
Recommender Systems: How to Evaluate Them Like an Interview-Ready Engineer

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Recommender Systems: How to Evaluate Them Like an Interview-Ready Engineer
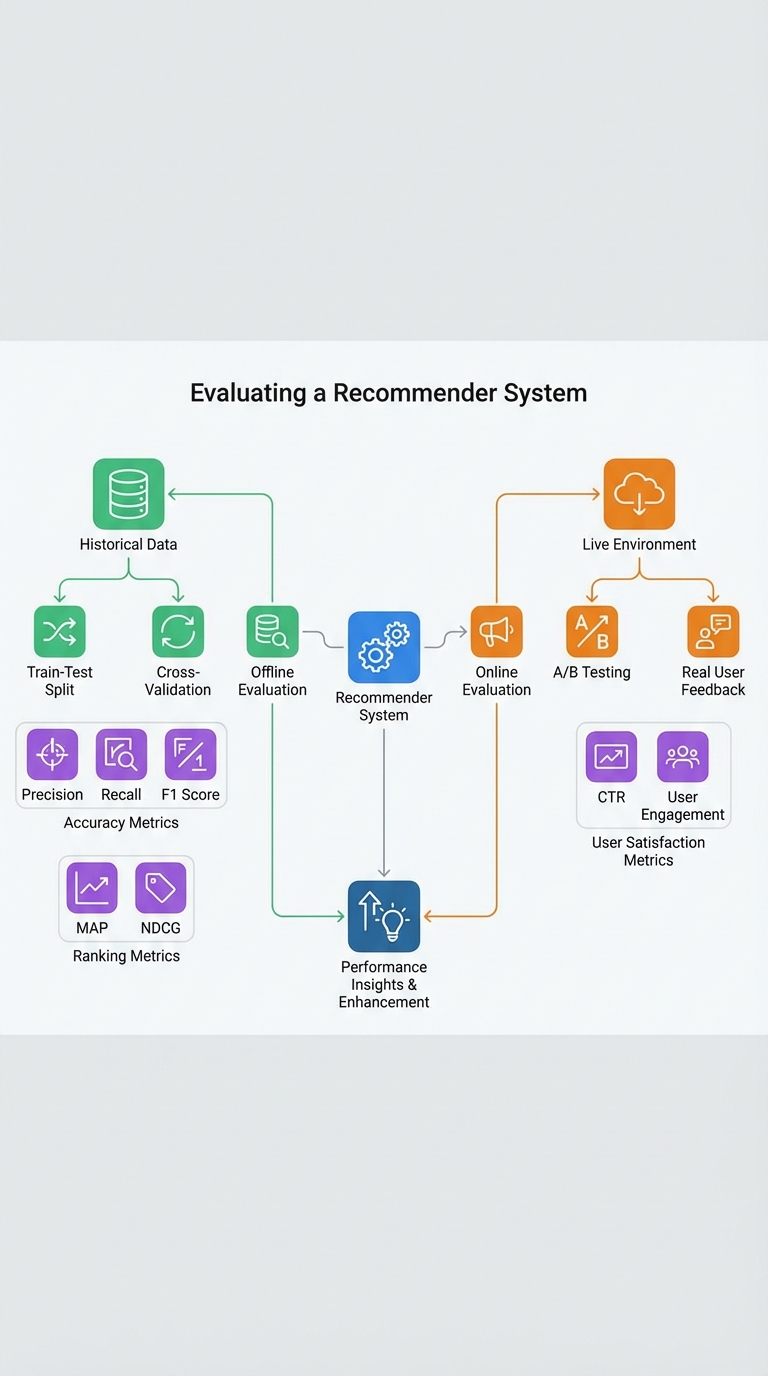
If you can't explain how to evaluate a recommender system, you don't fully understand it. Evaluating recommenders means choosing metrics that reflect user value, using protocols that avoid data leakage, and validating impact with real users. Below is a compact, interview-ready guide covering the right metrics, offline vs. online evaluation, common pitfalls, and a checklist you can cite in an interview.
Core metrics — what to use and why
- Precision@K: Of the top-K items recommended, how many are relevant? Good for measuring immediate recommendation quality.
- Recall@K: Of all relevant items for a user, how many did you retrieve in the top-K? Useful when finding most of the relevant pool matters.
- F1@K: Harmonic mean of Precision and Recall — use when you need a balance.
- MAP (Mean Average Precision): Aggregates precision at the ranks where relevant items occur — rewards correctly ranking several relevant items.
- NDCG (Normalized Discounted Cumulative Gain): Handles graded relevance and discounts lower-ranked hits — position matters.
- CTR (Click-Through Rate) and engagement metrics (time spent, conversions, repeat usage): Reflect real user value in production and capture downstream effects beyond relevance.
Tip: Always report metrics at relevant cutoffs (e.g., @5, @10). For recommendation lists, ranking-aware metrics (MAP, NDCG) are usually more informative than plain accuracy.
Offline evaluation: how to check generalization
- Train/test split: Use a holdout set to estimate generalization. Prefer time-aware (temporal) splits for sequential data to avoid peeking into the future.
- Cross-validation: Useful for small datasets, but be cautious with temporal dependencies.
- Negative sampling: When explicit negatives are absent, sample negatives carefully — ensure consistent sampling across models.
- Per-user evaluation: Compute metrics per user and aggregate (e.g., mean NDCG) to avoid popular-user bias.
- Prevent leakage: Ensure no interaction from the test period appears in training (exposure bias is common).
Offline evaluation is fast and necessary for iteration, but it’s a proxy — not the final word.
Online evaluation: validating real impact
- A/B testing: Randomize users to control and treatment, measure CTR, engagement, retention, and business KPIs.
- Statistical significance: Use proper hypothesis testing and track duration, sample size, and variance.
- Ramping and guardrails: Start small, monitor for adverse effects (e.g., increased clicks but decreased retention).
- Instrumentation: Log impressions, clicks, conversions, and contextual data (device, time, experiment id) to analyze results and segment performance.
Online experiments validate whether offline improvements translate to real user value.
Common pitfalls to avoid
- Using accuracy or RMSE on implicit feedback without proper framing — they often mislead for ranking tasks.
- Random holdouts that ignore temporal order — causes data leakage and optimistic estimates.
- Ignoring position and exposure bias — items users never saw can't be treated as negatives without correction.
- Evaluating only on aggregate metrics — models might perform differently for segments (new users, heavy users).
Interview-ready evaluation checklist
When asked how you would evaluate a recommender in an interview, you can structure your answer like this:
- Define success: pick metrics that match business goals (e.g., CTR, bookings, retention).
- Use ranking-aware offline metrics (NDCG, MAP) at relevant cutoffs and report per-user aggregates.
- Split data temporally and avoid leakage; handle negatives and exposure bias carefully.
- Run A/B tests to measure actual user impact and business KPIs; ensure statistical significance and monitoring.
- Watch for segment-specific performance and offline-online mismatches.
Example short answer: "I’d evaluate models offline with NDCG@10 and MAP, using a temporal holdout to avoid leakage and per-user averages. Then I’d validate improvements in production with an A/B test tracking CTR, engagement, and retention, ensuring significance and monitoring segment behavior."
Quick takeaways
- Choose metrics that reflect user/business value — position matters in ranking tasks.
- Offline evaluation is for iteration; online experiments are for validation.
- Avoid data leakage and account for exposure/censoring bias.
- Be ready to argue why your chosen metric and evaluation protocol align to the product goal.
Mastering these concepts will let you evaluate recommenders confidently and explain your approach concisely in interviews.

