latency (p50/p95/p99), error rates, and cost metrics.
- Alert on SLA breaches and have runbooks for rollbacks and traffic shaping.
Concrete architectural pattern (high-level)
- Ingest -> Offline Enrichment Service (heavy models) -> Embedding/Feature Store (FAISS, Redis, S3 metadata)
- Real-time API -> Lightweight Model Server -> Cache lookup -> Fallback to embeddings or simple heuristic
- Autoscaler + Queueing layer for spikes; Observability (Prometheus/Grafana) and tracing (Jaeger)
Extra engineering knobs (call these out in interviews)
- Precompute nearest-neighbor indices and update incrementally rather than rebuild frequently.
- Use async workers for non-blocking enrichment and background refreshing of cached items.
- Employ progressive rollouts and canarying when swapping models.
- Use hybrid search (ANN + metadata filters) to reduce candidate set before expensive rerank.
Example answer snippet for interviews
"I wouldn’t just say ‘use XLM-R and CLIP’. I’d propose a two-tiered design: run XLM-R/CLIP in offline pipelines to precompute embeddings and enrich content stored in a vector DB; serve requests with a distilled, quantized model (DistilBERT or small CLIP) that hits a 200–300 ms p95 SLA. Add Redis caching for hot items, autoscale inference pods, and monitor p99 latency with alerts. If the online model can’t keep up, fall back to cached results or a heuristic policy. This meets both accuracy (via offline enrichment) and latency SLOs."
Final note
Interviews test whether you can translate model research into reliable production systems. Accuracy is important, but without a believable serving plan that hits latency and cost targets, your design is incomplete. Be explicit about offline vs online roles, caching, autoscaling, and concrete model optimization techniques.

