
ETL vs ELT: The Interview Question That Exposes Real Data Engineering Skill

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
ETL vs ELT: The Interview Question That Exposes Real Data Engineering Skill
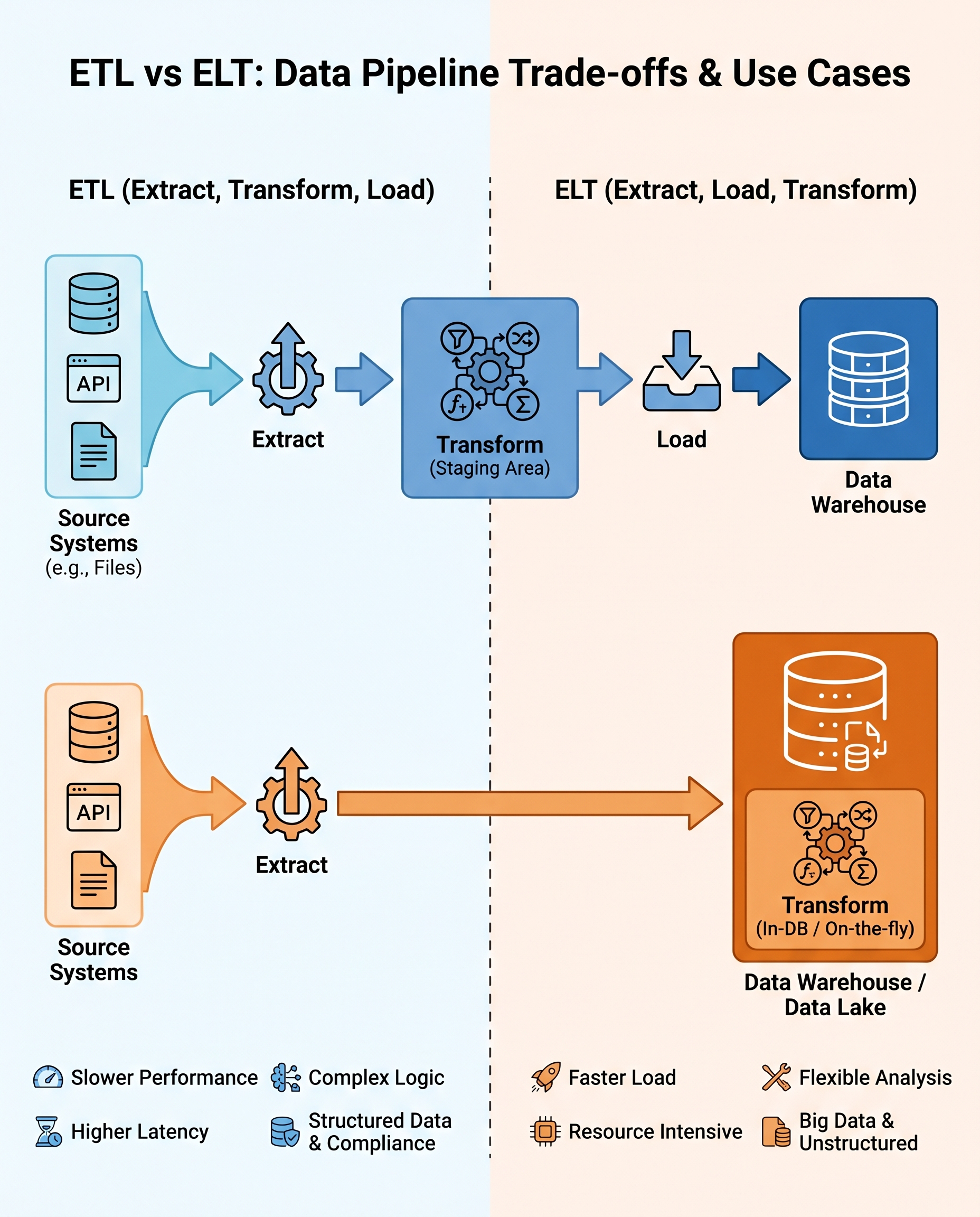
Data engineers are frequently asked to pick between ETL (Extract → Transform → Load) and ELT (Extract → Load → Transform). The right answer isn't just a label — it's a rationale that shows you understand trade-offs, constraints, and system design.
