
Hybrid Detection Wins Interviews: Rules for Speed, ML for the Unknown
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
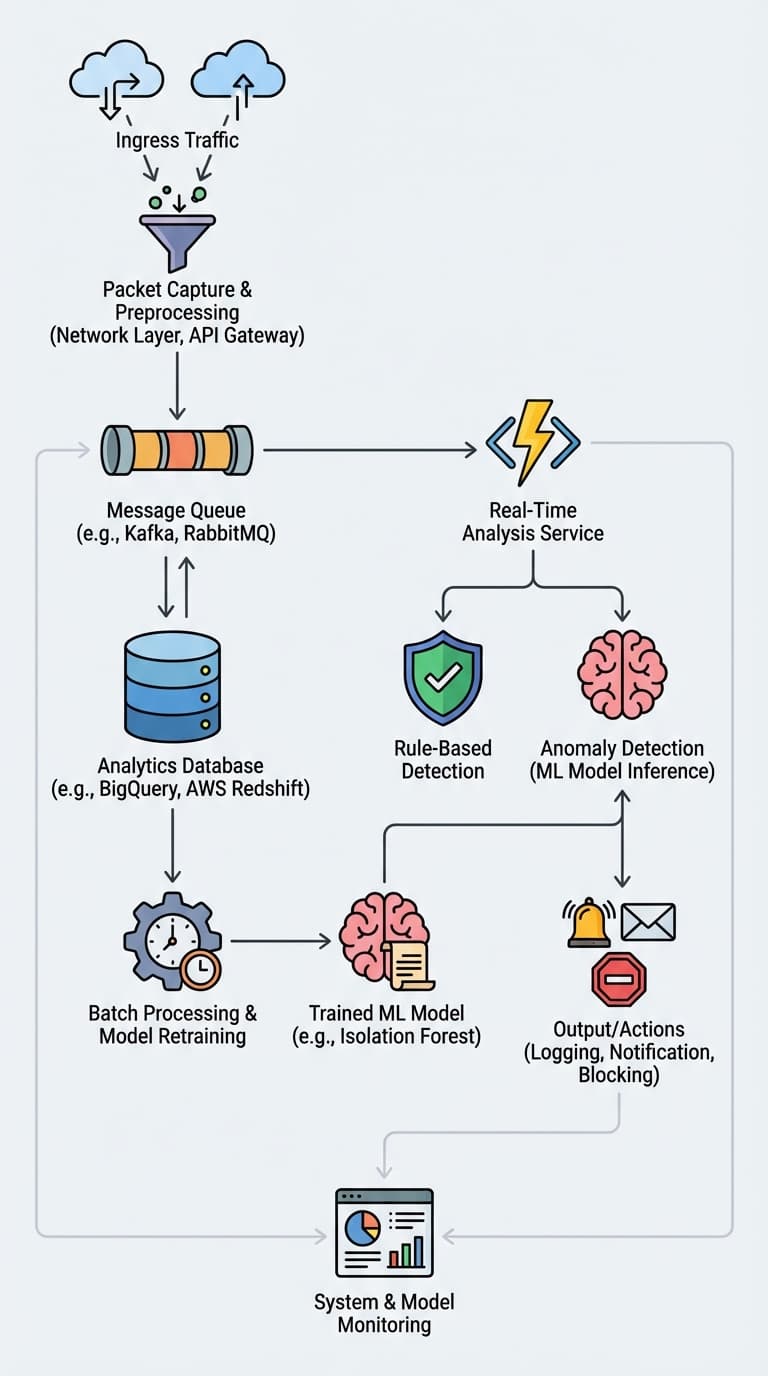
In threat-detection design interviews, the simplest answer that scores high is: use a hybrid approach — fast rule-based gates for known bad behavior, and anomaly-based machine learning to catch the novel stuff rules miss.
Below is a compact, interview-ready explanation and practical guidance you can use to describe the design.
The two-tier architecture (high level)
- First gate: Rule-based detection — low-latency checks that match known-bad IPs, signatures, protocol patterns, or blacklists. Fast to evaluate and easy to act on (block/flag). Keeps response time tight and reduces blast radius immediately.
- Second brain: Anomaly ML — models trained on normal ingress features (rate, packet size, ports, timing, request patterns) to surface novel or stealthy attacks that don’t match rules. Think of this as catching the unknown unknowns.
Explain this split in interviews succinctly: rules reduce immediate risk now; ML reduces future risk by detecting previously unseen patterns.
Rule-based detection — what to emphasize
- Purpose: deterministic, explainable, and extremely fast decisions.
- Examples: known malicious IPs, blacklisted domains, protocol anomalies, strict signature matches, geofencing, port/protocol mismatches.
- Benefits to call out: near-zero latency, easy to audit, immediate blocking, low CPU cost, simple scaling.
- Trade-offs: limited to known patterns; high maintenance for signatures and rules.
Anomaly ML — practical tips (Isolation Forest and alternatives)
- Model choice: Isolation Forest is a good, interview-friendly example for unsupervised anomaly detection. It isolates anomalies via tree partitioning and works well when labeled attack data is scarce.
- Useful features: ingress rate, bytes per connection, distinct destination ports, inter-event timing, session duration, protocol flags, entropy of payloads, failed-auth counts, user-agent patterns.
- Training approach: fit on a rolling window of ‘‘normal’’ traffic, validate with holdout windows, and continuously retrain to adapt to concept drift.
- Deployment: run scoring in a streaming pipeline with small windows or sample-based scoring to limit latency. Use ML to flag for further inspection or to raise risk scores rather than to block outright initially.
- Tuning & evaluation: monitor precision/recall, F1, false-positive rate, time-to-detection, and operational cost. Tune thresholds to balance alert volume and analyst capacity.
Latency & scaling considerations
- Rules: aim for microsecond–millisecond evaluation (in-line or just-in-time). Implement with optimized matching engines and simple lookups.
- ML scoring: can be slightly higher latency. Options: asynchronous scoring, sample-based scoring, or a two-path pipeline (fast rules in-line; ML scoring in parallel with alert enrichment).
- For high-throughput environments, consider streaming feature aggregation (e.g., windowed counts) and approximate algorithms to keep resource usage bounded.
How to present this in an interview (script)
"I’d design detection as a two-tier system: low-latency rule gates to immediately stop known threats, and an anomaly-detection layer (like an Isolation Forest trained on normal ingress features) to surface novel attacks. Rules keep response time tight and reduce risk instantly; the ML layer reduces future risk by finding patterns rules can’t name. I’d use the ML scores to prioritize and enrich alerts, retrain regularly for concept drift, and monitor precision/recall and time-to-detection to tune thresholds."
Quick checklist to mention
- Rule examples and where they run (in-line vs. async)
- ML model choice and feature set (ingress rate, size, timing, ports)
- Retraining cadence and drift handling
- Thresholding strategy and analyst feedback loop
- Metrics: precision, recall, FPR, time-to-detection
Closing
This hybrid framing shows you understand operational constraints (latency, scale, false positives) and modern detection completeness (rules + ML). It’s short, actionable, and interview-friendly.
#MachineLearning #CyberSecurity #DataEngineering

