
Fine-Tuning LLMs: Why Model Versioning Is Non‑Negotiable in System Design Interviews

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
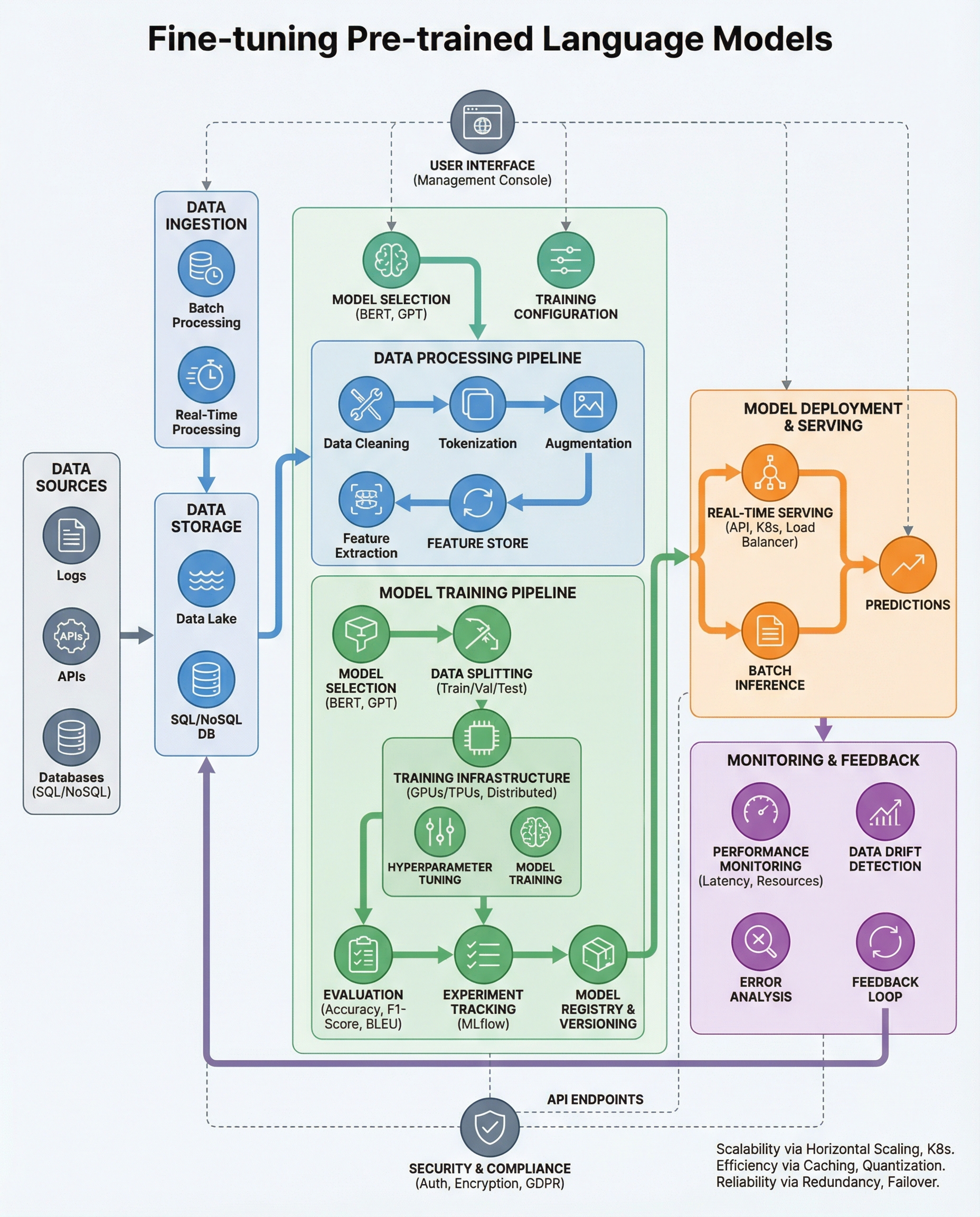
Fine-Tuning LLMs: Why Model Versioning Is Non‑Negotiable in System Design Interviews
When fine-tuning large language models, "version control" isn't a nice-to-have—it's fundamental. Without strict versioning and immutable records, your results aren't reproducible, releases can't be trusted, and A/B tests are meaningless.
Below is a concise, interview-ready explanation you can give, plus practical best practices to implement in real systems.
What you must log for every run
Treat each training run as an auditable artifact. At minimum, store:
- Base model identifier (e.g., model name + hash)
- Dataset snapshot (file paths + content hashes or dataset version)
- Preprocessing & tokenizer version (tokenizer config + code commit)
- Hyperparameters (learning rate, batch size, epochs, seeds)
- Code commit hash (exact repo commit or container image digest)
- Compute environment (Docker image, OS, library versions)
- Evaluation metrics and test harness (validation/test set seeds & scripts)
- Artifact location (trained model weights, tokenizer files, config)
These items let you reproduce a result, explain why Model B beat Model A, and roll back a bad release.
Why this matters
- Reproducibility: Exact inputs + code + environment = deterministic reruns.
- Explainability: Trace differences to a single changed artifact (data, tokenizer, hyperparam, etc.).
- Rollback & Safety: If a release regresses, you can redeploy a previously registered model.
- Reliable A/B testing: Compare identical conditions except the model under test.
- Compliance & auditability: Useful for governance and debugging production failures.
Interview tip: state concrete tools and a promotion flow
Don’t be vague. In interviews, name tools and describe the promotion flow. For example:
- Toolchain: "MLflow or Weights & Biases for tracking + an artifact store like S3/GCS + a model registry for promotion."
- Promotion flow: train → validate → register → deploy. Add canary/gradual rollout and monitoring in production.
You can expand: train (log run, store artifacts) → validate (automated tests, metrics threshold) → register (model registry with version and metadata) → deploy (CI/CD that pulls a registry version). Include automated rollback rules and monitoring (latency, errors, model drift).
Practical best practices checklist
- Snapshot datasets and store content hashes (don’t rely on dynamic pointers).
- Pin tokenizer and preprocessing code; publish tokenizer artifacts alongside weights.
- Always record RNG seeds and deterministic training settings where possible.
- Use immutable artifacts (S3 object with versioning, content-addressable storage).
- Use semantic versioning or model registry IDs (v1.2.0 or registry:1234).
- Keep evaluation harness in the repo and store the exact commit used for metrics.
- Automate CI gates (no model promotion without passing validation checks).
- Monitor post-deploy (quality metrics, drift, user feedback) and tie alerts to rollback.
One-liner to use in interviews
"Model versioning is mandatory: log base model, dataset snapshot, tokenizer/preprocessing, hyperparameters, code commit, and evaluation metrics. Use MLflow or W&B with an artifact store and follow train → validate → register → deploy with canary rollouts and monitoring."
Closing
Versioning transforms an LLM fine-tuning pipeline from a set of experiments into a reproducible, auditable, and production-ready system. In system design interviews, clarity about what you store and which tools you’d use separates theoretical answers from practical, deployable designs.
#MLOps #LLM #MachineLearning