Below is a compact, interview-ready guide that explains both patterns, their pros and cons, the decision criteria you should use, and a short sample answer you can adapt in an interview.
What they mean
- ETL (Extract → Transform → Load): data is transformed before it is loaded into the data warehouse. Good for enforcing consistent schemas, data quality, and compliance up front.
- ELT (Extract → Load → Transform): raw data is loaded first; transformations happen inside the warehouse or compute layer after ingestion. Enables faster access and flexible analytics using the warehouse's compute.
Pros and cons — quick summary
ETL:
- Pros: strong upfront data quality, deterministic schemas, easier to enforce governance/compliance, fewer surprises for downstream consumers.
- Cons: adds latency (transform before load), can complicate pipelines, upstream compute and orchestration burden.
ELT:
- Pros: faster time-to-availability, simpler ingestion, flexible ad hoc analytics, leverages elastic warehouse compute (e.g., Snowflake, BigQuery).
- Cons: can increase warehouse compute costs, potential for messy raw data if governance is weak, late discovery of data quality issues.
Key decision factors (what to justify in an interview)
- Data volume and velocity: very large volumes or streaming may favor ELT with scalable warehouse compute or purpose-built streaming pre-processing.
- SLA / latency requirements: strict low-latency or real-time SLAs might require lightweight transforms upstream or streaming ETL tooling.
- Transformation complexity: heavy, complex joins or CPU-bound transforms may be cheaper to do in a distributed processing engine (Spark) before loading.
- Governance & compliance: if you must enforce data quality, PII masking, or regulatory checks before storage, ETL is safer.
- Cost model: consider where compute is cheapest — on your cluster (ETL) or the warehouse (ELT). Warehouse compute can be more expensive at scale.
- Team skills & tooling: if the team knows dbt and the warehouse supports SQL transformations, ELT + dbt is attractive. If you have mature upstream pipelines and Spark expertise, ETL may be preferred.
- Observability & reproducibility: ETL gives easier provenance of transformed artifacts; ELT requires strong testing and versioned transformations (dbt, CI/CD) to reach parity.
Interview strategy — how to answer
- Restate constraints: "Tell me about data volume, SLA, transformation complexity, and governance requirements." This shows you know the right questions.
- Pick a primary dimension (e.g., latency or governance) and explain how it drives the choice.
- Mention hybrid options and tooling: sometimes upstream light transforms + ELT for heavier analytics is best.
- Give a concise recommendation and trade-offs.
Sample concise interview answer:
"If our primary requirement is strict compliance and deterministic schemas before anyone can access the data, I'd choose ETL so transformation and masking happen upstream. If we need rapid access to raw events for exploratory analytics and can rely on warehouse governance and tools like dbt for reproducible transformations, I'd choose ELT. For very large batch transforms that are compute-heavy, I'd run them in a distributed engine before loading. In practice I often implement a hybrid: lightweight, mandatory cleansing upstream, then ELT-based analytical transforms inside the warehouse."
Quick checklist for decision-making
- Is immediate data access more important than pre-enforced data quality? (ELT if yes)
- Are there regulatory/data privacy rules that require pre-load processing? (ETL if yes)
- Will transformations be heavy/compute-intense? (Consider ETL or separate batch processing)
- Do we have a modern warehouse and SQL-based transformation tooling (dbt)? (ELT advantage)
- What is the expected cost profile and where is compute cheapest? (Compare warehouse vs cluster)
Closing
There is no absolute "best" — the strongest interview answers show that you can weigh constraints, choose pragmatically, and explain trade-offs. Mention hybrid patterns and tooling (dbt, Airflow, Spark, Fivetran, Snowflake/BigQuery/Redshift) to demonstrate practical experience.
Hashtags: #DataEngineering #ETL #ELT

