
Health Checks: The One Detail That Makes Your Load Balancer “Real” in Interviews
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.

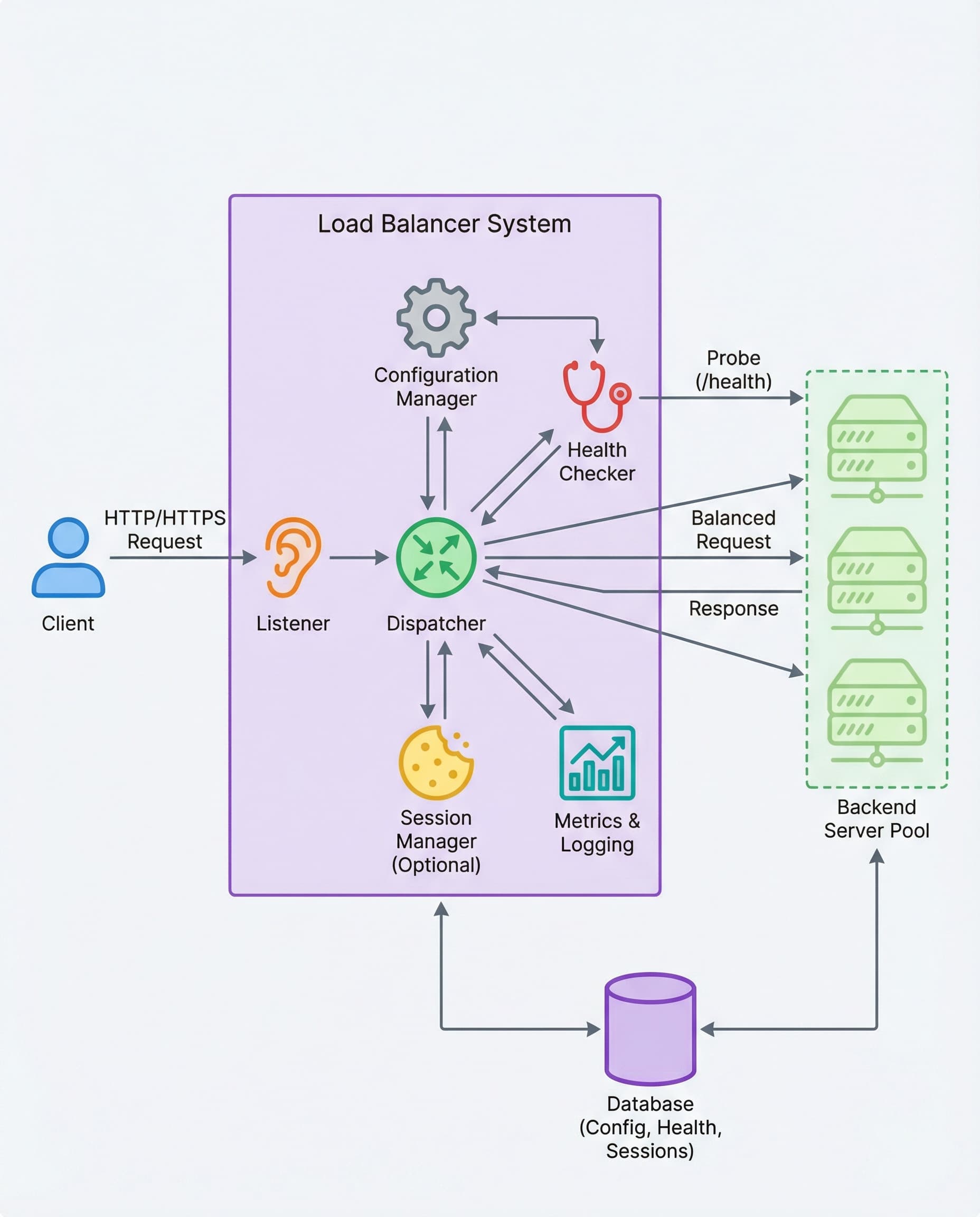
In a load balancer design, health checks are not a side feature — they decide whether your system is reliable.
Health checks are the small detail interviewers listen for. If you can’t prove a server is healthy, you should not route traffic to it. Skip this and your fancy load balancing becomes "round-robin-to-failure." Here’s a concise, interview-ready summary of what to implement and why.
Core principles
- Never route to a server you cannot currently trust. The dispatcher should only use a maintained "healthy set."
- Keep the routing decision in memory for speed, but persist health status for visibility, monitoring, and postmortems.
- Avoid flapping: use hysteresis (failure and success thresholds) so nodes aren’t rapidly toggled.
Recommended implementation (practical defaults)
- Probe endpoint: GET /health (or an equivalent lightweight check).
- Frequency: probe every 5–15 seconds (10s is a reasonable default).
- Failure threshold: mark unhealthy after N consecutive failures (N = 3 is common).
- Success threshold: re-admit after M consecutive successes (M = 2 or 3).
- Timeouts: keep the probe timeout shorter than your probe interval (e.g., 1–2s timeout for a 10s interval).
- Keep an in-memory healthy set for ultra-fast routing decisions; persist events to a datastore, logs, or metrics pipeline for visibility.
Simple pseudocode
on_probe_result(node, ok):
if ok:
node.fail_count = 0
node.success_count += 1
if node.status == UNHEALTHY and node.success_count >= success_threshold:
mark node HEALTHY
else:
node.success_count = 0
node.fail_count += 1
if node.status == HEALTHY and node.fail_count >= fail_threshold:
mark node UNHEALTHY
Persist a timestamped status change event and emit metrics (e.g., healthy/unhealthy counts, probe latencies).
Additional considerations and interview talking points
- Passive + active checks: combine probes (active) with passive failure detection (connection resets, high error rates) for faster reaction to real user failures.
- Connection draining: when marking a node unhealthy, stop sending new requests but allow existing connections to finish or be migrated.
- Backoff and probe throttling: after marked unhealthy, reduce probe frequency or use exponential backoff to avoid hammering a failing instance.
- Security: restrict /health so only the load balancer (or an authenticated probe) can call it; otherwise attackers might infer internal state.
- Scalability: probe fan-out can be expensive at large scale — consider hierarchical health checking (region-level probes) or offloading probes to agents on each host.
- Weighted routing and sticky sessions: health checks should influence weight adjustments and session rebalancing decisions.
Why persist health status?
In-memory decisions are fast (required for low-latency routing), but persistence gives you:
- Historical visibility for debugging and RCA
- Alerts when services degrade
- Metrics for SLO/SLA reporting
Persist status changes (not every probe line), with timestamps and reason codes.
How to talk about this in interviews
- State the defaults (probe endpoint, frequency, fail/success thresholds) and explain trade-offs (faster detection vs false positives).
- Mention hysteresis to avoid flapping and the importance of draining connections.
- Say you keep decisions in-memory for speed but persist events for monitoring and postmortem analysis.
- Bring up passive checks and security considerations if asked for deeper detail.
Conclusion
Health checks are the single detail that turns a conceptual load balancer into a production-ready system. Implement periodic probes, use hysteresis, keep fast in-memory routing decisions, and persist status for observability — and you’ll have a robust answer that wins interviews.
#SystemDesign #BackendEngineering #SRE

